Opgavebesvarelse, korrelerede målinger
|
|
|
- Egil Pedersen
- 7 år siden
- Visninger:
Transkript
1 Opgavebesvarelse, korrelerede målinger I 18 familier bestående af far, mor og 3 børn (i veldefinerede aldersintervaller, med child1 som det ældste barn og child3 som det yngste) har man registreret antallet af infektioner over et bestemt tidsinterval. Familierne er inddelt efter, hvor tæt, de bor sammen, angivet ved faktoren crowding, som har 3 niveauer, uncrowded, crowded og overcrowded. Data ses i tabellen nedenfor: og de ligger i det såkaldte lange format på hjemmesiden. Vi ønsker at undersøge, om boligforholdene har betydning for antallet af infektioner, samt om visse familiemedlemmer er mere udsat end andre. 1
2 1. Indlæs data, og overvej strukturen i disse: Det originale datasæt var i det såkaldte brede format: således at alle data hørende til en enkelt familie står på samme linie, i rækkefølgen: far, mor og de 3 børn, ordnet med den ældste først. Men når man skal analysere data med gentagne målinger, er det langt mere fleksibelt at benytte den lange facon. I det lange format har vi totalt set 90 observationer (18 familier, hver med 5 medlemmer), og 4 variable: crowding, family, name og swabs. (a) Hvad er outcome? Det er variablen swabs, som angiver antallet af infektioner over en vis periode. Vi skal analysere denne i normalfordelingsbaserede modeller, selv om dette måske ikke er helt rimeligt. Kommentarer til dette gives til sidst. (b) Hvilke kovariater har vi? Vi er interesserede i at evaluere effekten af boligforhold (crowding) samt status i familien (name). Men vi er også nødt til at tage hensyn til, at personerne hænger sammen 5 og 5 i familier. 2
3 (c) - og hvordan skal effekten af disse beskrives i modellen? dvs. hvilke er systematiske, og hvilke er tilfældige? Kovariaterne crowding og name er systematiske effekter, medens family er en tilfældig (random) effect, som er nestet i crowding. Vi er ikke interesserede i disse specifikke familier, de er bare repræsentanter for familier i al almindelighed. 2. Lav en (eller flere) arbejdstegning(er), der så vidt muligt indeholder al informationen i data. Vi laver opdelte spaghetti-plots, et for hver niveau af crowding, dvs. med 6 familier på hvert plot. Dette gøres i Graph/Chart Builder/Line Plot, hvor man vælger det opdelte plot (med flere linier). Herefter klikker man på Groups/Point ID, afkrydser Columns panel variable (eller evt. Rows) og sætter crowding over i Panel?. Desuden sættes swabs på Y-aksen, name på X-aksen, og family i Set Color. Herved får vi Der er andre muligheder for illustration, f.eks. et såkaldt heatplot, som kan fås ved at gå ind i Graph/Graphboard Template Chooser, hvor man vælger Heat Map. Man kan desuden gå ind i Detailed og vælge, 3


4 hvad der skal være X- og Y-akse (her kaldet Columns og Rows). Herved får vi billedet: 4
. 3. Fit en passende varianskomponentmodel til disse data, dvs. en model, der specificerer samme korrelation mellem alle familiemedlemmer i samme familie.")
5 Her angiver farvekoden, hvor mange infektioner, man har pådraget sig, og vi ser, at de stærkt røde farver koncentrerer sig om de yngste børn, samt familierne med lavest nummer (som svarer til overcrowding). 3. Fit en passende varianskomponentmodel til disse data, dvs. en model, der specificerer samme korrelation mellem alle familiemedlemmer i samme familie. Vi går ind i Analyze/Mixed Models/Linear, hvor vi starter med at sætte family over i Subjects: Herefter trykkes Continue, hvorefter swabs sættes i Dependent Variable og såvel crowding, name og family i Factors. Under Fixed sættes crowding og name over i Model, og under Random sættes family over i Model: 5


6 Endelig går man ind i Statistics og afkrydser Parameter Estimates (og evt. Covariance of residuals): 6

7 hvorved vi får outputtet (beskåret) 7
, og fra de tilhørende estimater ses, at der er flest infektioner, når man bor trangt og færre, når man bor")
8 samt estimaterne for varianskomponenterne: Vi ser, at der er en signifikant effekt af crowding (P=0.019), og fra de tilhørende estimater ses, at der er flest infektioner, når man bor trangt og færre, når man bor bedre, som forventet. 8
9 Der er ligeledes en (stærkt) signifikant forskel på de 5 typer af familiemedlemmer (P < ), idet de mindste børn har flest, og forældrene har færrest. For at udføre passende modelkontrol, benyttes Save-knappen i modelopsætningen, og under Fixed Predicted Values afkrydses Predicted Values (dette er de predikterede middelværdier, som får navnet FIXPRED_1), mens vi under Predicted values&residuals afkrydser både Predicted Values (dette er familie-specifikke prediktioner, altså indeholdende random effects, som får navnet PRED_1) og Residuals (som er de såkaldte conditional residuals, som får navnet RESID_1). Sjovt nok kan man ikke få de sædvanlige unconditional residuals, men man kan selv danne dem ved at trække de predikterede middelværdier fra observationerne. Med disse nye variable er vi i stand til at lave forskellige modelkontroltegninger, f.eks. et plot af residualer mod predikterede værdier: 9

10 Vi kan desuden lave et fraktildiagram ved at gå ind i Analyze/Descriptive Statistics/Q-Q Plots og sætte RESID_1 over i Variables: og histogrammet kan laves i Graph: 10
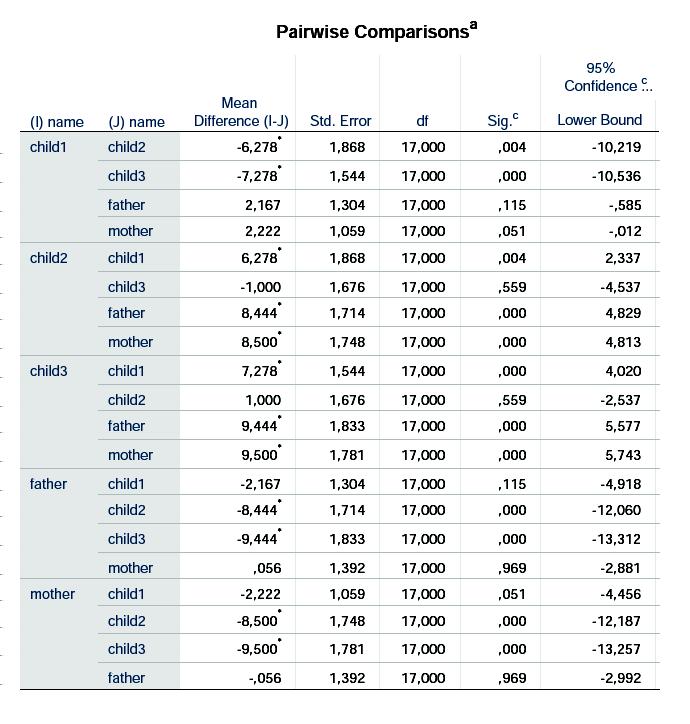
11 Hvis vi tillige udregner de traditionelle residualer (observeret minus estimeret middelværdi, altså trad_res=swabs-fixpred_1), får vi plottet På begge residualplots kan man se en tendens til trompetfacon, så modellen er ikke helt god. Mere om det til allersidst i besvarelsen. (a) Hvad er estimatet for denne korrelation mellem familiemedlemmer i samme familie? Korrelationen estimeres ud fra de to varianskomponenter, til = (b) Giv et estimat (med konfidensinterval) for forskellen på overcrowded og uncrowded. Da uncrowded er referenceniveau for crowding, kan vi direkte aflæse estimatet for denne sammenligning på linien overcrow. Det er 5.60(1.73), dvs. med 95% konfidensinterval på (1.91, 9.29). 11

12 (c) Giv også et estimat (med konfidensinterval) for forskellen på ældste og yngste barn. Her er det lidt sværere, da hverken det ældste eller det yngste barn er referenceniveauet. Man kunne løse dette ved at omdøbe navnene i variablen name, men man kan også gå ind i EM Means i model-opsætningen, og der sætte name over i Display Means for, afkrydse Compare main effects og i Adjustment vælge LSD(none) (fordi vi har spurgt specifikt om denne sammenligning og derfor ikke behøver at korrigere for massesignifikans): hvorved vi får alle parvise (ukorrigerede) sammenligninger mellem familiemedlemmerne: 12

13 Den søgte sammenligning siger, at det ældste barn er mindre belastet af infektioner end det yngste, med en forskel estimeret til 7.3 med 95% konfidensinterval på (4.1, 10.5). 4. Er der evidens for forskellig effekt af trange boligforhold for de enkelte familienmedlemmer? Ovenfor fittede vi en model, der havde en effekt af boligforhold, der var antaget at være den samme for alle familiemedlemmer, idet der var tale om en additiv model, dvs. uden interaktion (vekselvirkning). Vi ser nu på en model med interaktion, for at se, om denne har signifikant betydning. Vi sætter altså interaktionsleddet crowding*name med over i Model: 13

14 og får så outputtet (stærkt beskåret til kun det allermest nødvendige) Der ses tydeligvis ingensomhelst indikation af interaktion, dvs. effekten af boligforhold synes at betyde nogenlunde det samme for alle typer af 14
15 familiemedlemmer (P=0.94). Figuren nedenfor illustrerer de predikterede værdier i modellen med interaktion (faktisk blot gennemsnit af 6 familier). Der ses en svag tendens til, at effekten af boligforhold er mindst for fædrene, men dette er, som nævnt ovenfor, absolut ikke signifikant. Denne figur er blot dannet i Graph/Line plot, med FIXEDPRED_1 på Y-aksen, name på X-aksen og crowding i Set Color. 5. Lav en illustration af de fittede værdier i den model, I ender med. Da der ikke er nogen signifikant interaktion, vil vi udelade interaktionsleddet igen, og ender således med modellen fra spørgsmål 3. De predikterede kurver i denne model ses i figuren nedenfor. Da dette er en additiv model, er der tale om 3 parallelle kurver, og figuren dannes ligesom beskrevet ovenfor, idet man nu har et nyt sæt predikterede værdier (og residualer): 15
16 6. Overvej, om det var fornuftigt, at benytte den anvendte kovariansstruktur. Prøv at fitte modellen med en ustruktureret kovarians og se, hvordan resultaterne ændrer sig. Man kunne sagtens forestille sig, at der var større variation mellem nogle typer af familiemedlemmer (på tværs af familier) end mellem andre. Det oprindelige spaghettiplot i spørgsmål 2 tyder på en noget større variation mellem de små børn end f.eks. mellem fædre. Dette kan man f.eks. også se ved at lave et boxplot af de traditionelle residualer, her kaldet trad_res: 16
17 Desuden kunne man forestille sig, at der var større korrelation mellem børnene indbyrdes, samt mellem mødre og børn, simpelthen fordi det muligvis kunne være begrænset, hvor meget faderen opholdt sig i familien. Vi kan undersøge disse ting ved at benytte en helt generel kovarinsstruktur i stedet for den compound symmetry, som benyttes, når man ser det som en varianskomponentmodel. For at få en ustruktureret kovarians, må vi i Analyze/Mixed Models/Linear igen sætte family over i Subjects, men nu også sætte name ind i Repeated og udskifter Type til at være den ønskede kovariansstruktur, her Unstructured: 17

.")
