Analyse af tid-til-event data i store kohorte studier analyseret med SAS/STAT
|
|
|
- Stig Ravn
- 8 år siden
- Visninger:
Transkript
1 Analyse af tid-til-event data i store kohorte studier analyseret med SAS/STAT Jacob Simonsen, Afdeling for Epidemiologisk Forskning Statens Serum Institut

2 Register baseret forskning Kendetegn: Baseret på landsdækkende registre, derfor store datasæt Udfald er oftest binære eller tid-til-event Prædefinerede og veldefinerede statistiske hypoteser Centralpersonregistret Psykiatriskregistret Analyse data Landspatientregistret Patalogiregistret Lægemiddelregistret Sygesikringsregistret Lægemiddelregistret Cancerregistret

3 Tid til event modeller (overlevelses analyse) I disse analyser gælder det om at finde sammenhænge mellem forklarende faktorer og tid-til-event. Tiderne kan være censoreret, dvs for nogle observationer kendes kun en nedre grænse. Kan skyldes studietids ophør. Og observationer kan være venstre trunkeret, dvs med forsinket entry. Tid

4 Procedurer specialiseret til overlevelses analyse Rate modeller: l(t)=f(xb) PROC PHREG PROC ICPHREG PROC SURVEYPHREG Accelerated Failure time models: E(T)=f(Xb) PROC LIFEREG Ikke-parametriske analyser: Kaplan Meier kurver, Log rank test, etc PROC LIFETEST PROC ICLIFETEST Percentil regression: fx Median(T)=Xb PROC QUANTLIFE
=Xb PROC")
5 Generelle procedure der også finder anvendelse i overlevelses analyser Generaliserede lineære modeller PROC GENMOD PROC GLIMMIX PROC HPGENSELECT Ikke lineære modeller PROC HPNLMOD PROC NLMIXED

6 Rate modeller Her konstrueres modeller for raten (groft sagt: rate= 1 ) tid til event Mest populære rate modelle er Poisson regression (fuld parametrisk model): l(t)=e X(t)b, X(t) er stykvise konstant Cox regression (semi parametrisk model): l(t)=e X(t)b l 0 (t), hvor l 0 (t) er en baggrundsrate Mindre populært, men langt mere generel er Lin-Yings model: l(t)=g(x(t)b) + h(z(t)g) l 0 (t)
=g(x(t)b) +")
7 Poisson regression Man kan nøjes med at regne på aggregerede persontider og events i kombinationer af forklarende faktorer: Person ID Data på individ niveau Køn Eksponeret Alder Start Slut Event 1 Mand Nej Jan Jan Mand Nej Jan Dec Man Ja Dec Dec 86 1 Aggregeret data Alder Køn Eksponeret Personår Events Mand Ja Mand Nej Kvinde Ja Kvinde Nej Med flere tidsafhænge faktorer er det et besværligt tælle-arbejde at danne det aggregerede data Heldigvis findes %stratify-makroen 1 der udfører arbejdet. 1) Rostgaard K. Methods for stratification of person-time and events a prerequisite for Poisson regression and SIR estimation. Epidemiologic Perspectives & Innovations : EP+I. 2008;5:7. doi: /
 Rostgaard K.")
8 Likelihood-funktionen får en form magen til Poisson fordelte data s likelihood funktion. Derfor kan procedurer til generaliserede lineære modeller benyttes. PROC HPGENSELECT data=aggregeret; CLASS alder koen eksponering; MODEL events=alder koen eksponering/dist=poisson LINK=LOG offset=logpersontid; RUN; PROC HPGENSELECT er en multi-kerne procedure. Hurtig på store datasæt med mange forklarende variable. Til gengæld har PROC GENMOD flere features end HPGENSELECT (fx REPEATED der tillader stokastisk afhængige observationer). Beregningstiden er proportional med antal kombinationer af forklarende variable.

9 Inden analyse skal data opstilles på formen Cox-regression Person ID Eksponeret Start (alder) Slut (alder) event 1 Nej Nej Ja 57 57½ 1 Bemærk, der er ikke en alder-klasse-variabel. Til gengæld siger start og slut hvornår personen indgår i analysen. Man kan selvfølgelig vælge en andent tidsakse en alder. Data kan nu analyseres med PROC PHREG...

10 Estimering i Cox-regression med PROC PHREG PHREG anno 2002: PROC PHREG data=mydata; MODEL (entry exit)*event(0)=kon medicin; RUN; PHREG anno 2015: PROC PHREG data=mydata fast; CLASS kon medicin(ref= placebo ) site; MODEL (entry exit)*event(0)=kon medicin/eventcode=1; RANDOM site; ASSESS PROPORTIONALHAZARDS; WEIGHT myweight; RUN; Optimering af hastighed Ved venstre trunkerede data SAS/STAT 14.1 (9.4 M3) Multiple event typer. SAS/STAT 13.1 (SAS 9.4 M1) Class statement (fra version 9.2) Tillader stokastisk afhængige data SAS/STAT 9.3 Goodness of fit SAS 9.2 Vægte smart ved aggregering SAS/STAT 13.2 (9.4 M2)
 Class statement (fra version 9.2) Tillader stokastisk afhængige data SAS/STAT 9.3 Goodness of fit SAS 9.")
11 Aggregering i Cox-regression I Cox regression er det tilstrækkeligt at vide hvor mange der er i risiko og antal døde på hvert riskset riskset Tid Eksponeret Riskset Tid (målt i alder) dummytid Antal Der findes SAS-makroer til dannelse af det aggregerede datasæt. %coxaggregate(data=,entry=,exit=,covariate=..) Nej Nej Ja Nej Ja Ja PROC PHREG data=aggregated; CLASS eksponeret; MODEL dummytime*dummytime(2)= eksponeret; WEIGHT antal; STRATA riskset; RUN;
 Nej 54 1 1 Nej 54 2 9 Ja 54 2 10 Nej 57 2 9 Ja 57 1 1 Ja 57 2 9 PROC PHREG data=aggregated; CLASS eksponeret; MODEL")
12 Cox regression med tidsafhængie faktorer Uden aggregering: Her tillades eksponerings-effekteen at ændre værdi ved fx tid=10. Eksponerings effekten kan splittes således: PROC PHREG data=ikke_aggregeret_data; tidlig=(eksponeret= yes )*(tid<=10); sen=(eksponeret= yes )*(tid>10); MODEL tid*event(0)=tidlig sen; RUN; Dette give desværre en beregningstid der er kvadratisk med antal individer. Med? λ aggregering 0.8 Aggregeringen gør det muligt at definere en tidsmarkør i et datastep. Herefter modelleres tidsafhængigheden som en interaktion: %coxaggregate(data=,entry=,exit=,covariate=..) 0.7 Data aggregated; 0.6 set aggregated; if (riskset_tid<=10) then tid2= tidlig ; 0.5 else tid2= sen ; Run; 0.4 PROC PHREG data=aggregated; 0.3 CLASS eksponeret tid2/param=glm; 0.2 MODEL dummytime*dummytime(2)= eksponeret*tid2; WEIGHT antal; 0.1 STRATA riskset; hazardratio eksponeret/at(tid2=all); RUN; Dette reducere beregningstiden til at være lineær afhængig af antal individer. Eksponeret Ueksponeret Tid