18 Herefter sættes swabs i Dependent Variable og såvel crowding som name i Factors (og i Model, men uden interaktionsleddet, som vi fandt til at være ubetydeligt). Under Random sættes denne gang ingenting: Vi får så outputtet: 18
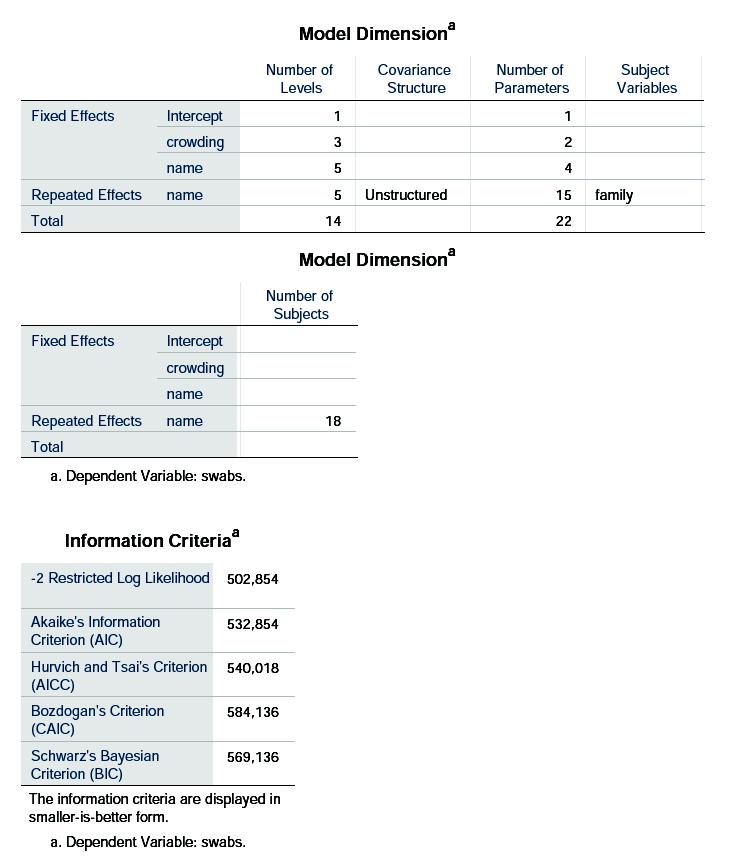
19 19
20 20
, og fra de tilhørende estimater ses, at der er flest infektioner, når man bor trangt og færre, når man bor bedre, som forventet.")
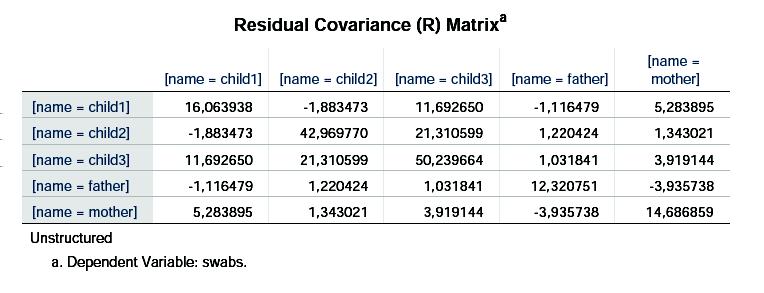
21 I lighed med resultaterne fra spørgsmål 3, finder vi her, at der er en signifikant effekt af crowding (P=0.003 mod før 0.019), og fra de tilhørende estimater ses, at der er flest infektioner, når man bor trangt og færre, når man bor bedre, som forventet. Der er ligeledes ligeledes en (stærkt) signifikant forskel på de 5 typer af familiemedlemmer (P = 0.000), idet de mindste børn har flest, og forældrene har færrest. Fra diagonalen i variansmatricen (R Matrix) ser vi, at variationen stiger, men for at forstå, hvad det betyder, må vi vide, i hvilken rækkefølge, programmet opfatter de 5 familiemedlemmer. Det gøres ud fra rækkefølgen i datasættet, og det betyder, at de står som far-mor-ældstemidterste-yngste barn. Derfor genfinder vi mønstret (naturligvis) fra residualerne, altså at der er mindst variation mellem fædre og størst variation mellem de yngste børn. Da det samme er tilfældet for selve niveauet af målingerne, kunne man fristes til at analysere logaritmer, men da der er ægte nuller i materialet, kan dette ikke lade sig gøre. Hvis man udregner korrelationerne, kan man se, at de største korrela- 21
22 tioner forekommer på plads (2,3), (3,5) og (4,5), altså mellem mor og ældste barn, samt mellem yngste barn og dets søskende. Korrelationen mellem far og mor estimeres til at være negativ, men nu skal man jo ikke overfortolke... Vi kan sammenligne de to kovariansstrukturer ved at se på forskellen i 2 log L. I modellen her med TYPE=UN får vi værdien 502.9, og vi har brugt 15 paramtere til beskrivelse af kovariansen. I den simple varianskomponentmodel brugte vi kun 2 paramtre, og fik 2 log L = Differensen er altså = 24.2 χ 2 (13) P = Modellen med den mere generelle kovariansstruktur fitter altså signifikant bedre end den simple. Estimatet for effekten af overcrow vs. uncrow ses at være 4.72 (1.14), hvor vi i spørgsmål 3 fik 5.60 (1.73). Grunden til, at vi får et lidt andet estimat end i den tidligere model er, at familiemedlemmerne nu vægter lidt anderledes i vurderingen af den enkelte families niveau, pga de uens varianser. Tilsvarende er estimatet for forskellen på yngste og ældste barn (se estimate-sætningen): 7.28 (1.54) mod før 7.28 (1.61). Her er det kun konfidensintervallet, der har ændret sig, fordi alle personer med samme status i familien vægtes ens i begge modeller. 7. Hvilke betragtninger tror I, der ligger til grund for valget af design i denne undersøgelse? Et alternativ kunne jo være blot at undersøge et tilfældigt udpluk af personer. Dette design giver bedre mulighed for at sammenligne familiemedlemmer, fordi der er tale om parrede sammenligninger. Herved slipper vi ved denne sammenligning for den store variation, man må forvente at finde mellem familier, pga. genetik, madvaner mv. Til gengæld får man en mere upræcis vurdering af effekten af boligforhold, fordi korrelationen mellem familiemedlemmer af samme familie nedsætter mængden af uafhængig information. 22
 Hvilken type analyse er der tale om her?")
23 Hvis I herefter har tid, skal I prøve at se, om I kan opnå nogle af ovenstående resultater med traditionelle analysemetoder: 8. Udregn gennemsnitligt antal infektioner for hver familie, og brug det nydannede datasæt til at vurdere effekten af boligforhold (a) Hvilken type analyse er der tale om her? Husk en figur til illustration. For at udregne gennemsnitlige antal infektioner for hver familie, benytter vi Data/Aggregate, hvor vi sætter family over i Break Variable(s) (og her også variablen crowding, så vi får den med over i det nye datasæt): Datasættet (som vi kan gemme som averages) består af 18 linier, en for hver familie, med 4 forståelige variable, nemlig de tidligere family og crowding samt de nydannede swabs_means og N_BREAK (som blot er det antal, der er taget gennemsnit over): 23

24 Vi skal sammenligne det gennemsnitlige antal infektioner i de 18 familier (swabs_means), og familierne er inddelt i 3 grupper, angivet ved boligforholdene, crowding. Der er således tale om en ensidet variansanalyse. En passende figur kunne være et scatterplot, da vi har så få observationer (hvis vi havde haft flere, ville et Box Plot være mere rimeligt): 24

25 Hvis man vil have en anden rækkefølge af grupperne på X-aksen, må man omnummerere. Nu laver vi den ensidede variansanalyse i General Linear Model/Univariate, hvor man sætter swabs_means ind som Dependent Variable og crowding som Fixed Factor. Desuden går man ind i Options og afkrydser det ønskede, hvilket altid vil være Parameter Estimates, og (hvis modellen var lidt mere kompliceret) måske også Residual Plot. Vi får så outputtet 25
26 Vi finder, ligesom i spørgsmål 3, at der er en signifikant effekt af boligforhold på antallet af infektioner, P= (b) Giv igen et estimat (med konfidensinterval) for forskellen på overcrowded og uncrowded, og sammenlign med det ovenfor fundne (spm. 3b). Da uncrowded er referenceniveau for crowding, kan vi direkte aflæse estimatet for denne sammenligning på linien overcrow. Det er 5.60(1.73), dvs. med 95% konfidensinterval på (1.91, 9.29), altså ganske som vi fandt i mixed effects -modellen fra spørgsmål 3. (c) Hvorfor kan vi ikke udfra denne analyse sige noget om forskelle på familiemedlemmer? Vi regner her på gennemsnit over 5 familiemedlemmer, så vi kan 26

27 derfor ikke sige noget om de indbyrdes forskelle på disse ud fra denne analyse. 9. Nu ser vi et øjeblik væk fra faktoren crowding og betragter bare de 18 familier, som om de var tilfældige stikprøver fra samme population. Vi går altså tilbage til det oprindelige datasæt, swabs: (a) Lav en tosidet variansanalyse med faktorerne family og name. Her benytter vi igen General Linear Model/Univariate, hvor vi sætter swabs ind som Dependent Variable og såvel family som name som Fixed Factor. Desuden går vi ind i Options og afkrydser Parameter Estimates, og måske også Residual Plot. Herved får vi: 27
. De yngste børn ser ud til at være de mest sensitive.")
28 Her ser vi en tydelig signifikant forskel på de 18 familier (P=0.001), men en endnu tydeligere forskel på familiemedlemmerne (P = 0.000). (b) Er der evidens for forskelle på de 5 familiemedlemmer? Ja, som nævnt ovenfor er dette meget tydeligt (P = 0.000). De yngste børn ser ud til at være de mest sensitive. (c) Giv igen et estimat (med konfidensinterval) for forskellen på ældste og yngste barn, og sammenlign med det tidligere fundne (spm. 3c). Her må vi i lighed med tidligere sammenligne alle familiemedlemmer parvis ved at gå ind i EM Means i model-opsætningen, og der sætte name over i Display Means for, afkrydse Compare main effects og i Adjustment vælge LSD(none) (fordi vi har spurgt specifikt om denne sammenligning og derfor ikke behøver at korrigere for massesignifikans): 28
, ganske som i spørgsmål 3c. 10. Kan vi vurdere interaktionen mellem crowding og name uden at benytte varianskomponentmodellen?")
29 der igen siger, at det ældste barn er mindre belastet af infektioner end det yngste, med en forskel estimeret til 7.3 med 95% konfidensinterval på (4.1, 10.5), ganske som i spørgsmål 3c. 10. Kan vi vurdere interaktionen mellem crowding og name uden at benytte varianskomponentmodellen? Ja, det kan man faktisk godt, men det kræver, at man sætter familien ind som fixed effect i stedet for: 29


30 der vil give outputtet 30

31 11. Diskuter hvad der sker med de forskellige analysetyper, hvis der mangler nogle observationer. Det afhænger meget af, hvorfor sådanne observationer mangler. Hvis vi bare er kommet til at smide informationen væk, vil mixed model stadig give fornuftige svar og udnytte alle forhåndenværende observationer. Men den ensidede variansanalyse på gennemsnittene for hver familie vil ikke længere give det samme resultat, den vil faktisk være forkert. Hvor meget forkert, den er, afhænger af, hvilken observation, der mangler. Hvis f.eks. det yngste barn fra en overcrowded familie mangler, vil denne familie se ud til at have et ret lavt antal gennemsnitlige infektioner, og derved vil effekten af boligforhold blive undervurderet. Hvis en observation mangler fordi den f.eks. er meget høj, så er der ikke nogen måde at redde det på! Det kaldes informative missing, og det er anledning til mange fejl og mistolkninger. Konklusioner: Der er en signifikant forskel på familier (P=0.01), men det interessrerer os sådan set ikke. Denne faktor optræder i modellen som en tilfældig effekt, som gør det muligt at vurdere effekten af boligforhold. 31
32 Der er en effekt af boligforhold (crowding) på antallet af infektioner (P=0.019), og effekten af denne kan kvantificeres med proc mixed, eller ved hjælp af ensidet variansanalyse på simple familie-gennemsnit, det sidste dog kun i tilfælde af fuldstændigt datasæt, dvs. ingen manglende værdier. Der er signifikant forskel på antallet af infektioner hos de forskellige typer af familiemedlemmer (P < ). Der er flest infektioner blandt de yngste børn, og færrest hos forældrene. Men: Vi har hele vejen antaget, at det er rimeligt at lave normalfordelingsbaserede analyser, og dette ser ikke rigtigt fornuftigt ud, f.eks. fordi et antal altid er ikke-negativt, og her har vi endda en del 0 er. Man kunne forsøge sig med en kvadratrodstransformation, men det giver vanskeligheder ved fortolkningen. Hvis man ønsker at udregne prediktionsområder for antallet af infektioner, skal man i hvert fald gøre et eller andet anderledes end ovenfor, og dette kunne være at modellere antallene som Poissonfordelte. Dette er dog ikke en del af dette kursus. 32
Opgavebesvarelse, korrelerede målinger
 Opgavebesvarelse, korrelerede målinger I 18 familier bestående af far, mor og 3 børn (i veldefinerede aldersintervaller, med child1 som det ældste barn og child3 som det yngste) har man registreret antallet
Opgavebesvarelse, korrelerede målinger I 18 familier bestående af far, mor og 3 børn (i veldefinerede aldersintervaller, med child1 som det ældste barn og child3 som det yngste) har man registreret antallet
Opgavebesvarelse, korrelerede målinger
 Opgavebesvarelse, korrelerede målinger I 18 familier bestående af far, mor og 3 børn (i veldefinerede aldersintervaller, med child1 som det ældste barn og child3 som det yngste) har man registreret antallet
Opgavebesvarelse, korrelerede målinger I 18 familier bestående af far, mor og 3 børn (i veldefinerede aldersintervaller, med child1 som det ældste barn og child3 som det yngste) har man registreret antallet
Basal Statistik - SPSS
 Faculty of Health Sciences Basal Statistik - SPSS Korrelerede målinger. Lene Theil Skovgaard 8. april 2019 1 / 21 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Plots: s. 3, 4,
Faculty of Health Sciences Basal Statistik - SPSS Korrelerede målinger. Lene Theil Skovgaard 8. april 2019 1 / 21 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Plots: s. 3, 4,
Basal Statistik - SPSS
 Faculty of Health Sciences APPENDIX Basal Statistik - SPSS Korrelerede målinger. Lene Theil Skovgaard 8. april 2019 med instruktioner til SPSS-analyse svarende til nogle af slides Plots: s. 3, 4, 7, 11-12
Faculty of Health Sciences APPENDIX Basal Statistik - SPSS Korrelerede målinger. Lene Theil Skovgaard 8. april 2019 med instruktioner til SPSS-analyse svarende til nogle af slides Plots: s. 3, 4, 7, 11-12
SPSS appendix SPSS APPENDIX. Box plots. Indlæsning. Faculty of Health Sciences. Basal Statistik: Sammenligning af grupper, Variansanalyse
 Faculty of Health Sciences SPSS APPENDIX SPSS appendix Basal Statistik: Sammenligning af grupper, Variansanalyse Lene Theil Skovgaard 12. september 2017 med instruktioner til SPSS-analyse svarende til
Faculty of Health Sciences SPSS APPENDIX SPSS appendix Basal Statistik: Sammenligning af grupper, Variansanalyse Lene Theil Skovgaard 12. september 2017 med instruktioner til SPSS-analyse svarende til
Faculty of Health Sciences. SPSS appendix. Basal Statistik: Sammenligning af grupper, Variansanalyse. Lene Theil Skovgaard. 22.