 0.7 Data aggregated; 0.6 set aggregated; if (riskset_tid<=10) then tid2= tidlig ; 0.")
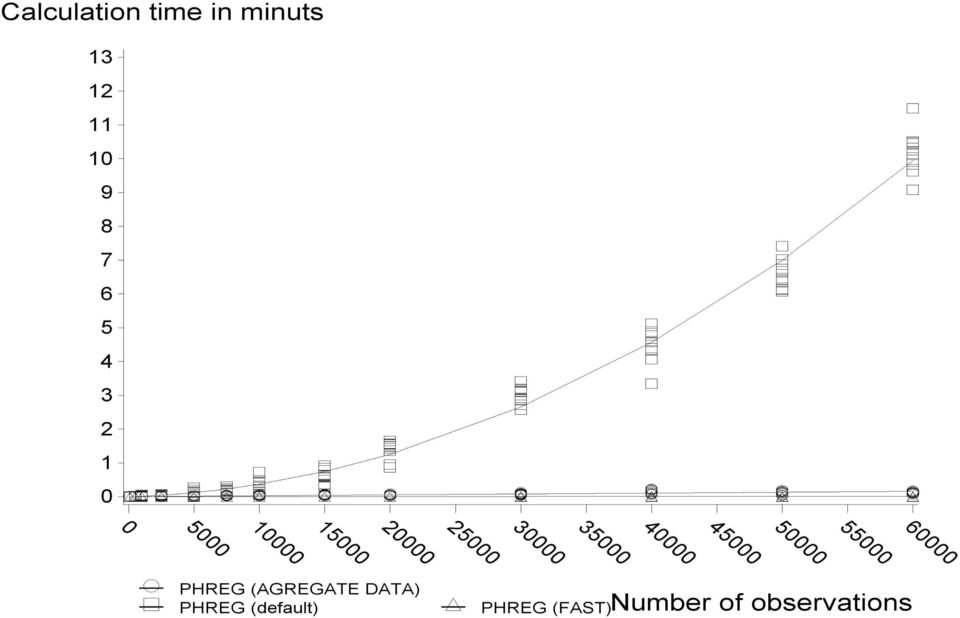
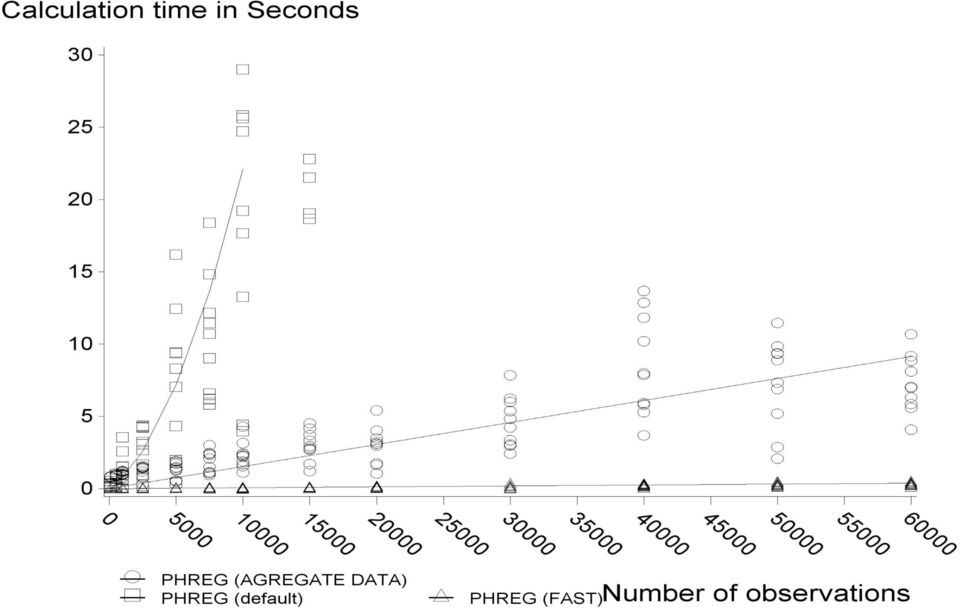
13 Beregningstid i Cox-regression n=antal individer. Venstre-trunkering Tidsafhængige faktorer Beregningstid uden aggregering Beregningstid Med aggregering Nej Nej O(n) O(n) Nej Ja O(n 2 ) O(n) Ja Nej O(n 2 ) eller O(n) med FAST option O(n) Ja Ja O(n 2 ) O(n)
 O(n) Ja Nej O(n 2 ) eller O(n) med FAST option O(n)")
14
15
16 Lin Yings Ikke lineære model Lad os forestille os at raten formen l(t)=g(xb) + h(xa) l 0 (t) b og a er parametre, der skal estimeres. X og Z er vektorer med forklarende variable l 0 (t) er en baggrundsrate (parametrisk eller ikke-parametrisk). g og h er selvvalgte link-funtioner. En ekstrem fleksibel model! Modellen tillader additive komponenter, g(xb), som udtrykker rate-differencer og multiplikative komponenter, h(za), som udtrykker rate-ratioer.

17 Estimering med parametrisk baggrundsrate Antag modellen l(t)=g(xb) + h(za) l 0 (t) Med fx g(x)=x og h(x)=e x, og at baggrundsraten fx har formen: l 0 (t)= k r t r k 1. Estimering foretages ved maksimere log-likelihood-funktionen. Hver observation har et bidrag på formen t exit l i (b,g,s)=1 event log(l i (t))- tentry l i (s) ds, som er et rent parametrisk udtryk.
=1 event log(l i (t))- tentry l")
18 Bidraget til likelihood-funktionen kan programmeres ind i HPNLMOD: PROC HPNLMOD DATA=simulation ; lambda=beta1*w1+exp(gamma1*x1)*(k/r)*(t/r)**(k-1) integrale=t*beta1*w1+exp(gamma1*x1)*(t/r)**k likelihood=event*log(lambda)-integrale; BOUNDS k r>0; MODEL t ~ GENERAL (likelihood); RUN; Chancerne for konvergens øges hvis man har et fornuftigt bud på startværdier parameters beta gamma1 0.5 k 1 r 1; Har man tilfældige effekter i modellen kan man benytte sig af PROC NLMIXED.

19 Estimering med ikke-parametrisk baggrundsrate l i (t)=g(x i b) + h(z i a) l 0 (t) Nu antages ikke nogen parametrisk form på l 0 (t). Modellen er derfor mere fleksibel på trods af færre parametre. Parametrene kan estimeres ved at løse et sæt estimerings ligninger (Se Lin-Yings artikel for den præcise form 1 ): F b, g = 0 t f a, b, data s dm i (s) = 0. Generelt kan dette ikke opstilles som et maksimerings problem. - PROC HPNLMOD eller nogen anden procedure virker derfor ikke hér. Heldigvis kan alt løses i SAS/BASE (kræver dog lidt arbejde ) 1 Lin, D. Y.; Ying, Zhiliang. Semiparametric Analysis of General Additive-Multiplicative Hazard Models for Counting Processes. Ann. Statist. 23 (1995), no. 5, doi: /aos/
 1 Lin, D. Y.; Ying, Zhiliang. Semiparametric Analysis of General Additive-Multiplicative Hazard Models for Counting Processes. Ann.")
20 Numerisk løsning til estimerings ligningen F b, g = 0 t f a, b, data s dm i (s) = 0 Kan løses med Newton Raphsons algoritme δ F θ i = θ i 1 δ θ (θ i 1) F θ i 1, Hvor θ er hele parameter vektoren θ = a b. Dvs, vælg passende startværdi θ 0 og iterér indtil der er konvergens. 1

21 Sådan kan en Newton-Raphson algoritme implementeres i et datastep Proc sort data=mydata; by t; Run; Data estimater; /***initialiser parametre****/ array parameters{&dimension.,1} _temporary_; array afledte{&dimension.,&dimension.} _temporary_; do until (konvergens=1); ***sæt integrand og afledte til 0****; do i=1 to nobs; set mydata point=i; ****opdater hjælpevariable end; ****Udregn F(q) og df(q)/dq ****Newton Rapson opdatering af parametre; *** if (parameterændring<delta) then konvergens=1;***; end; keep parametre; Run; Parametre og afledte erklæres i 2x2 arrays; Newton-Raphson algoritme Datasættet løbes igennem, Hvorved integralet og dens afledte bliver løst 1 δ F θ i = θ i 1 F θ δ θ (Mere om matrix-operationer på næste slide) Algoritmen stoppes når Der er opnået konvergens
22 Matrix funktioner Tilsvarende med andre matrix funktioner (addér, multiplicér osv.). Matrix-funktioner kan ikke kaldes direkte fra et datastep, men de kan gøres (permanent) tilgængelige via PROC FCMP således.. option cmplib=function.func; libname function 'd:\sasdata\sasfunctions'; proc fcmp outlib=function.func.matrix; subroutine invers(m[*,*],inv[*,*]); outargs m,inv; call inv(m,inv); endsub; run; Herefter funktionen kaldes fra datastep: array A{4,4} _temporary_; array B{4,4} _temporary_; call invers(a,b);
23 PROC FCMP kan også bruges til at definere de to link-funktioner proc fcmp outlib=work.function.gh; function g(x); y=x; return (y); endsub; function h(x); y=exp(x); return (y); endsub; run; På samme måde skal 1. og 2. afledte af g og h defineres.
24 Hvis estimerings-datasteppet pakkes ind i en makro, %macro lin_ying(data,model ); %mend; så skal brugeren kun definere link-funktioner g og h (og afledte) med PROC FCMP, og derefter kalde makroen %lin_ying(data=simulation, )
25 Eksempel simulerede levetider, med en rate på formen l(t)= xb + e za l 0 (t), hvor baggrundsraten er l 0 (t)= k r t r k 1, (dvs en Weibull form) Link-funktionerne er g(x)=x, og h(x)=e x z og x er binære (0 eller 1), b=0.25 a=0.25
26 Eksempel fortsat Sammenligning mellem makro og PROC HPNLMOD Begge giver gode estimater hvis modellen er specificeret korrekt Sande værdi PROC HPNLMOD Parametrisk model Lin-Ying makro Semi-parametrisk model b ( std err) (0.0022) a (0.0107) (0.0125) Beregningstid (real) 5.0 sec 7:08.92 Beregningstid (CPU) 1: :09:21 PROC HPNLMOD er (meget) hurtigere end makroen. Lin-Ying makroen har dog lineær beregningstid. HPNLMOD kræver en fuld-parametrisk model. Dvs flere model-antagelser, hvilket kan medføre bias. Makroen er mindre følsom over for valg af start værdier, da den semi-parametriske baggrundsrate sikrer pænt fit fra start. -Hvorimod de potentielt mange parametre i en fuld-parametrisk model gør valg af startværdier svær/umulig.