 Faculty of Health Sciences SPSS appendix Basal Statistik: Sammenligning af grupper, Variansanalyse Lene Theil Skovgaard 22. januar 2018 1 / 20 SPSS APPENDIX med instruktioner til SPSS-analyse svarende
Faculty of Health Sciences SPSS appendix Basal Statistik: Sammenligning af grupper, Variansanalyse Lene Theil Skovgaard 22. januar 2018 1 / 20 SPSS APPENDIX med instruktioner til SPSS-analyse svarende
SPSS appendix SPSS APPENDIX. Box plots. Indlæsning. Faculty of Health Sciences. Basal Statistik: Sammenligning af grupper, Variansanalyse
 Faculty of Health Sciences SPSS APPENDIX SPSS appendix Basal Statistik: Sammenligning af grupper, Variansanalyse Lene Theil Skovgaard 11. februar 2019 med instruktioner til SPSS-analyse svarende til nogle
Faculty of Health Sciences SPSS APPENDIX SPSS appendix Basal Statistik: Sammenligning af grupper, Variansanalyse Lene Theil Skovgaard 11. februar 2019 med instruktioner til SPSS-analyse svarende til nogle
Basal Statistik - SPSS
 Faculty of Health Sciences Basal Statistik - SPSS Kovariansanalyse. Lene Theil Skovgaard 3. oktober 2017 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Bland-Altman plot,
Faculty of Health Sciences Basal Statistik - SPSS Kovariansanalyse. Lene Theil Skovgaard 3. oktober 2017 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Bland-Altman plot,
Basal Statistik - SPSS
 Faculty of Health Sciences Basal Statistik - SPSS Kovariansanalyse. Lene Theil Skovgaard 1. oktober 2018 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Bland-Altman plot,
Faculty of Health Sciences Basal Statistik - SPSS Kovariansanalyse. Lene Theil Skovgaard 1. oktober 2018 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Bland-Altman plot,
Basal Statistik - SPSS
 Faculty of Health Sciences Basal Statistik - SPSS Multipel regression. Lene Theil Skovgaard 10. oktober 2017 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Figurer: s.
Faculty of Health Sciences Basal Statistik - SPSS Multipel regression. Lene Theil Skovgaard 10. oktober 2017 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Figurer: s.
Vejledende besvarelse af hjemmeopgave, efterår 2018
 Vejledende besvarelse af hjemmeopgave, efterår 2018 Udleveret 1. oktober, afleveres senest ved øvelserne i uge 44 (30. oktober.-1. november). Der er foretaget en del undersøgelser af krigsveteraner og
Vejledende besvarelse af hjemmeopgave, efterår 2018 Udleveret 1. oktober, afleveres senest ved øvelserne i uge 44 (30. oktober.-1. november). Der er foretaget en del undersøgelser af krigsveteraner og
Basal Statistik - SPSS
 Faculty of Health Sciences APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Basal Statistik - SPSS Den generelle lineære model. Lene Theil Skovgaard 24. oktober 2017 Biokemisk iltforbrug,
Faculty of Health Sciences APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Basal Statistik - SPSS Den generelle lineære model. Lene Theil Skovgaard 24. oktober 2017 Biokemisk iltforbrug,
Basal Statistik - SPSS
 Faculty of Health Sciences Basal Statistik - SPSS Den generelle lineære model. Lene Theil Skovgaard 26. februar 2018 1 / 28 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Biokemisk
Faculty of Health Sciences Basal Statistik - SPSS Den generelle lineære model. Lene Theil Skovgaard 26. februar 2018 1 / 28 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Biokemisk
Vejledende besvarelse af hjemmeopgave, forår 2018
 Vejledende besvarelse af hjemmeopgave, forår 2018 Udleveret 12. februar, afleveres senest ved øvelserne i uge 10 (6.-9.marts) I forbindelse med reagensglasbehandling blev 100 par randomiseret til to forskellige
Vejledende besvarelse af hjemmeopgave, forår 2018 Udleveret 12. februar, afleveres senest ved øvelserne i uge 10 (6.-9.marts) I forbindelse med reagensglasbehandling blev 100 par randomiseret til to forskellige
Øvelser til basalkursus, 5. uge. Opgavebesvarelse: Knogledensitet hos unge piger
 Øvelser til basalkursus, 5. uge Opgavebesvarelse: Knogledensitet hos unge piger I alt 112 piger har fået målt knogledensitet (bone mineral density, bmd) i 11-års alderen (baseline værdi). Pigerne er herefter
Øvelser til basalkursus, 5. uge Opgavebesvarelse: Knogledensitet hos unge piger I alt 112 piger har fået målt knogledensitet (bone mineral density, bmd) i 11-års alderen (baseline værdi). Pigerne er herefter
Basal Statistik - SPSS
 Faculty of Health Sciences Basal Statistik - SPSS Regressionsanalyse. Lene Theil Skovgaard 5. februar 2018 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Indlæsning og
Faculty of Health Sciences Basal Statistik - SPSS Regressionsanalyse. Lene Theil Skovgaard 5. februar 2018 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Indlæsning og
Basal statistik for lægevidenskabelige forskere, forår 2012 Udleveret 6.marts, afleveres senest ved øvelserne i uge 15 (
 Hjemmeopgave Basal statistik for lægevidenskabelige forskere, forår 2012 Udleveret 6.marts, afleveres senest ved øvelserne i uge 15 (10.-12. april) I et randomiseret forsøg sammenlignes vitamin D behandling
Hjemmeopgave Basal statistik for lægevidenskabelige forskere, forår 2012 Udleveret 6.marts, afleveres senest ved øvelserne i uge 15 (10.-12. april) I et randomiseret forsøg sammenlignes vitamin D behandling
Modelkontrol i Faktor Modeller
 Modelkontrol i Faktor Modeller Julie Lyng Forman Københavns Universitet Afdeling for Anvendt Matematik og Statistik Statistik for Biokemikere 2003 For at konklusionerne på en ensidet, flersidet eller hierarkisk
Modelkontrol i Faktor Modeller Julie Lyng Forman Københavns Universitet Afdeling for Anvendt Matematik og Statistik Statistik for Biokemikere 2003 For at konklusionerne på en ensidet, flersidet eller hierarkisk
1 Hb SS Hb Sβ Hb SC = , (s = )
") PhD-kursus i Basal Biostatistik, efterår 2006 Dag 6, onsdag den 11. oktober 2006 Eksempel 9.1: Hæmoglobin-niveau og seglcellesygdom Data: Hæmoglobin-niveau (g/dl) for 41 patienter med en af tre typer seglcellesygdom.
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 6, onsdag den 11. oktober 2006 Eksempel 9.1: Hæmoglobin-niveau og seglcellesygdom Data: Hæmoglobin-niveau (g/dl) for 41 patienter med en af tre typer seglcellesygdom.
Vejledende besvarelse af hjemmeopgave, efterår 2017
 Vejledende besvarelse af hjemmeopgave, efterår 2017 Udleveret 3. oktober 2017, afleveres senest ved øvelserne i uge 44 (31. okt.-2. nov. 2017) På hjemmesiden http://publicifsv.sund.ku.dk/~lts/basal17_2/hjemmeopgave/hjemmeopgave.txt
Vejledende besvarelse af hjemmeopgave, efterår 2017 Udleveret 3. oktober 2017, afleveres senest ved øvelserne i uge 44 (31. okt.-2. nov. 2017) På hjemmesiden http://publicifsv.sund.ku.dk/~lts/basal17_2/hjemmeopgave/hjemmeopgave.txt
Program. 1. Varianskomponent-modeller (Random Effects) 2. Transformation af data. 1/12
 2. Transformation af data. 1/12") Program 1. Varianskomponent-modeller (Random Effects) 2. Transformation af data. 1/12 Dæktyper og brændstofforbrug Data fra opgave 10.43, side 360: cars 1 2 3 4 5... radial 4.2 4.7 6.6 7.0 6.7... belt
Program 1. Varianskomponent-modeller (Random Effects) 2. Transformation af data. 1/12 Dæktyper og brændstofforbrug Data fra opgave 10.43, side 360: cars 1 2 3 4 5... radial 4.2 4.7 6.6 7.0 6.7... belt
Basal Statistik - SPSS
 Faculty of Health Sciences Basal Statistik - SPSS Begreber. Parrede sammenligninger. Lene Theil Skovgaard 5. september 2017 1 / 16 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides
Faculty of Health Sciences Basal Statistik - SPSS Begreber. Parrede sammenligninger. Lene Theil Skovgaard 5. september 2017 1 / 16 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides
Faculty of Health Sciences. Basal Statistik. Logistisk regression mm. Lene Theil Skovgaard. 5. marts 2018
 Faculty of Health Sciences Basal Statistik Logistisk regression mm. Lene Theil Skovgaard 5. marts 2018 1 / 22 APPENDIX vedr. SPSS svarende til diverse slides: To-gange-to tabeller, s. 3 Plot af binære
Faculty of Health Sciences Basal Statistik Logistisk regression mm. Lene Theil Skovgaard 5. marts 2018 1 / 22 APPENDIX vedr. SPSS svarende til diverse slides: To-gange-to tabeller, s. 3 Plot af binære
Anvendt Statistik Lektion 9. Variansanalyse (ANOVA)
") Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Kommentarer til øvelser i basalkursus, 2. uge
 Kommentarer til øvelser i basalkursus, 2. uge Opgave 2. Vi betragter målinger af hjertevægt (i g) og total kropsvægt (målt i kg) for 10 normale mænd og 11 mænd med hjertesvigt. Målingerne er taget ved
Kommentarer til øvelser i basalkursus, 2. uge Opgave 2. Vi betragter målinger af hjertevægt (i g) og total kropsvægt (målt i kg) for 10 normale mænd og 11 mænd med hjertesvigt. Målingerne er taget ved
Anvendt Statistik Lektion 9. Variansanalyse (ANOVA)
") Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Besvarelse af opgave om Vital Capacity
 Besvarelse af opgave om Vital Capacity I filen cadmium.txt ligger observationer fra et eksempel omhandlende lungefunktionen hos arbejdere i cadmium industrien (hentet fra P. Armitage & G. Berry: Statistical
Besvarelse af opgave om Vital Capacity I filen cadmium.txt ligger observationer fra et eksempel omhandlende lungefunktionen hos arbejdere i cadmium industrien (hentet fra P. Armitage & G. Berry: Statistical
Vejledende besvarelse af hjemmeopgave, forår 2017
 Vejledende besvarelse af hjemmeopgave, forår 2017 På hjemmesiden http://publicifsv.sund.ku.dk/~lts/basal17_1/hjemmeopgave/hjemmeopgave.txt ligger data fra 400 fødende kvinder. Der er tale om et uddrag
Vejledende besvarelse af hjemmeopgave, forår 2017 På hjemmesiden http://publicifsv.sund.ku.dk/~lts/basal17_1/hjemmeopgave/hjemmeopgave.txt ligger data fra 400 fødende kvinder. Der er tale om et uddrag
Phd-kursus i Basal Statistik, Opgaver til 2. uge
 Phd-kursus i Basal Statistik, Opgaver til 2. uge Opgave 1: Sædkvalitet Filen oeko.sav på hjemmesiden indeholder datamateriale til belysning af forskellen i sædkvalitet mellem SAS-ansatte og mænd, der lever
Phd-kursus i Basal Statistik, Opgaver til 2. uge Opgave 1: Sædkvalitet Filen oeko.sav på hjemmesiden indeholder datamateriale til belysning af forskellen i sædkvalitet mellem SAS-ansatte og mænd, der lever
To-sidet variansanalyse
 Program 1. To-sidet variansanalyse 2. Hierarkisk princip 3. Tre (og flere) sidet variansanalyse 4. Variansanalyse med blocking 5. Flersidet variansanalyse med tilfældige faktorer 6. En oversigtsslide til
Program 1. To-sidet variansanalyse 2. Hierarkisk princip 3. Tre (og flere) sidet variansanalyse 4. Variansanalyse med blocking 5. Flersidet variansanalyse med tilfældige faktorer 6. En oversigtsslide til
Indhold. 2 Tosidet variansanalyse Additive virkninger Vekselvirkning... 9
 Indhold 1 Ensidet variansanalyse 2 1.1 Estimation af middelværdier............................... 3 1.2 Estimation af standardafvigelse............................. 3 1.3 F-test for ens middelværdier...............................
Indhold 1 Ensidet variansanalyse 2 1.1 Estimation af middelværdier............................... 3 1.2 Estimation af standardafvigelse............................. 3 1.3 F-test for ens middelværdier...............................
Vejledende besvarelse af hjemmeopgave, forår 2019
 Vejledende besvarelse af hjemmeopgave, forår 2019 Udleveret 4. marts, afleveres senest ved øvelserne i uge 13 (26. marts.-28. marts). På hjemmesiden http://staff.pubhealth.ku.dk/~lts/basal19_1/hjemmeopgave.html
Vejledende besvarelse af hjemmeopgave, forår 2019 Udleveret 4. marts, afleveres senest ved øvelserne i uge 13 (26. marts.-28. marts). På hjemmesiden http://staff.pubhealth.ku.dk/~lts/basal19_1/hjemmeopgave.html
Øvelser til basalkursus, 5. uge. Opgavebesvarelse: Knogledensitet hos unge piger
 Øvelser til basalkursus, 5. uge Opgavebesvarelse: Knogledensitet hos unge piger I alt 112 piger har fået målt knogledensitet (bone mineral density, bmd) i 11-års alderen (baseline værdi). Pigerne er herefter
Øvelser til basalkursus, 5. uge Opgavebesvarelse: Knogledensitet hos unge piger I alt 112 piger har fået målt knogledensitet (bone mineral density, bmd) i 11-års alderen (baseline værdi). Pigerne er herefter
1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ
 - sammenligning af flere grupper(kvalitativ") Indhold 1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) 2 1.1 Variation indenfor og mellem grupper.......................... 2 1.2 F-test for ingen
Indhold 1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) 2 1.1 Variation indenfor og mellem grupper.......................... 2 1.2 F-test for ingen
grupper(kvalitativ exposure) Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen
 Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen") 1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen
1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen
Øvelser til basalkursus, 5. uge. Opgavebesvarelse: Knogledensitet hos unge piger
 Øvelser til basalkursus, 5. uge Opgavebesvarelse: Knogledensitet hos unge piger I alt 112 piger har fået målt knogledensitet (bone mineral density, bmd) i 11-års alderen (baseline værdi). Pigerne er herefter
Øvelser til basalkursus, 5. uge Opgavebesvarelse: Knogledensitet hos unge piger I alt 112 piger har fået målt knogledensitet (bone mineral density, bmd) i 11-års alderen (baseline værdi). Pigerne er herefter
Udleveret 1. oktober, afleveres senest ved øvelserne i uge 44 (29. oktober-1. november)
") Hjemmeopgave Basal statistik, efterår 2013 Udleveret 1. oktober, afleveres senest ved øvelserne i uge 44 (29. oktober-1. november) I forbindelse med en undersøgelse af vitamin D status i Europa, har man
Hjemmeopgave Basal statistik, efterår 2013 Udleveret 1. oktober, afleveres senest ved øvelserne i uge 44 (29. oktober-1. november) I forbindelse med en undersøgelse af vitamin D status i Europa, har man
Opgavebesvarelse, Basalkursus, uge 3
 Opgavebesvarelse, Basalkursus, uge 3 Opgave 1: Udskrivning af astma patienter (DGA s. 273) I en randomiseret undersøgelse foretaget af Storr et. al. (Lancet, i, 1987) sammenlignes effekten af en enkelt
Opgavebesvarelse, Basalkursus, uge 3 Opgave 1: Udskrivning af astma patienter (DGA s. 273) I en randomiseret undersøgelse foretaget af Storr et. al. (Lancet, i, 1987) sammenlignes effekten af en enkelt
Opgavebesvarelse, brain weight
 Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) For 20 musekuld er der i tabellen nedenfor anført oplysning om kuldstørrelsen (fra 3 til 12 mus
Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) For 20 musekuld er der i tabellen nedenfor anført oplysning om kuldstørrelsen (fra 3 til 12 mus
Hjemmeopgave, efterår 2009
 Hjemmeopgave, efterår 2009 Basal statistik for sundhedsvidenskabelige forskere Udleveret 29. september, afleveres senest ved øvelserne i uge 44 (27.-29. oktober) I alt 112 piger har fået målt bone mineral
Hjemmeopgave, efterår 2009 Basal statistik for sundhedsvidenskabelige forskere Udleveret 29. september, afleveres senest ved øvelserne i uge 44 (27.-29. oktober) I alt 112 piger har fået målt bone mineral
Module 4: Ensidig variansanalyse
 Module 4: Ensidig variansanalyse 4.1 Analyse af én stikprøve................. 1 4.1.1 Estimation.................... 3 4.1.2 Modelkontrol................... 4 4.1.3 Hypotesetest................... 6 4.2
Module 4: Ensidig variansanalyse 4.1 Analyse af én stikprøve................. 1 4.1.1 Estimation.................... 3 4.1.2 Modelkontrol................... 4 4.1.3 Hypotesetest................... 6 4.2
Muligheder: NB: test for µ 1 = µ 2 i model med blocking ækvivalent med parret t-test! Ide: anskue β j som stikprøve fra normalfordeling.
 Eksempel: dæktyper og brændstofforbrug (opgave 25 side 319) Program: cars 1 2 3 4 5... radial 4.2 4.7 6.6 7.0 6.7... belt 4.1 4.9 6.2 6.9 6.8... Muligheder: 1. vi starter med at gennemgå opgave 7 side
Eksempel: dæktyper og brændstofforbrug (opgave 25 side 319) Program: cars 1 2 3 4 5... radial 4.2 4.7 6.6 7.0 6.7... belt 4.1 4.9 6.2 6.9 6.8... Muligheder: 1. vi starter med at gennemgå opgave 7 side
Lineær regression. Simpel regression. Model. ofte bruges følgende notation:
 Lineær regression Simpel regression Model Y i X i i ofte bruges følgende notation: Y i 0 1 X 1i i n i 1 i 0 Findes der en linie, der passer bedst? Metode - Generel! least squares (mindste kvadrater) til
Lineær regression Simpel regression Model Y i X i i ofte bruges følgende notation: Y i 0 1 X 1i i n i 1 i 0 Findes der en linie, der passer bedst? Metode - Generel! least squares (mindste kvadrater) til
Opgavebesvarelse, Basalkursus, uge 3
 Opgavebesvarelse, Basalkursus, uge 3 Opgave 1: Udskrivning af astma patienter (DGA s. 273) I en randomiseret undersøgelse foretaget af Storr et. al. (Lancet, i, 1987) sammenlignes effekten af en enkelt
Opgavebesvarelse, Basalkursus, uge 3 Opgave 1: Udskrivning af astma patienter (DGA s. 273) I en randomiseret undersøgelse foretaget af Storr et. al. (Lancet, i, 1987) sammenlignes effekten af en enkelt
1 Regressionsproblemet 2
 Indhold 1 Regressionsproblemet 2 2 Simpel lineær regression 3 2.1 Mindste kvadraters tilpasning.............................. 3 2.2 Prædiktion og residualer................................. 5 2.3 Estimation
Indhold 1 Regressionsproblemet 2 2 Simpel lineær regression 3 2.1 Mindste kvadraters tilpasning.............................. 3 2.2 Prædiktion og residualer................................. 5 2.3 Estimation
Eksempel Multipel regressions model Den generelle model Estimation Multipel R-i-anden F-test for effekt af prædiktorer Test for vekselvirkning
 1 Multipel regressions model Eksempel Multipel regressions model Den generelle model Estimation Multipel R-i-anden F-test for effekt af prædiktorer Test for vekselvirkning PSE (I17) ASTA - 11. lektion
1 Multipel regressions model Eksempel Multipel regressions model Den generelle model Estimation Multipel R-i-anden F-test for effekt af prædiktorer Test for vekselvirkning PSE (I17) ASTA - 11. lektion
Mindste kvadraters tilpasning Prædiktion og residualer Estimation af betinget standardafvigelse Test for uafhængighed Konfidensinterval for hældning
 1 Regressionsproblemet 2 Simpel lineær regression Mindste kvadraters tilpasning Prædiktion og residualer Estimation af betinget standardafvigelse Test for uafhængighed Konfidensinterval for hældning 3
1 Regressionsproblemet 2 Simpel lineær regression Mindste kvadraters tilpasning Prædiktion og residualer Estimation af betinget standardafvigelse Test for uafhængighed Konfidensinterval for hældning 3
Introduktion til GLIMMIX
 Introduktion til GLIMMIX Af Jens Dick-Nielsen jens.dick-nielsen@haxholdt-company.com 21.08.2008 Proc GLIMMIX GLIMMIX kan bruges til modeller, hvor de enkelte observationer ikke nødvendigvis er uafhængige.