27 Slut
Morten Frydenberg Biostatistik version dato:
 Caerphilly studiet Design og Data Biostatistik uge 14 mandag Morten Frydenberg, Afdeling for Biostatistik Poisson regression En primær tidsakse og ikke stykkevise konstante rater Cox proportional hazard
Caerphilly studiet Design og Data Biostatistik uge 14 mandag Morten Frydenberg, Afdeling for Biostatistik Poisson regression En primær tidsakse og ikke stykkevise konstante rater Cox proportional hazard
Dag 6: Interaktion. Overlevelsesanalyse
 Dag 6: Interaktion. Overlevelsesanalyse How does CHD depend on gender and hypertension? Males: hypertension chd01 Females: Frequency Row Pct 0 1 Total ---------+--------+--------+ 0 352 95 447 78.75 21.25
Dag 6: Interaktion. Overlevelsesanalyse How does CHD depend on gender and hypertension? Males: hypertension chd01 Females: Frequency Row Pct 0 1 Total ---------+--------+--------+ 0 352 95 447 78.75 21.25
Introduktion til GLIMMIX
 Introduktion til GLIMMIX Af Jens Dick-Nielsen jens.dick-nielsen@haxholdt-company.com 21.08.2008 Proc GLIMMIX GLIMMIX kan bruges til modeller, hvor de enkelte observationer ikke nødvendigvis er uafhængige.
Introduktion til GLIMMIX Af Jens Dick-Nielsen jens.dick-nielsen@haxholdt-company.com 21.08.2008 Proc GLIMMIX GLIMMIX kan bruges til modeller, hvor de enkelte observationer ikke nødvendigvis er uafhængige.
Adgangsgivende eksamen (udeladt kategori: Matematisk student med matematik på niveau A)
") Økonometri 1 Forår 2003 Ugeseddel 13 Program for øvelserne: Gruppearbejde Opsamling af gruppearbejdet og introduktion af SAS SAS-øvelser i computerkælderen Øvelsesopgave 6: Hvem består første årsprøve
Økonometri 1 Forår 2003 Ugeseddel 13 Program for øvelserne: Gruppearbejde Opsamling af gruppearbejdet og introduktion af SAS SAS-øvelser i computerkælderen Øvelsesopgave 6: Hvem består første årsprøve
Man indlæser en såkaldt frequency-table i SAS ved følgende kommandoer:
 1 IHD-Lexis 1.1 Spørgsmål 1 Man indlæser en såkaldt frequency-table i SAS ved følgende kommandoer: data ihdfreq; input eksp alder pyrs cases; lpyrs=log(pyrs); cards; 0 2 346.87 2 0 1 979.34 12 0 0 699.14
1 IHD-Lexis 1.1 Spørgsmål 1 Man indlæser en såkaldt frequency-table i SAS ved følgende kommandoer: data ihdfreq; input eksp alder pyrs cases; lpyrs=log(pyrs); cards; 0 2 346.87 2 0 1 979.34 12 0 0 699.14
Lineær og logistisk regression
 Faculty of Health Sciences Lineær og logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Dagens program Lineær regression
Faculty of Health Sciences Lineær og logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Dagens program Lineær regression
Note om Monte Carlo eksperimenter
 Note om Monte Carlo eksperimenter Mette Ejrnæs og Hans Christian Kongsted Økonomisk Institut, Københavns Universitet 9. september 003 Denne note er skrevet til kurset Økonometri på. årsprøve af polit-studiet.
Note om Monte Carlo eksperimenter Mette Ejrnæs og Hans Christian Kongsted Økonomisk Institut, Københavns Universitet 9. september 003 Denne note er skrevet til kurset Økonometri på. årsprøve af polit-studiet.
Faculty of Health Sciences. Basal Statistik. Overlevelsesanalyse. Lene Theil Skovgaard. 12. marts 2018
 Faculty of Health Sciences Basal Statistik Overlevelsesanalyse Lene Theil Skovgaard 12. marts 2018 1 / 12 APPENDIX vedr. SPSS svarende til diverse slides: Kaplan-Meier kurver, s. 3 Kumulerede incidenser
Faculty of Health Sciences Basal Statistik Overlevelsesanalyse Lene Theil Skovgaard 12. marts 2018 1 / 12 APPENDIX vedr. SPSS svarende til diverse slides: Kaplan-Meier kurver, s. 3 Kumulerede incidenser
Program. Modelkontrol og prædiktion. Multiple sammenligninger. Opgave 5.2: fosforkoncentration
 Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: ekstrom@life.ku.dk Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: ekstrom@life.ku.dk Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
Vi vil analysere effekten af rygning og alkohol på chancen for at blive gravid ved at benytte forskellige Cox regressions modeller.
 Løsning til øvelse i TTP dag 3 Denne øvelse omhandler tid til graviditet. Et studie vedrørende tid til graviditet (Time To Pregnancy = TTP) inkluderede 423 par i alderen 20-35 år. Parrene blev fulgt i
Løsning til øvelse i TTP dag 3 Denne øvelse omhandler tid til graviditet. Et studie vedrørende tid til graviditet (Time To Pregnancy = TTP) inkluderede 423 par i alderen 20-35 år. Parrene blev fulgt i
Statistikøvelse Kandidatstudiet i Folkesundhedsvidenskab 28. September 2004
 Statistikøvelse Kandidatstudiet i Folkesundhedsvidenskab 28. September 2004 Formål med Øvelsen: Formålet med øvelsen er at analysere om risikoen for død er forbundet med to forskellige vacciner BCG (mod
Statistikøvelse Kandidatstudiet i Folkesundhedsvidenskab 28. September 2004 Formål med Øvelsen: Formålet med øvelsen er at analysere om risikoen for død er forbundet med to forskellige vacciner BCG (mod
SAS-øvelse: Vi starter ud med model et hvor x=(kvotient, eksald, halvaar, kvinde, MatB,, Gif).
.") Vi vil formulere en model for et kvalitativ variabel y i med to udfald, at bestå og ikke at bestå første årsprøve. Derefter modeller vi respons-sandsynligheden: Specifikation af sandsynligheden for at
Vi vil formulere en model for et kvalitativ variabel y i med to udfald, at bestå og ikke at bestå første årsprøve. Derefter modeller vi respons-sandsynligheden: Specifikation af sandsynligheden for at
Noter til Specialkursus i videregående statistik
 Noter til Specialkursus i videregående statistik Poul Thyregod IMM, februar 2005 Indhold Forord 6 1 Momenter og flerdimensionale stokastiske variable 7 1.0 Indledning............................. 7 1.1
Noter til Specialkursus i videregående statistik Poul Thyregod IMM, februar 2005 Indhold Forord 6 1 Momenter og flerdimensionale stokastiske variable 7 1.0 Indledning............................. 7 1.1
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006
 PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006 I dag: To stikprøver fra en normalfordeling, ikke-parametriske metoder og beregning af stikprøvestørrelse Eksempel: Fiskeolie
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006 I dag: To stikprøver fra en normalfordeling, ikke-parametriske metoder og beregning af stikprøvestørrelse Eksempel: Fiskeolie
Dan dine egne SAS - funktioner med PROC FCMP
 Dan dine egne SAS - funktioner med PROC FCMP Karsten Lund, chefkonsulent PS Commercial / Life Sciences Fordele og ulemper ved at anvende PROC FCMP Fordele ved at anvende PROC FCMP Bedre mulighed for at
Dan dine egne SAS - funktioner med PROC FCMP Karsten Lund, chefkonsulent PS Commercial / Life Sciences Fordele og ulemper ved at anvende PROC FCMP Fordele ved at anvende PROC FCMP Bedre mulighed for at
Kvantitative Metoder 1 - Forår 2007. Dagens program
 Dagens program Hypoteser: kap: 10.1-10.2 Eksempler på Maximum likelihood analyser kap 9.10 Test Hypoteser kap. 10.1 Testprocedure kap 10.2 Teststørrelsen Testsandsynlighed 1 Estimationsmetoder Kvantitative
Dagens program Hypoteser: kap: 10.1-10.2 Eksempler på Maximum likelihood analyser kap 9.10 Test Hypoteser kap. 10.1 Testprocedure kap 10.2 Teststørrelsen Testsandsynlighed 1 Estimationsmetoder Kvantitative
Kursus i varians- og regressionsanalyse Data med detektionsgrænse. Birthe Lykke Thomsen H. Lundbeck A/S
 Kursus i varians- og regressionsanalyse Data med detektionsgrænse Birthe Lykke Thomsen H. Lundbeck A/S 1 Data med detektionsgrænse Venstrecensurering: Baggrundsstøj eller begrænsning i måleudstyrets følsomhed
Kursus i varians- og regressionsanalyse Data med detektionsgrænse Birthe Lykke Thomsen H. Lundbeck A/S 1 Data med detektionsgrænse Venstrecensurering: Baggrundsstøj eller begrænsning i måleudstyrets følsomhed
Dagens Temaer. Test for lineær regression. Test for lineær regression - via proc glm. k normalfordelte obs. rækker i proc glm. p. 1/??
 Dagens Temaer k normalfordelte obs. rækker i proc glm. Test for lineær regression Test for lineær regression - via proc glm p. 1/?? Proc glm Vi indlæser data i datasættet stress, der har to variable: areal,
Dagens Temaer k normalfordelte obs. rækker i proc glm. Test for lineær regression Test for lineær regression - via proc glm p. 1/?? Proc glm Vi indlæser data i datasættet stress, der har to variable: areal,
Peter Kellberg. Rundt om Danmarks Statistiks makroer. Design, Standardisering, Teknik
 Peter Kellberg Rundt om Danmarks Statistiks makroer Design, Standardisering, Teknik SAS Forum 2009 Ét makrobibliotek ca 50 makroer, vi selv har lavet mange andre fx CLAN Autocall makroer en makro er et
Peter Kellberg Rundt om Danmarks Statistiks makroer Design, Standardisering, Teknik SAS Forum 2009 Ét makrobibliotek ca 50 makroer, vi selv har lavet mange andre fx CLAN Autocall makroer en makro er et
Statistiske Modeller 1: Kontingenstabeller i SAS
 Statistiske Modeller 1: Kontingenstabeller i SAS Jens Ledet Jensen October 31, 2005 1 Indledning Som vist i Notat 1 afsnit 13 er 2 log Q for et test i en multinomialmodel ækvivalent med et test i en poissonmodel.
Statistiske Modeller 1: Kontingenstabeller i SAS Jens Ledet Jensen October 31, 2005 1 Indledning Som vist i Notat 1 afsnit 13 er 2 log Q for et test i en multinomialmodel ækvivalent med et test i en poissonmodel.
Beskrivelse af Finanstilsynets benchmark for levetidsforudsætninger
 Finanstilsynet 30. september 2015 LIFA/IMPE J.nr. 6639-0011 Beskrivelse af Finanstilsynets benchmark for levetidsforudsætninger Anvendelse af benchmark Finanstilsynets benchmark for den observerede nuværende
Finanstilsynet 30. september 2015 LIFA/IMPE J.nr. 6639-0011 Beskrivelse af Finanstilsynets benchmark for levetidsforudsætninger Anvendelse af benchmark Finanstilsynets benchmark for den observerede nuværende
Uge 48 II Teoretisk Statistik 27. november 2003. Numerisk modelkontrol af diskrete fordelinger: intro
 Uge 48 II Teoretisk Statistik 7. november 003 Numerisk modelkontrol af diskrete fordelinger: intro Eksempel: kvalitetskontrol Goodness-of-fit test: generel teori Endeligt udfaldsrum Udfaldsrum uden øvre
Uge 48 II Teoretisk Statistik 7. november 003 Numerisk modelkontrol af diskrete fordelinger: intro Eksempel: kvalitetskontrol Goodness-of-fit test: generel teori Endeligt udfaldsrum Udfaldsrum uden øvre
Logistisk regression. Basal Statistik for medicinske PhD-studerende November 2008
 Logistisk regression Basal Statistik for medicinske PhD-studerende November 2008 Bendix Carstensen Steno Diabetes Center, Gentofte & Biostatististisk afdeling, Københavns Universitet bxc@steno.dk www.biostat.ku.dk/~bxc
Logistisk regression Basal Statistik for medicinske PhD-studerende November 2008 Bendix Carstensen Steno Diabetes Center, Gentofte & Biostatististisk afdeling, Københavns Universitet bxc@steno.dk www.biostat.ku.dk/~bxc
Reminder: Hypotesetest for én parameter. Økonometri: Lektion 4. F -test Justeret R 2 Aymptotiske resultater. En god model
 Reminder: Hypotesetest for én parameter Antag vi har model Økonometri: Lektion 4 F -test Justeret R 2 Aymptotiske resultater y = β 0 + β 1 x 2 + β 2 x 2 + + β k x k + u. Vi ønsker at teste hypotesen H
Reminder: Hypotesetest for én parameter Antag vi har model Økonometri: Lektion 4 F -test Justeret R 2 Aymptotiske resultater y = β 0 + β 1 x 2 + β 2 x 2 + + β k x k + u. Vi ønsker at teste hypotesen H
Statistik kommandoer i Stata opdateret 16/3 2009 Erik Parner
 Statistik kommandoer i Stata opdateret 16/3 2009 Erik Parner Indledning... 1 Hukommelse... 1 Simple beskrivelser... 1 Data manipulation... 2 Estimation af proportioner... 2 Estimation af rater... 2 Estimation
Statistik kommandoer i Stata opdateret 16/3 2009 Erik Parner Indledning... 1 Hukommelse... 1 Simple beskrivelser... 1 Data manipulation... 2 Estimation af proportioner... 2 Estimation af rater... 2 Estimation
Overlevelsesanalyse. Faculty of Health Sciences
 Faculty of Health Sciences Overlevelsesanalyse Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Program Overlevelsesdata Kaplan-Meier estimatoren
Faculty of Health Sciences Overlevelsesanalyse Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Program Overlevelsesdata Kaplan-Meier estimatoren
µ = κ (θ); Kanonisk link, θ = g(µ) Poul Thyregod, 9. maj Specialkursus vid.stat. foraar 2005
; Kanonisk link, θ = g(µ) Poul Thyregod, 9. maj Specialkursus vid.stat. foraar 2005") Hierarkiske generaliserede lineære modeller Lee og Nelder, Biometrika (21) 88, pp 987-16 Dagens program: Mandag den 2. maj Hierarkiske generaliserede lineære modeller - Afslutning Hierarkisk generaliseret
Hierarkiske generaliserede lineære modeller Lee og Nelder, Biometrika (21) 88, pp 987-16 Dagens program: Mandag den 2. maj Hierarkiske generaliserede lineære modeller - Afslutning Hierarkisk generaliseret
Studiedesigns: Kohorteundersøgelser
 Studiedesigns: Kohorteundersøgelser Mads Kamper-Jørgensen, lektor, maka@sund.ku.dk Afdeling for Social Medicin, Institut for Folkesundhedsvidenskab It og sundhed l 3. maj 2016 l Dias nummer 1 Sidste gang
Studiedesigns: Kohorteundersøgelser Mads Kamper-Jørgensen, lektor, maka@sund.ku.dk Afdeling for Social Medicin, Institut for Folkesundhedsvidenskab It og sundhed l 3. maj 2016 l Dias nummer 1 Sidste gang
Overlevelsesfunktion. Vi kalder S(t) for overlevelsesfunktionen.
 for overlevelsesfunktionen.") 1 Levetidsanalyse Overlevelsesfunktionen Censurering Kaplan-Meier estimatoren Hazard funktionen Proportionale hazards Multipel regression PSE (I17) FSV1 Statistik - 5. lektion 1 / 19 Overlevelsesfunktionen
1 Levetidsanalyse Overlevelsesfunktionen Censurering Kaplan-Meier estimatoren Hazard funktionen Proportionale hazards Multipel regression PSE (I17) FSV1 Statistik - 5. lektion 1 / 19 Overlevelsesfunktionen
Studiedesigns: Kohorteundersøgelser
 Studiedesigns: Kohorteundersøgelser Mads Kamper-Jørgensen, lektor, maka@sund.ku.dk Afdeling for Social Medicin, Institut for Folkesundhedsvidenskab It og sundhed l 28. april 2015 l Dias nummer 1 Sidste
Studiedesigns: Kohorteundersøgelser Mads Kamper-Jørgensen, lektor, maka@sund.ku.dk Afdeling for Social Medicin, Institut for Folkesundhedsvidenskab It og sundhed l 28. april 2015 l Dias nummer 1 Sidste
β = SDD xt SSD t σ 2 s 2 02 = SSD 02 f 02 i=1
 Lineær regression Lad x 1,..., x n være udfald af stokastiske variable X 1,..., X n og betragt modellen M 2 : X i N(α + βt i, σ 2 ) hvor t i, i = 1,..., n, er kendte tal. Konkret analyseres (en del af)
Lineær regression Lad x 1,..., x n være udfald af stokastiske variable X 1,..., X n og betragt modellen M 2 : X i N(α + βt i, σ 2 ) hvor t i, i = 1,..., n, er kendte tal. Konkret analyseres (en del af)
Repræsentative undersøgelser før og nu. Peter Linde, Interviewservice pli@dst.dk
 Repræsentative undersøgelser før og nu Peter Linde, Interviewservice pli@dst.dk >> >> Dagsorden Hvad er en repræsentativ undersøgelse? Bortfald og forskerbeskyttelse Vægtning for bortfald Effekt af vægtning
Repræsentative undersøgelser før og nu Peter Linde, Interviewservice pli@dst.dk >> >> Dagsorden Hvad er en repræsentativ undersøgelse? Bortfald og forskerbeskyttelse Vægtning for bortfald Effekt af vægtning
Faculty of Health Sciences. Basal Statistik. Logistisk regression mm. Lene Theil Skovgaard. 5. marts 2018
 Faculty of Health Sciences Basal Statistik Logistisk regression mm. Lene Theil Skovgaard 5. marts 2018 1 / 22 APPENDIX vedr. SPSS svarende til diverse slides: To-gange-to tabeller, s. 3 Plot af binære
Faculty of Health Sciences Basal Statistik Logistisk regression mm. Lene Theil Skovgaard 5. marts 2018 1 / 22 APPENDIX vedr. SPSS svarende til diverse slides: To-gange-to tabeller, s. 3 Plot af binære
Maple 11 - Chi-i-anden test
 Maple 11 - Chi-i-anden test Erik Vestergaard 2014 Indledning I dette dokument skal vi se hvordan Maple kan bruges til at løse opgaver indenfor χ 2 tests: χ 2 - Goodness of fit test samt χ 2 -uafhængighedstest.