Introduktion til GLIMMIX Af Jens Dick-Nielsen jens.dick-nielsen@haxholdt-company.com 21.08.2008 Proc GLIMMIX GLIMMIX kan bruges til modeller, hvor de enkelte observationer ikke nødvendigvis er uafhængige.
Basal statistik for sundhedsvidenskabelige forskere, efterår 2014 Udleveret 30. september, afleveres senest ved øvelserne i uge 44 (
 Hjemmeopgave Basal statistik for sundhedsvidenskabelige forskere, efterår 2014 Udleveret 30. september, afleveres senest ved øvelserne i uge 44 (28.-30. oktober) En stor undersøgelse søger at afdække forhold
Hjemmeopgave Basal statistik for sundhedsvidenskabelige forskere, efterår 2014 Udleveret 30. september, afleveres senest ved øvelserne i uge 44 (28.-30. oktober) En stor undersøgelse søger at afdække forhold
Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06)
") Afdeling for Biostatistik Bo Martin Bibby 23. november 2006 Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06) Vi betragter 4699 personer fra Framingham-studiet. Der er oplysninger om follow-up
Afdeling for Biostatistik Bo Martin Bibby 23. november 2006 Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06) Vi betragter 4699 personer fra Framingham-studiet. Der er oplysninger om follow-up
Hvorfor bøvle med MIXED
 Hvorfor bøvle med MIXED E. Jørgensen 1 1 Genetik og Bioteknologi Danmarks Jordbrgsforskning Forskergrppe for Statistik og besltningsteori Årslev 18/01/2006 MIXED vs. GLM Lidt baggrnd Generel Lineær Model
Hvorfor bøvle med MIXED E. Jørgensen 1 1 Genetik og Bioteknologi Danmarks Jordbrgsforskning Forskergrppe for Statistik og besltningsteori Årslev 18/01/2006 MIXED vs. GLM Lidt baggrnd Generel Lineær Model
Vi vil analysere effekten af rygning og alkohol på chancen for at blive gravid ved at benytte forskellige Cox regressions modeller.
 Løsning til øvelse i TTP dag 3 Denne øvelse omhandler tid til graviditet. Et studie vedrørende tid til graviditet (Time To Pregnancy = TTP) inkluderede 423 par i alderen 20-35 år. Parrene blev fulgt i
Løsning til øvelse i TTP dag 3 Denne øvelse omhandler tid til graviditet. Et studie vedrørende tid til graviditet (Time To Pregnancy = TTP) inkluderede 423 par i alderen 20-35 år. Parrene blev fulgt i
Modul 11: Simpel lineær regression
 Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen Modul 11: Simpel lineær regression 11.1 Regression uden gentagelser............................. 1 11.1.1 Oversigt....................................
Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen Modul 11: Simpel lineær regression 11.1 Regression uden gentagelser............................. 1 11.1.1 Oversigt....................................
Generelle lineære modeller
 Generelle lineære modeller Regressionsmodeller med én uafhængig intervalskala variabel: Y en eller flere uafhængige variable: X 1,..,X k Den betingede fordeling af Y givet X 1,..,X k antages at være normal
Generelle lineære modeller Regressionsmodeller med én uafhængig intervalskala variabel: Y en eller flere uafhængige variable: X 1,..,X k Den betingede fordeling af Y givet X 1,..,X k antages at være normal
Opgave 1 Betragt to diskrete stokastiske variable X og Y. Antag at sandsynlighedsfunktionen p X for X er givet ved
 Matematisk Modellering 1 (reeksamen) Side 1 Opgave 1 Betragt to diskrete stokastiske variable X og Y. Antag at sandsynlighedsfunktionen p X for X er givet ved { 1 hvis x {1, 2, 3}, p X (x) = 3 0 ellers,
Matematisk Modellering 1 (reeksamen) Side 1 Opgave 1 Betragt to diskrete stokastiske variable X og Y. Antag at sandsynlighedsfunktionen p X for X er givet ved { 1 hvis x {1, 2, 3}, p X (x) = 3 0 ellers,
Faculty of Health Sciences. Basal Statistik. Overlevelsesanalyse. Lene Theil Skovgaard. 12. marts 2018
 Faculty of Health Sciences Basal Statistik Overlevelsesanalyse Lene Theil Skovgaard 12. marts 2018 1 / 12 APPENDIX vedr. SPSS svarende til diverse slides: Kaplan-Meier kurver, s. 3 Kumulerede incidenser
Faculty of Health Sciences Basal Statistik Overlevelsesanalyse Lene Theil Skovgaard 12. marts 2018 1 / 12 APPENDIX vedr. SPSS svarende til diverse slides: Kaplan-Meier kurver, s. 3 Kumulerede incidenser
Statistiske Modeller 1: Kontingenstabeller i SAS
 Statistiske Modeller 1: Kontingenstabeller i SAS Jens Ledet Jensen October 31, 2005 1 Indledning Som vist i Notat 1 afsnit 13 er 2 log Q for et test i en multinomialmodel ækvivalent med et test i en poissonmodel.
Statistiske Modeller 1: Kontingenstabeller i SAS Jens Ledet Jensen October 31, 2005 1 Indledning Som vist i Notat 1 afsnit 13 er 2 log Q for et test i en multinomialmodel ækvivalent med et test i en poissonmodel.
Plot af B j + ǫ ij (Y ij µ α i )): σ 2 : within blocks variance. σb 2 : between blocks variance
): σ 2 : within blocks variance. σb 2 : between blocks variance") Plot af B j + ǫ ij (Y ij µ α i )): Program: res 4 2 0 2 B1 B2 B3 B4 B5 1. vi starter med at gennemgå opgave 3 side 513. 2. nyt: to-sidet variansanalyse 1 2 3 4 5 block σ 2 : within blocks variance σb 2
Plot af B j + ǫ ij (Y ij µ α i )): Program: res 4 2 0 2 B1 B2 B3 B4 B5 1. vi starter med at gennemgå opgave 3 side 513. 2. nyt: to-sidet variansanalyse 1 2 3 4 5 block σ 2 : within blocks variance σb 2
Program. 1. Flersidet variansanalyse 1/11
 Program 1. Flersidet variansanalyse 1/11 To-sidet variansanalyse Eksempel: (opgave 14.2 side 587) vitamin indhold i frossen juice målt for ialt 9 kombinationer af mærke (Rich food, Sealed-sweet, Minute
Program 1. Flersidet variansanalyse 1/11 To-sidet variansanalyse Eksempel: (opgave 14.2 side 587) vitamin indhold i frossen juice målt for ialt 9 kombinationer af mærke (Rich food, Sealed-sweet, Minute
Besvarelse af vitcap -opgaven
 Besvarelse af -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Beskriv fordelingen af vital capacity og i de 3 grupper ved hjælp af summary statistics.
Besvarelse af -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Beskriv fordelingen af vital capacity og i de 3 grupper ved hjælp af summary statistics.
Program: 1. Repetition: p-værdi 2. Simpel lineær regression. 1/19
 Program: 1. Repetition: p-værdi 2. Simpel lineær regression. 1/19 For test med signifikansniveau α: p < α forkast H 0 2/19 p-værdi Betragt tilfældet med test for H 0 : µ = µ 0 (σ kendt). Idé: jo større
Program: 1. Repetition: p-værdi 2. Simpel lineær regression. 1/19 For test med signifikansniveau α: p < α forkast H 0 2/19 p-værdi Betragt tilfældet med test for H 0 : µ = µ 0 (σ kendt). Idé: jo større
Vi ønsker at konstruere normalområder for stofskiftet, som funktion af kropsvægten.
 Opgavebesvarelse, Resting metabolic rate I filen T:\rmr.txt findes sammenhørende værdier af kropsvægt (bw, i kg) og hvilende stofskifte (rmr, kcal pr. døgn) for 44 kvinder (Altman, 1991 og Owen et.al.,
Opgavebesvarelse, Resting metabolic rate I filen T:\rmr.txt findes sammenhørende værdier af kropsvægt (bw, i kg) og hvilende stofskifte (rmr, kcal pr. døgn) for 44 kvinder (Altman, 1991 og Owen et.al.,
Løsning til eksaminen d. 14. december 2009
 DTU Informatik 02402 Introduktion til Statistik 200-2-0 LFF/lff Løsning til eksaminen d. 4. december 2009 Referencer til Probability and Statistics for Engineers er angivet i rækkefølgen [8th edition,
DTU Informatik 02402 Introduktion til Statistik 200-2-0 LFF/lff Løsning til eksaminen d. 4. december 2009 Referencer til Probability and Statistics for Engineers er angivet i rækkefølgen [8th edition,
Basal statistik for lægevidenskabelige forskere, forår Udleveret 12. marts, afleveres senest ved øvelserne i uge 14 (2.-4.