Maple 11 - Chi-i-anden test Erik Vestergaard 2014 Indledning I dette dokument skal vi se hvordan Maple kan bruges til at løse opgaver indenfor χ 2 tests: χ 2 - Goodness of fit test samt χ 2 -uafhængighedstest.
Program. Logistisk regression. Eksempel: pesticider og møl. Odds og odds-ratios (igen)
") Faculty of Life Sciences Program Logistisk regression Claus Ekstrøm E-mail: ekstrom@life.ku.dk Odds og odds-ratios igen Logistisk regression Estimation og inferens Modelkontrol Slide 2 Statistisk Dataanalyse
Faculty of Life Sciences Program Logistisk regression Claus Ekstrøm E-mail: ekstrom@life.ku.dk Odds og odds-ratios igen Logistisk regression Estimation og inferens Modelkontrol Slide 2 Statistisk Dataanalyse
DATALOGI 1E. Skriftlig eksamen torsdag den 3. juni 2004
 Københavns Universitet Naturvidenskabelig Embedseksamen DATALOGI 1E Skriftlig eksamen torsdag den 3. juni 2004 Opgaverne vægtes i forhold til tidsangivelsen herunder, og hver opgaves besvarelse bedømmes
Københavns Universitet Naturvidenskabelig Embedseksamen DATALOGI 1E Skriftlig eksamen torsdag den 3. juni 2004 Opgaverne vægtes i forhold til tidsangivelsen herunder, og hver opgaves besvarelse bedømmes
Investerings- og finansieringsteori
 Sidste gang: Beviste hovedsætningerne & et nyttigt korollar 1. En finansiel model er arbitragefri hvis og kun den har et (ækvivalent) martingalmål, dvs. der findes et sandsynlighedsmål Q så S i t = E Q
Sidste gang: Beviste hovedsætningerne & et nyttigt korollar 1. En finansiel model er arbitragefri hvis og kun den har et (ækvivalent) martingalmål, dvs. der findes et sandsynlighedsmål Q så S i t = E Q
MPH specialmodul i epidemiologi og biostatistik. SAS. Introduktion til SAS. Eksempel: Blodtryk og fedme
 MPH specialmodul i epidemiologi og biostatistik. SAS Introduktion til SAS. Display manager (programmering) Vinduer: program editor (med syntaks-check) log output reproducerbart (program teksten kan gemmes
MPH specialmodul i epidemiologi og biostatistik. SAS Introduktion til SAS. Display manager (programmering) Vinduer: program editor (med syntaks-check) log output reproducerbart (program teksten kan gemmes
4. september 2003. π B = Lungefunktions data fra tirsdags Gennemsnit l/min
 Epidemiologi og biostatistik Uge, torsdag 28. august 2003 Morten Frydenberg, Institut for Biostatistik. og hoste estimation sikkerhedsintervaller antagelr Normalfordelingen Prædiktion Statistisk test (udfra
Epidemiologi og biostatistik Uge, torsdag 28. august 2003 Morten Frydenberg, Institut for Biostatistik. og hoste estimation sikkerhedsintervaller antagelr Normalfordelingen Prædiktion Statistisk test (udfra
I dag. Statistisk analyse af en enkelt stikprøve med kendt varians Sandsynlighedsregning og Statistik (SaSt) Eksempel: kobbertråd
 Eksempel: kobbertråd") I dag Statistisk analyse af en enkelt stikprøve med kendt varians Sandsynlighedsregning og Statistik SaSt) Helle Sørensen Først lidt om de sidste uger af SaSt. Derefter statistisk analyse af en enkelt
I dag Statistisk analyse af en enkelt stikprøve med kendt varians Sandsynlighedsregning og Statistik SaSt) Helle Sørensen Først lidt om de sidste uger af SaSt. Derefter statistisk analyse af en enkelt
Faculty of Health Sciences. Basal statistik. Overlevelsesanalyse. Lene Theil Skovgaard. 1. april 2019
 Faculty of Health Sciences Basal statistik Overlevelsesanalyse Lene Theil Skovgaard 1. april 2019 1 / 92 Overlevelsesanalyse Levetider og censurerede observationer Kaplan-Meier kurver Log-rank test Cox
Faculty of Health Sciences Basal statistik Overlevelsesanalyse Lene Theil Skovgaard 1. april 2019 1 / 92 Overlevelsesanalyse Levetider og censurerede observationer Kaplan-Meier kurver Log-rank test Cox
9. Chi-i-anden test, case-control data, logistisk regression.
 Biostatistik - Cand.Scient.San. 2. semester Karl Bang Christensen Biostatististisk afdeling, KU kach@biostat.ku.dk, 35327491 9. Chi-i-anden test, case-control data, logistisk regression. http://biostat.ku.dk/~kach/css2014/
Biostatistik - Cand.Scient.San. 2. semester Karl Bang Christensen Biostatististisk afdeling, KU kach@biostat.ku.dk, 35327491 9. Chi-i-anden test, case-control data, logistisk regression. http://biostat.ku.dk/~kach/css2014/
Basal statistik. Overlevelsesanalyse. Eksempel: Lungecancer blandt krigsveteraner. Faculty of Health Sciences
 Faculty of Health Sciences Overlevelsesanalyse Basal statistik Overlevelsesanalyse Lene Theil Skovgaard 5. november 2018 Levetider og censurerede observationer Kaplan-Meier kurver Log-rank test Cox regression
Faculty of Health Sciences Overlevelsesanalyse Basal statistik Overlevelsesanalyse Lene Theil Skovgaard 5. november 2018 Levetider og censurerede observationer Kaplan-Meier kurver Log-rank test Cox regression
Statistik og Sandsynlighedsregning 2. IH kapitel 12. Overheads til forelæsninger, mandag 6. uge
 Statistik og Sandsynlighedsregning 2 IH kapitel 12 Overheads til forelæsninger, mandag 6. uge 1 Fordelingen af én (1): Regressionsanalyse udfaldsvariabel responsvariabel afhængig variabel Y variabel 2
Statistik og Sandsynlighedsregning 2 IH kapitel 12 Overheads til forelæsninger, mandag 6. uge 1 Fordelingen af én (1): Regressionsanalyse udfaldsvariabel responsvariabel afhængig variabel Y variabel 2
MPH specialmodul Epidemiologi og Biostatistik
 MPH specialmodul Epidemiologi og Biostatistik Repetition af variansanalyse Overlevelsesanalyse Bestemmelse af stikprøvestørrelse Matchning 30. maj 2011 www.biostat.ku.dk/~sr/mphspec11 Susanne Rosthøj (Per
MPH specialmodul Epidemiologi og Biostatistik Repetition af variansanalyse Overlevelsesanalyse Bestemmelse af stikprøvestørrelse Matchning 30. maj 2011 www.biostat.ku.dk/~sr/mphspec11 Susanne Rosthøj (Per
Module 12: Mere om variansanalyse
 Mathematical Statistics ST06: Linear Models Bent Jørgensen og Pia Larsen Module 2: Mere om variansanalyse 2. Parreded observationer................................ 2.2 Faktor med 2 niveauer (0- variabel)........................
Mathematical Statistics ST06: Linear Models Bent Jørgensen og Pia Larsen Module 2: Mere om variansanalyse 2. Parreded observationer................................ 2.2 Faktor med 2 niveauer (0- variabel)........................
Introduktion til overlevelsesanalyse
 Faculty of Health Sciences Introduktion til overlevelsesanalyse Cox regression III Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Kursushjemmeside:
Faculty of Health Sciences Introduktion til overlevelsesanalyse Cox regression III Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Kursushjemmeside:
Opgave 1 Betragt to diskrete stokastiske variable X og Y. Antag at sandsynlighedsfunktionen p X for X er givet ved
 Matematisk Modellering 1 (reeksamen) Side 1 Opgave 1 Betragt to diskrete stokastiske variable X og Y. Antag at sandsynlighedsfunktionen p X for X er givet ved { 1 hvis x {1, 2, 3}, p X (x) = 3 0 ellers,
Matematisk Modellering 1 (reeksamen) Side 1 Opgave 1 Betragt to diskrete stokastiske variable X og Y. Antag at sandsynlighedsfunktionen p X for X er givet ved { 1 hvis x {1, 2, 3}, p X (x) = 3 0 ellers,
Estimation og konfidensintervaller
 Statistik og Sandsynlighedsregning STAT kapitel 4.4 Susanne Ditlevsen Institut for Matematiske Fag Email: susanne@math.ku.dk http://math.ku.dk/ susanne Estimation og konfidensintervaller Antag X Bin(n,
Statistik og Sandsynlighedsregning STAT kapitel 4.4 Susanne Ditlevsen Institut for Matematiske Fag Email: susanne@math.ku.dk http://math.ku.dk/ susanne Estimation og konfidensintervaller Antag X Bin(n,
Morten Frydenberg 26. april 2004
 Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik RESUME: 2 2. gang: 2002 Institut for Biostatistik, Århus Universitet MPH. studieår Specialmodul 4 Cand. San. uddannelsen.
Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik RESUME: 2 2. gang: 2002 Institut for Biostatistik, Århus Universitet MPH. studieår Specialmodul 4 Cand. San. uddannelsen.
Kvantitative Metoder 1 - Efterår Dagens program
 Dagens program Estimation: Kapitel 9.7-9.10 Estimationsmetoder kap 9.10 Momentestimation Maximum likelihood estimation Test Hypoteser kap. 10.1 Testprocedure kap 10.2 Teststørrelsen Testsandsynlighed 1
Dagens program Estimation: Kapitel 9.7-9.10 Estimationsmetoder kap 9.10 Momentestimation Maximum likelihood estimation Test Hypoteser kap. 10.1 Testprocedure kap 10.2 Teststørrelsen Testsandsynlighed 1
Multipel regression. M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model
 M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model") Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
MPH specialmodul Epidemiologi og Biostatistik
 MPH specialmodul Epidemiologi og Biostatistik Kvantitative udfaldsvariable 23. maj 2011 www.biostat.ku.dk/~sr/mphspec11 Susanne Rosthøj (Per Kragh Andersen) 1 Kapitelhenvisninger Andersen & Skovgaard:
MPH specialmodul Epidemiologi og Biostatistik Kvantitative udfaldsvariable 23. maj 2011 www.biostat.ku.dk/~sr/mphspec11 Susanne Rosthøj (Per Kragh Andersen) 1 Kapitelhenvisninger Andersen & Skovgaard:
Demo af PROC GLIMMIX: Analyse af gentagne observationer
 Demo af PROC GLIMMIX: Analyse af gentagne observationer Kristina Birch, seniorkonsulent, PS Banking Agenda Uafhængige vs. afhængige observationer Analyse af uafhængige vs. afhængige observationer Lille
Demo af PROC GLIMMIX: Analyse af gentagne observationer Kristina Birch, seniorkonsulent, PS Banking Agenda Uafhængige vs. afhængige observationer Analyse af uafhængige vs. afhængige observationer Lille
Løsning til øvelsesopgaver dag 4 spg 5-9
 Løsning til øvelsesopgaver dag 4 spg 5-9 5: Den multiple model Vi tilføjer nu yderligere to variable til vores model : Køn og kolesterol SBP = a + b*age + c*chol + d*mand hvor mand er 1 for mænd, 0 for
Løsning til øvelsesopgaver dag 4 spg 5-9 5: Den multiple model Vi tilføjer nu yderligere to variable til vores model : Køn og kolesterol SBP = a + b*age + c*chol + d*mand hvor mand er 1 for mænd, 0 for
, i ' 1,...,N ; t ' 1,...,T, - i.i.d.(0,f 2, ), ) ' 0, E(, it. x kjs. œ i,t,s,j,k.
, ) ' 0, E(, it. x kjs. œ i,t,s,j,k.") 3 Den model, som vi gennemgående skal arbejde med i øvelsen, er»one-way Error Component«Modellen (1EC) Modellen specificeres på følgende måde: y it ' x it $ % µ i %, it, i ' 1,,N ; t ' 1,,T, hvor y it
3 Den model, som vi gennemgående skal arbejde med i øvelsen, er»one-way Error Component«Modellen (1EC) Modellen specificeres på følgende måde: y it ' x it $ % µ i %, it, i ' 1,,N ; t ' 1,,T, hvor y it
Susanne Ditlevsen Institut for Matematiske Fag susanne
 Statistik og Sandsynlighedsregning 1 STAT kapitel 4.4 Susanne Ditlevsen Institut for Matematiske Fag Email: susanne@math.ku.dk http://math.ku.dk/ susanne 7. undervisningsuge, mandag 1 Estimation og konfidensintervaller
Statistik og Sandsynlighedsregning 1 STAT kapitel 4.4 Susanne Ditlevsen Institut for Matematiske Fag Email: susanne@math.ku.dk http://math.ku.dk/ susanne 7. undervisningsuge, mandag 1 Estimation og konfidensintervaller
Sandsynlighedsregning: endeligt udfaldsrum (repetition)
") Program: 1. Repetition: sandsynlighedsregning 2. Sandsynlighedsregning fortsat: stokastisk variabel, sandsynlighedsfunktion/tæthed, fordelingsfunktion. 1/16 Sandsynlighedsregning: endeligt udfaldsrum (repetition)
Program: 1. Repetition: sandsynlighedsregning 2. Sandsynlighedsregning fortsat: stokastisk variabel, sandsynlighedsfunktion/tæthed, fordelingsfunktion. 1/16 Sandsynlighedsregning: endeligt udfaldsrum (repetition)
Uge 13 referat hold 4
 Uge 13 referat hold 4 Gruppearbejde 1a: Er variablen kvotient inkluderet på en hensigtsmæssig måde? Der er to problemer med kvotient: 1) Den er trunkeret ved 6.9 og 10.0, løsningen er at indføre dummyer
Uge 13 referat hold 4 Gruppearbejde 1a: Er variablen kvotient inkluderet på en hensigtsmæssig måde? Der er to problemer med kvotient: 1) Den er trunkeret ved 6.9 og 10.0, løsningen er at indføre dummyer
2 Epidemiologi og biostatistik. Uge 5, mandag 26. september 2005 Michael Væth, Institut for Biostatistik
 ... september 1 Epidemiologi og biostatistik. Uge, mandag. september Michael Væth, Institut for Biostatistik. Ikke parametrisk statistiske test : Analyse af overlevelsesdata (ventetidsdata) Censurering
... september 1 Epidemiologi og biostatistik. Uge, mandag. september Michael Væth, Institut for Biostatistik. Ikke parametrisk statistiske test : Analyse af overlevelsesdata (ventetidsdata) Censurering
Faculty of Health Sciences. Logistisk regression: Kvantitative forklarende variable
 Faculty of Health Sciences Logistisk regression: Kvantitative forklarende variable Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Sammenhæng
Faculty of Health Sciences Logistisk regression: Kvantitative forklarende variable Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Sammenhæng
Hvorfor bøvle med MIXED
 Hvorfor bøvle med MIXED E. Jørgensen 1 1 Genetik og Bioteknologi Danmarks Jordbrgsforskning Forskergrppe for Statistik og besltningsteori Årslev 18/01/2006 MIXED vs. GLM Lidt baggrnd Generel Lineær Model
Hvorfor bøvle med MIXED E. Jørgensen 1 1 Genetik og Bioteknologi Danmarks Jordbrgsforskning Forskergrppe for Statistik og besltningsteori Årslev 18/01/2006 MIXED vs. GLM Lidt baggrnd Generel Lineær Model
Øvelse 7: Aktuar-tabeller, Kaplan-Meier kurver og log-rank test
 Øvelse 7: Aktuar-tabeller, Kaplan-Meier kurver og log-rank test Formålet med øvelsen er at analysere risikoen for død forbundet med forskelligt alkoholforbrug. I denne øvelse skal analyserne foretages
Øvelse 7: Aktuar-tabeller, Kaplan-Meier kurver og log-rank test Formålet med øvelsen er at analysere risikoen for død forbundet med forskelligt alkoholforbrug. I denne øvelse skal analyserne foretages
Introduktion til overlevelsesanalyse
 Faculty of Health Sciences Introduktion til overlevelsesanalyse Cox regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Kursushjemmeside:
Faculty of Health Sciences Introduktion til overlevelsesanalyse Cox regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Kursushjemmeside:
Dagens program. Praktisk information:
 Dagens program Praktisk information: Husk hjemmeopgaven i statistik Hypoteseprøvning kap. 11.2,11.3 og 11.8 Eksempel på test Styrkefunktionen kap. 11.2 Stikprøvens størrelse kap. 11.3 Likelihood ratio
Dagens program Praktisk information: Husk hjemmeopgaven i statistik Hypoteseprøvning kap. 11.2,11.3 og 11.8 Eksempel på test Styrkefunktionen kap. 11.2 Stikprøvens størrelse kap. 11.3 Likelihood ratio
Note til styrkefunktionen
 Teoretisk Statistik. årsprøve Note til styrkefunktionen Først er det vigtigt at gøre sig klart, at når man laver statistiske test, så kan man begå to forskellige typer af fejl: Type fejl: At forkaste H
Teoretisk Statistik. årsprøve Note til styrkefunktionen Først er det vigtigt at gøre sig klart, at når man laver statistiske test, så kan man begå to forskellige typer af fejl: Type fejl: At forkaste H
Økonometri 1 Efterår 2006 Ugeseddel 11
 Økonometri 1 Efterår 2006 Ugeseddel 11 Program for øvelserne: Gruppearbejde og plenumdiskussion Introduktion til SAS øvelser SAS øvelser Øvelsesopgave: Paneldata estimation Sammenhængen mellem alder og
Økonometri 1 Efterår 2006 Ugeseddel 11 Program for øvelserne: Gruppearbejde og plenumdiskussion Introduktion til SAS øvelser SAS øvelser Øvelsesopgave: Paneldata estimation Sammenhængen mellem alder og
En intro til radiologisk statistik
 En intro til radiologisk statistik Erik Morre Pedersen Hypoteser og testning Statistisk signifikans 2 x 2 tabellen og lidt om ROC Inter- og intraobserver statistik Styrkeberegning Konklusion Litteratur
En intro til radiologisk statistik Erik Morre Pedersen Hypoteser og testning Statistisk signifikans 2 x 2 tabellen og lidt om ROC Inter- og intraobserver statistik Styrkeberegning Konklusion Litteratur
Statistik kommandoer i Stata opdateret 22/ Erik Parner
 Statistik kommandoer i Stata opdateret 22/4 2008 Erik Parner Indledning... 1 Simple beskrivelser... 1 Data manipulation... 1 Estimation af proportioner... 2 Estimation af rater... 2 Estimation af Relativ
Statistik kommandoer i Stata opdateret 22/4 2008 Erik Parner Indledning... 1 Simple beskrivelser... 1 Data manipulation... 1 Estimation af proportioner... 2 Estimation af rater... 2 Estimation af Relativ
3.600 kg og den gennemsnitlige fødselsvægt kg i stikprøven.
 PhD-kursus i Basal Biostatistik, efterår 2006 Dag 1, onsdag den 6. september 2006 Eksempel: Sammenhæng mellem moderens alder og fødselsvægt I dag: Introduktion til statistik gennem analyse af en stikprøve
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 1, onsdag den 6. september 2006 Eksempel: Sammenhæng mellem moderens alder og fødselsvægt I dag: Introduktion til statistik gennem analyse af en stikprøve
Normalfordelingen. Statistik og Sandsynlighedsregning 2
 Normalfordelingen Statistik og Sandsynlighedsregning 2 Repetition og eksamen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige fejl på
Normalfordelingen Statistik og Sandsynlighedsregning 2 Repetition og eksamen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige fejl på
02402 Løsning til testquiz02402f (Test VI)
") 02402 Løsning til testquiz02402f (Test VI) Spørgsmål 4. En ejendomsmægler ønsker at undersøge om hans kunder får mindre end hvad de har forlangt, når de sælger deres bolig. Han har regisreret følgende:
02402 Løsning til testquiz02402f (Test VI) Spørgsmål 4. En ejendomsmægler ønsker at undersøge om hans kunder får mindre end hvad de har forlangt, når de sælger deres bolig. Han har regisreret følgende:
13.1 Substrat Polynomiel regression Biomasse Kreatinin Læsefærdighed Protein og højde...
 Modul 13: Exercises 13.1 Substrat.......................... 1 13.2 Polynomiel regression.................. 3 13.3 Biomasse.......................... 4 13.4 Kreatinin.......................... 7 13.5 Læsefærdighed......................
Modul 13: Exercises 13.1 Substrat.......................... 1 13.2 Polynomiel regression.................. 3 13.3 Biomasse.......................... 4 13.4 Kreatinin.......................... 7 13.5 Læsefærdighed......................
Overheads til forelæsninger, mandag 5. uge På E har vi en mængde af mulige sandsynlighedsfordelinger for X, (P θ ) θ Θ.
 θ Θ.") Statistiske modeller (Definitioner) Statistik og Sandsynlighedsregning 2 IH kapitel 0 og En observation er en vektor af tal x (x,..., x n ) E, der repræsenterer udfaldet af et (eller flere) eksperimenter.
Statistiske modeller (Definitioner) Statistik og Sandsynlighedsregning 2 IH kapitel 0 og En observation er en vektor af tal x (x,..., x n ) E, der repræsenterer udfaldet af et (eller flere) eksperimenter.
Morten Frydenberg 14. marts 2006
 Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik 1 RESUME: 2 2. gang: 2006 Institut for Biostatistik, Århus Universitet MPH 1. studieår Specialmodul 4 Cand. San. uddannelsen
Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik 1 RESUME: 2 2. gang: 2006 Institut for Biostatistik, Århus Universitet MPH 1. studieår Specialmodul 4 Cand. San. uddannelsen
Eksamen Bacheloruddannelsen i Medicin med industriel specialisering. Eksamensdato: Tid: kl
 Eksamen 2018 Titel på kursus: Uddannelse: Semester: Forsøgsdesign og metoder Bacheloruddannelsen i Medicin med industriel specialisering 6. semester Eksamensdato: 20-02-2018 Tid: kl. 09.00-11.00 Bedømmelsesform
Eksamen 2018 Titel på kursus: Uddannelse: Semester: Forsøgsdesign og metoder Bacheloruddannelsen i Medicin med industriel specialisering 6. semester Eksamensdato: 20-02-2018 Tid: kl. 09.00-11.00 Bedømmelsesform
13.1 Substrat Polynomiel regression Biomasse Kreatinin Læsefærdighed Protein og højde...
 Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen Modul 13: Exercises 13.1 Substrat........................................ 1 13.2 Polynomiel regression................................
Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen Modul 13: Exercises 13.1 Substrat........................................ 1 13.2 Polynomiel regression................................
En Introduktion til SAS. Kapitel 5.
 En Introduktion til SAS. Kapitel 5. Inge Henningsen Afdeling for Statistik og Operationsanalyse Københavns Universitet Marts 2005 6. udgave Kapitel 5 T-test og PROC UNIVARIATE 5.1 Indledning Dette kapitel
En Introduktion til SAS. Kapitel 5. Inge Henningsen Afdeling for Statistik og Operationsanalyse Københavns Universitet Marts 2005 6. udgave Kapitel 5 T-test og PROC UNIVARIATE 5.1 Indledning Dette kapitel
Normalfordelingen og Stikprøvefordelinger
 Normalfordelingen og Stikprøvefordelinger Normalfordelingen Standard Normal Fordelingen Sandsynligheder for Normalfordelingen Transformation af Normalfordelte Stok.Var. Stikprøver og Stikprøvefordelinger
Normalfordelingen og Stikprøvefordelinger Normalfordelingen Standard Normal Fordelingen Sandsynligheder for Normalfordelingen Transformation af Normalfordelte Stok.Var. Stikprøver og Stikprøvefordelinger
Opgavebesvarelse vedr. overlevelsesanalyse
 Opgavebesvarelse vedr. overlevelsesanalyse Opgaven går ud på at vurdere effekten af azathioprine på overlevelsen hos 216 patienter med primær biliær cirrhose (PBC), ref. Christensen et al. (1985). Data
Opgavebesvarelse vedr. overlevelsesanalyse Opgaven går ud på at vurdere effekten af azathioprine på overlevelsen hos 216 patienter med primær biliær cirrhose (PBC), ref. Christensen et al. (1985). Data
Værktøjshjælp for TI-Nspire CAS Struktur for appendiks:
 Værktøjshjælp for TI-Nspire CAS Struktur for appendiks: Til hvert af de gennemgåede værktøjer findes der 5 afsnit. De enkelte afsnit kan læses uafhængigt af hinanden. Der forudsættes et elementært kendskab
Værktøjshjælp for TI-Nspire CAS Struktur for appendiks: Til hvert af de gennemgåede værktøjer findes der 5 afsnit. De enkelte afsnit kan læses uafhængigt af hinanden. Der forudsættes et elementært kendskab
OR stiger eksponentielt med forskellen i BMI. kompliceret model svær at forstå og analysere
 Epidemiologi og biostatistik. Uge 5, torsdag 5. september 003 Morten Frydenberg, Institut for Biostatistik. 1 Analyse af overlevelsesdata (ventetidsdata) Censurering (højre + andet) Kaplan-Meyer kurver
Epidemiologi og biostatistik. Uge 5, torsdag 5. september 003 Morten Frydenberg, Institut for Biostatistik. 1 Analyse af overlevelsesdata (ventetidsdata) Censurering (højre + andet) Kaplan-Meyer kurver
Opsamling Modeltyper: Tabelanalyse Logistisk regression Generaliserede lineære modeller Log-lineære modeller
 Opsamling Modeltyper: Tabelanalyse Logistisk regression Binær respons og kategorisk eller kontinuerte forklarende variable. Generaliserede lineære modeller Normalfordelt respons og kategoriske forklarende
Opsamling Modeltyper: Tabelanalyse Logistisk regression Binær respons og kategorisk eller kontinuerte forklarende variable. Generaliserede lineære modeller Normalfordelt respons og kategoriske forklarende
Skriftlig eksamen i Datalogi
 Roskilde Universitetscenter side 1 af 9 sider Skriftlig eksamen i Datalogi Modul 1 Vinter 1999/2000 Opgavesættet består af 6 opgaver, der ved bedømmelsen tillægges følgende vægte: Opgave 1 5% Opgave 2
Roskilde Universitetscenter side 1 af 9 sider Skriftlig eksamen i Datalogi Modul 1 Vinter 1999/2000 Opgavesættet består af 6 opgaver, der ved bedømmelsen tillægges følgende vægte: Opgave 1 5% Opgave 2
Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06)
") Afdeling for Biostatistik Bo Martin Bibby 23. november 2006 Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06) Vi betragter 4699 personer fra Framingham-studiet. Der er oplysninger om follow-up
Afdeling for Biostatistik Bo Martin Bibby 23. november 2006 Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06) Vi betragter 4699 personer fra Framingham-studiet. Der er oplysninger om follow-up
Brydningsindeks af vand
 Brydningsindeks af vand Øvelsesvejledning til brug i Nanoteket Udarbejdet i Nanoteket, Institut for Fysik, DTU Rettelser sendes til Ole.Trinhammer@fysik.dtu.dk 15. marts 2012 Indhold 1 Indledning 2 2 Formål
Brydningsindeks af vand Øvelsesvejledning til brug i Nanoteket Udarbejdet i Nanoteket, Institut for Fysik, DTU Rettelser sendes til Ole.Trinhammer@fysik.dtu.dk 15. marts 2012 Indhold 1 Indledning 2 2 Formål
Økonometri 1. Dagens program. Den multiple regressionsmodel 18. september 2006
 Dagens program Økonometri Den multiple regressionsmodel 8. september 006 Opsamling af statistiske resultater om den simple lineære regressionsmodel (W kap..5). Den multiple lineære regressionsmodel (W
Dagens program Økonometri Den multiple regressionsmodel 8. september 006 Opsamling af statistiske resultater om den simple lineære regressionsmodel (W kap..5). Den multiple lineære regressionsmodel (W
Introduktion til overlevelsesanalyse
 Faculty of Health Sciences Introduktion til overlevelsesanalyse Kaplan-Meier estimatoren Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk
Faculty of Health Sciences Introduktion til overlevelsesanalyse Kaplan-Meier estimatoren Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk
Dagens Emner. Likelihood teori. Lineær regression (intro) p. 1/22
 p. 1/22") Dagens Emner Likelihood teori Lineær regression (intro) p. 1/22 Likelihood-metoden M : X i N(µ,σ 2 ) hvor µ og σ 2 er ukendte Vi har, at L(µ,σ 2 ) = ( 1 2πσ 2)n/2 e 1 2σ 2 P n (x i µ) 2 er tætheden som
Dagens Emner Likelihood teori Lineær regression (intro) p. 1/22 Likelihood-metoden M : X i N(µ,σ 2 ) hvor µ og σ 2 er ukendte Vi har, at L(µ,σ 2 ) = ( 1 2πσ 2)n/2 e 1 2σ 2 P n (x i µ) 2 er tætheden som
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab. Estimation
 Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Estimation Eksempel: Bissau data Data kommer fra Guinea-Bissau i Vestafrika: 5273 børn blev undersøgt da de var yngre end 7 mdr og blev herefter
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Estimation Eksempel: Bissau data Data kommer fra Guinea-Bissau i Vestafrika: 5273 børn blev undersøgt da de var yngre end 7 mdr og blev herefter
 Tabel 1. BMI, kropsvægt, overvægt og fedme for voksne og børn fordelt på køn. BMI gennemsnit Kropsvægt Normalvægtig Overvægtig Fed Totalt % (N) Alle voksne 25,60 50 35 15 100% (1746) Kvinder 25,54 52 33
Tabel 1. BMI, kropsvægt, overvægt og fedme for voksne og børn fordelt på køn. BMI gennemsnit Kropsvægt Normalvægtig Overvægtig Fed Totalt % (N) Alle voksne 25,60 50 35 15 100% (1746) Kvinder 25,54 52 33
men nu er Z N((µ 1 µ 0 ) n/σ, 1)!! Forkaster hvis X 191 eller X 209 eller
 n/σ, 1)!! Forkaster hvis X 191 eller X 209 eller") Type I og type II fejl Type I fejl: forkast når hypotese sand. α = signifikansniveau= P(type I fejl) Program (8.15-10): Hvis vi forkaster når Z < 2.58 eller Z > 2.58 er α = P(Z < 2.58) + P(Z > 2.58) =
Type I og type II fejl Type I fejl: forkast når hypotese sand. α = signifikansniveau= P(type I fejl) Program (8.15-10): Hvis vi forkaster når Z < 2.58 eller Z > 2.58 er α = P(Z < 2.58) + P(Z > 2.58) =
Faculty of Health Sciences. Styrkeberegninger Poisson regression Overlevelsesanalyse
 Faculty of Health Sciences Styrkeberegninger Poisson regression Overlevelsesanalyse Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Forsøgsplanlægning
Faculty of Health Sciences Styrkeberegninger Poisson regression Overlevelsesanalyse Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet sr@biostat.ku.dk Forsøgsplanlægning
Præsentation og praktisk anvendelse af PROC GLMSELECT
 Præsentation og praktisk anvendelse af PROC GLMSELECT Kristina Birch, projektchef Copyright 2011 SAS Institute Inc. All rights reserved. Præsentation og praktisk anvendelse af PROC GLMSELECT Abstract I
Præsentation og praktisk anvendelse af PROC GLMSELECT Kristina Birch, projektchef Copyright 2011 SAS Institute Inc. All rights reserved. Præsentation og praktisk anvendelse af PROC GLMSELECT Abstract I
SAS formater i Danmarks Statistik
 Danmarks Statistik, Forskningsservice og Kundecenter 9. januar 2012 SAS formater i Danmarks Statistik 1. Indledning... 1 2. Hvor findes formater og øvrige datafiler?... 2 3. Hvordan bruges formater i SAS-programmet?...
Danmarks Statistik, Forskningsservice og Kundecenter 9. januar 2012 SAS formater i Danmarks Statistik 1. Indledning... 1 2. Hvor findes formater og øvrige datafiler?... 2 3. Hvordan bruges formater i SAS-programmet?...
Kursus i anvendt onkologisk statistik og forskningsmetodik Dag 2. Jon K. Bjerregaard
 Kursus i anvendt onkologisk statistik og forskningsmetodik Dag 2 Jon K. Bjerregaard Dag 2 09.00 12.00 Opfriskning fra sidst Gennemgang af artikler Sammenligning af en eller flere grupper Overlevelsesanalyse
Kursus i anvendt onkologisk statistik og forskningsmetodik Dag 2 Jon K. Bjerregaard Dag 2 09.00 12.00 Opfriskning fra sidst Gennemgang af artikler Sammenligning af en eller flere grupper Overlevelsesanalyse
Faculty of Health Sciences. Miscellaneous: Styrkeberegninger Overlevelsesanalyse Analyse af matchede studier
 Faculty of Health Sciences Miscellaneous: Styrkeberegninger Overlevelsesanalyse Analyse af matchede studier Forsøgsplanlægning Sammenligning af to grupper : Hvor mange personer skal vi bruge? Det kommer
Faculty of Health Sciences Miscellaneous: Styrkeberegninger Overlevelsesanalyse Analyse af matchede studier Forsøgsplanlægning Sammenligning af to grupper : Hvor mange personer skal vi bruge? Det kommer
Kvantitative Metoder 1 - Forår 2007. Dagens program
 Dagens program Kapitel 7 Introduktion til statistik Organisering af data Diskrete variabler Kontinuerte variabler Beskrivende statistik Fraktiler Gennemsnit Empirisk varians og spredning Empirisk korrelationkoe
Dagens program Kapitel 7 Introduktion til statistik Organisering af data Diskrete variabler Kontinuerte variabler Beskrivende statistik Fraktiler Gennemsnit Empirisk varians og spredning Empirisk korrelationkoe
OR stiger eksponentielt med forskellen i BMI komplicet model svær at forstå og analysere simpel model
 Epidemiologi og biostatistik. Uge 5, torsdag. marts 1 Morten Frydenberg, Institut for Biostatistik. 1 Analyse af overlevelsesdata (ventetidsdata) Censurering (højre + andet) Kaplan-Meyer kurver Det statistiske
Epidemiologi og biostatistik. Uge 5, torsdag. marts 1 Morten Frydenberg, Institut for Biostatistik. 1 Analyse af overlevelsesdata (ventetidsdata) Censurering (højre + andet) Kaplan-Meyer kurver Det statistiske
Statistik Lektion 1. Introduktion Grundlæggende statistiske begreber Deskriptiv statistik Sandsynlighedsregning
 Statistik Lektion 1 Introduktion Grundlæggende statistiske begreber Deskriptiv statistik Sandsynlighedsregning Introduktion Kasper K. Berthelsen, Inst f. Matematiske Fag Omfang: 8 Kursusgang I fremtiden
Statistik Lektion 1 Introduktion Grundlæggende statistiske begreber Deskriptiv statistik Sandsynlighedsregning Introduktion Kasper K. Berthelsen, Inst f. Matematiske Fag Omfang: 8 Kursusgang I fremtiden