 Hjemmeopgave Basal statistik for lægevidenskabelige forskere, forår 2013 Udleveret 12. marts, afleveres senest ved øvelserne i uge 14 (2.-4.april) I forbindelse med reagensglasbehandling blev 100 par randomiseret
Hjemmeopgave Basal statistik for lægevidenskabelige forskere, forår 2013 Udleveret 12. marts, afleveres senest ved øvelserne i uge 14 (2.-4.april) I forbindelse med reagensglasbehandling blev 100 par randomiseret
Program. Residualanalyse Flersidet variansanalyse. Opgave BK.15. Modelkontrol: residualplot
 Program Residualanalyse Flersidet variansanalyse Helle Sørensen Modelkontrol (residualanalyse) i tosidet ANOVA med vekselvirkning. Test og konklusion i tosidet ANOVA (repetition) Tresidet ANOVA: the works
Program Residualanalyse Flersidet variansanalyse Helle Sørensen Modelkontrol (residualanalyse) i tosidet ANOVA med vekselvirkning. Test og konklusion i tosidet ANOVA (repetition) Tresidet ANOVA: the works
3.600 kg og den gennemsnitlige fødselsvægt kg i stikprøven.
 PhD-kursus i Basal Biostatistik, efterår 2006 Dag 1, onsdag den 6. september 2006 Eksempel: Sammenhæng mellem moderens alder og fødselsvægt I dag: Introduktion til statistik gennem analyse af en stikprøve
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 1, onsdag den 6. september 2006 Eksempel: Sammenhæng mellem moderens alder og fødselsvægt I dag: Introduktion til statistik gennem analyse af en stikprøve
Anvendt Statistik Lektion 7. Simpel Lineær Regression
 Anvendt Statistik Lektion 7 Simpel Lineær Regression 1 Er der en sammenhæng? Plot af mordraten () mod fattigdomsraten (): Scatterplot Afhænger mordraten af fattigdomsraten? 2 Scatterplot Et scatterplot
Anvendt Statistik Lektion 7 Simpel Lineær Regression 1 Er der en sammenhæng? Plot af mordraten () mod fattigdomsraten (): Scatterplot Afhænger mordraten af fattigdomsraten? 2 Scatterplot Et scatterplot
Program. Forsøgsplanlægning og tosidet variansanalyse. Eksempel: fuldstændigt randomiseret forsøg. Forsøgstyper
 Program Forsøgsplanlægning og tosidet variansanalyse Helle Sørensen E-mail: helle@math.ku.dk I formiddag: Forsøgstyper og forsøgsplanlægning Analyse af data fra fuldstændigt randomiseret blokforsøg: tosidet
Program Forsøgsplanlægning og tosidet variansanalyse Helle Sørensen E-mail: helle@math.ku.dk I formiddag: Forsøgstyper og forsøgsplanlægning Analyse af data fra fuldstændigt randomiseret blokforsøg: tosidet
Project in Statistics MB
 Project in Statistics MB Marianne, Ditte, Stine, Gitte Niels Richard Hansen January 21, 2008 1. Besynderlig formulering. Vi kan bruge t-testet fordi vi skal sammenligne to grupper. Den hypotese vi vil
Project in Statistics MB Marianne, Ditte, Stine, Gitte Niels Richard Hansen January 21, 2008 1. Besynderlig formulering. Vi kan bruge t-testet fordi vi skal sammenligne to grupper. Den hypotese vi vil
Eksempel , opg. 2
 Faktorer En faktor er en gruppering/inddeling af målinger/observationer pga. Tilsigtede variationer i en eller flere forsøgsparametre Nødvendige (potentielle) blok-effekter såsom gentagne målinger på samme
Faktorer En faktor er en gruppering/inddeling af målinger/observationer pga. Tilsigtede variationer i en eller flere forsøgsparametre Nødvendige (potentielle) blok-effekter såsom gentagne målinger på samme
Basal statistik for sundhedsvidenskabelige forskere, forår 2015 Udleveret 3. marts, afleveres senest ved øvelserne i uge 13 (24.-25.
 Hjemmeopgave Basal statistik for sundhedsvidenskabelige forskere, forår 2015 Udleveret 3. marts, afleveres senest ved øvelserne i uge 13 (24.-25. marts) En stikprøve bestående af 65 mænd og 65 kvinder
Hjemmeopgave Basal statistik for sundhedsvidenskabelige forskere, forår 2015 Udleveret 3. marts, afleveres senest ved øvelserne i uge 13 (24.-25. marts) En stikprøve bestående af 65 mænd og 65 kvinder
Øvelser til basalkursus, 2. uge
 Øvelser til basalkursus, 2. uge Opgave 1 Vi betragter igen Sundby95-materialet, og skal nu forbedre nogle af de ting, vi gjorde sidste gang. 1. Gå ind i ANALYST vha. Solutions/Analysis/Analyst. 2. Filen
Øvelser til basalkursus, 2. uge Opgave 1 Vi betragter igen Sundby95-materialet, og skal nu forbedre nogle af de ting, vi gjorde sidste gang. 1. Gå ind i ANALYST vha. Solutions/Analysis/Analyst. 2. Filen
Basal statistik for lægevidenskabelige forskere, forår 2014 Udleveret 4. marts, afleveres senest ved øvelserne i uge 13 (25.
 Hjemmeopgave Basal statistik for lægevidenskabelige forskere, forår 2014 Udleveret 4. marts, afleveres senest ved øvelserne i uge 13 (25.-27 marts) Garvey et al. interesserer sig for sammenhængen mellem
Hjemmeopgave Basal statistik for lægevidenskabelige forskere, forår 2014 Udleveret 4. marts, afleveres senest ved øvelserne i uge 13 (25.-27 marts) Garvey et al. interesserer sig for sammenhængen mellem
MPH specialmodul Epidemiologi og Biostatistik
 MPH specialmodul Epidemiologi og Biostatistik Kvantitative udfaldsvariable 23. maj 2011 www.biostat.ku.dk/~sr/mphspec11 Susanne Rosthøj (Per Kragh Andersen) 1 Kapitelhenvisninger Andersen & Skovgaard:
MPH specialmodul Epidemiologi og Biostatistik Kvantitative udfaldsvariable 23. maj 2011 www.biostat.ku.dk/~sr/mphspec11 Susanne Rosthøj (Per Kragh Andersen) 1 Kapitelhenvisninger Andersen & Skovgaard:
1. Lav en passende arbejdstegning, der illustrerer samtlige enkeltobservationer.
 Vejledende besvarelse af hjemmeopgave Basal statistik, efterår 2008 En gruppe bestående af 45 patienter med reumatoid arthrit randomiseres til en af 6 mulige behandlinger, nemlig placebo, aspirin eller
Vejledende besvarelse af hjemmeopgave Basal statistik, efterår 2008 En gruppe bestående af 45 patienter med reumatoid arthrit randomiseres til en af 6 mulige behandlinger, nemlig placebo, aspirin eller
men nu er Z N((µ 1 µ 0 ) n/σ, 1)!! Forkaster hvis X 191 eller X 209 eller
 n/σ, 1)!! Forkaster hvis X 191 eller X 209 eller") Type I og type II fejl Type I fejl: forkast når hypotese sand. α = signifikansniveau= P(type I fejl) Program (8.15-10): Hvis vi forkaster når Z < 2.58 eller Z > 2.58 er α = P(Z < 2.58) + P(Z > 2.58) =
Type I og type II fejl Type I fejl: forkast når hypotese sand. α = signifikansniveau= P(type I fejl) Program (8.15-10): Hvis vi forkaster når Z < 2.58 eller Z > 2.58 er α = P(Z < 2.58) + P(Z > 2.58) =
Vejledende besvarelse af eksamen i Statistik for biokemikere, blok
 Opgave 1 Vejledende besvarelse af eksamen i Statistik for biokemikere, blok 2 2006 Inge Henningsen og Niels Richard Hansen Analysevariablen i denne opgave er variablen forskel, der for hver af 10 kvinder
Opgave 1 Vejledende besvarelse af eksamen i Statistik for biokemikere, blok 2 2006 Inge Henningsen og Niels Richard Hansen Analysevariablen i denne opgave er variablen forskel, der for hver af 10 kvinder
Program. Modelkontrol og prædiktion. Multiple sammenligninger. Opgave 5.2: fosforkoncentration
 Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: ekstrom@life.ku.dk Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: ekstrom@life.ku.dk Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
To samhørende variable
 To samhørende variable Statistik er tal brugt som argumenter. - Leonard Louis Levinsen Antagatviharn observationspar x 1, y 1,, x n,y n. Betragt de to tilsvarende variable x og y. Hvordan måles sammenhængen
To samhørende variable Statistik er tal brugt som argumenter. - Leonard Louis Levinsen Antagatviharn observationspar x 1, y 1,, x n,y n. Betragt de to tilsvarende variable x og y. Hvordan måles sammenhængen
Vejledende besvarelse af hjemmeopgave i Basal Statistik, forår 2014
 Vejledende besvarelse af hjemmeopgave i Basal Statistik, forår 2014 Garvey et al. interesserer sig for sammenhængen mellem anæstesi og allergiske reaktioner (se f.eks. nedenstående reference, der dog ikke
Vejledende besvarelse af hjemmeopgave i Basal Statistik, forår 2014 Garvey et al. interesserer sig for sammenhængen mellem anæstesi og allergiske reaktioner (se f.eks. nedenstående reference, der dog ikke
Epidemiologi og Biostatistik
 Kapitel 1, Kliniske målinger Epidemiologi og Biostatistik Introduktion til skilder (varianskomponenter) måleusikkerhed sammenligning af målemetoder Mogens Erlandsen, Institut for Biostatistik Uge, torsdag
Kapitel 1, Kliniske målinger Epidemiologi og Biostatistik Introduktion til skilder (varianskomponenter) måleusikkerhed sammenligning af målemetoder Mogens Erlandsen, Institut for Biostatistik Uge, torsdag
Analysestrategi. Lektion 7 slides kompileret 27. oktober 200315:24 p.1/17
 nalysestrategi Vælg statistisk model. Estimere parametre i model. fx. lineær regression Udføre modelkontrol beskriver modellen data tilstrækkelig godt og er modellens antagelser opfyldte fx. vha. residualanalyse
nalysestrategi Vælg statistisk model. Estimere parametre i model. fx. lineær regression Udføre modelkontrol beskriver modellen data tilstrækkelig godt og er modellens antagelser opfyldte fx. vha. residualanalyse
k normalfordelte observationsrækker (ensidet variansanalyse)
") k normalfordelte observationsrækker (ensidet variansanalyse) Lad x ij, i = 1,...,k, j = 1,..., n i, være udfald af stokastiske variable X ij og betragt modellen M 1 : X ij N(µ i, σ 2 ). Estimaterne er
k normalfordelte observationsrækker (ensidet variansanalyse) Lad x ij, i = 1,...,k, j = 1,..., n i, være udfald af stokastiske variable X ij og betragt modellen M 1 : X ij N(µ i, σ 2 ). Estimaterne er
Hvad skal vi lave? Model med hovedvirkninger Model med vekselvirkning F-test for ingen vekselvirkning. 1 Kovariansanalyse. 2 Sammenligning af modeller
 Hvad skal vi lave? 1 Kovariansanalyse Model med hovedvirkninger Model med vekselvirkning F-test for ingen vekselvirkning 2 Sammenligning af modeller 3 Mere generelle modeller PSE (I17) ASTA - 14. lektion
Hvad skal vi lave? 1 Kovariansanalyse Model med hovedvirkninger Model med vekselvirkning F-test for ingen vekselvirkning 2 Sammenligning af modeller 3 Mere generelle modeller PSE (I17) ASTA - 14. lektion
Flerniveau modeller. Individuelt studieforløb. Efterårssemesteret 2002. Folkesundhedsvidenskab ved Københavns Universitet
 Individuelt studieforløb Efterårssemesteret 2002 Flerniveau modeller Folkesundhedsvidenskab ved Københavns Universitet Vejleder: Jørgen Holm Petersen Eksamensnummer 20 Indholdsfortegnelse 1. Indledning...3
Individuelt studieforløb Efterårssemesteret 2002 Flerniveau modeller Folkesundhedsvidenskab ved Københavns Universitet Vejleder: Jørgen Holm Petersen Eksamensnummer 20 Indholdsfortegnelse 1. Indledning...3
Opgavebesvarelse, brain weight
 Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) For 20 nyfødte mus er der i tabellen nedenfor anført oplysning om kuldstørrelsen (fra 3 til 12
Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) For 20 nyfødte mus er der i tabellen nedenfor anført oplysning om kuldstørrelsen (fra 3 til 12
Multipel Lineær Regression
 Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk model Specificer
Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk model Specificer
Eksamen ved. Københavns Universitet i. Kvantitative forskningsmetoder. Det Samfundsvidenskabelige Fakultet
 Eksamen ved Københavns Universitet i Kvantitative forskningsmetoder Det Samfundsvidenskabelige Fakultet 14. december 2011 Eksamensnummer: 5 14. december 2011 Side 1 af 6 1) Af boxplottet kan man aflæse,
Eksamen ved Københavns Universitet i Kvantitative forskningsmetoder Det Samfundsvidenskabelige Fakultet 14. december 2011 Eksamensnummer: 5 14. december 2011 Side 1 af 6 1) Af boxplottet kan man aflæse,
Det kunne godt se ud til at ikke-rygere er ældre. Spredningen ser ud til at være nogenlunde ens i de to grupper.
 1. Indlæs data. * HUSK at angive din egen placering af filen; data framing; infile '/home/sro00/mph2016/framing.txt' firstobs=2; input id sex age frw sbp sbp10 dbp chol cig chd yrschd death yrsdth cause;
1. Indlæs data. * HUSK at angive din egen placering af filen; data framing; infile '/home/sro00/mph2016/framing.txt' firstobs=2; input id sex age frw sbp sbp10 dbp chol cig chd yrschd death yrsdth cause;
Dansk Erhvervs gymnasieanalyse Sådan gør vi
 METODENOTAT Dansk Erhvervs gymnasieanalyse Sådan gør vi FORMÅL Formålet med analysen er at undersøge, hvor dygtige de enkelte gymnasier er til at løfte elevernes faglige niveau. Dette kan man ikke undersøge
METODENOTAT Dansk Erhvervs gymnasieanalyse Sådan gør vi FORMÅL Formålet med analysen er at undersøge, hvor dygtige de enkelte gymnasier er til at løfte elevernes faglige niveau. Dette kan man ikke undersøge
Opgave 1: Graft vs. Host disease
 Opgave 1: Graft vs. Host disease Denne opgave er baseret på opgave 12.3 fra DG Altman, p. 361. Data omhandler knoglemarvstransplantation af 37 leukæmipatienter, og outcome er forekomst af graft versus
Opgave 1: Graft vs. Host disease Denne opgave er baseret på opgave 12.3 fra DG Altman, p. 361. Data omhandler knoglemarvstransplantation af 37 leukæmipatienter, og outcome er forekomst af graft versus
Eksamen i Statistik for biokemikere. Blok
 Eksamen i Statistik for biokemikere. Blok 2 2007. Vejledende besvarelse 22-01-2007, Niels Richard Hansen Bemærkning: Flere steder er der givet en argumentation (f.eks. baseret på konfidensintervaller)
Eksamen i Statistik for biokemikere. Blok 2 2007. Vejledende besvarelse 22-01-2007, Niels Richard Hansen Bemærkning: Flere steder er der givet en argumentation (f.eks. baseret på konfidensintervaller)
Opgavebesvarelse, brain weight
 Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) Spørgsmål 1 Data er indlagt på T:/Basalstatistik/brain.txt og kan indlæses direkte i Analyst med
Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) Spørgsmål 1 Data er indlagt på T:/Basalstatistik/brain.txt og kan indlæses direkte i Analyst med
Klasseøvelser dag 2 Opgave 1
 Klasseøvelser dag 2 Opgave 1 1.1. Vi sætter først working directory og data indlæses: library( foreign ) d
Klasseøvelser dag 2 Opgave 1 1.1. Vi sætter først working directory og data indlæses: library( foreign ) d
Statistik Lektion 4. Variansanalyse Modelkontrol
 Statistik Lektion 4 Variansanalyse Modelkontrol Eksempel Spørgsmål: Er der sammenhæng mellem udetemperaturen og forbruget af gas? Y : Forbrug af gas (gas) X : Udetemperatur (temp) Scatterplot SPSS: Estimerede
Statistik Lektion 4 Variansanalyse Modelkontrol Eksempel Spørgsmål: Er der sammenhæng mellem udetemperaturen og forbruget af gas? Y : Forbrug af gas (gas) X : Udetemperatur (temp) Scatterplot SPSS: Estimerede
Hypotesetest. Altså vores formodning eller påstand om tingens tilstand. Alternativ hypotese (hvis vores påstand er forkert) H a : 0
 H a : 0") Hypotesetest Hypotesetest generelt Ingredienserne i en hypotesetest: Statistisk model, f.eks. X 1,,X n uafhængige fra bestemt fordeling. Parameter med estimat. Nulhypotese, f.eks. at antager en bestemt
Hypotesetest Hypotesetest generelt Ingredienserne i en hypotesetest: Statistisk model, f.eks. X 1,,X n uafhængige fra bestemt fordeling. Parameter med estimat. Nulhypotese, f.eks. at antager en bestemt
ISCC. IMM Statistical Consulting Center. Brugervejledning til beregningsmodul til robust estimation af nugget effect. Technical University of Denmark
 IMM Statistical Consulting Center Technical University of Denmark ISCC Brugervejledning til beregningsmodul til robust estimation af nugget effect Endelig udgave til Eurofins af Christian Dehlendorff 15.
IMM Statistical Consulting Center Technical University of Denmark ISCC Brugervejledning til beregningsmodul til robust estimation af nugget effect Endelig udgave til Eurofins af Christian Dehlendorff 15.
Reeksamen i Statistik for Biokemikere 6. april 2009
 Københavns Universitet Det Naturvidenskabelige Fakultet Reeksamen i Statistik for Biokemikere 6. april 2009 Alle hjælpemidler er tilladt, og besvarelsen må gerne skrives med blyant. Opgavesættet er på
Københavns Universitet Det Naturvidenskabelige Fakultet Reeksamen i Statistik for Biokemikere 6. april 2009 Alle hjælpemidler er tilladt, og besvarelsen må gerne skrives med blyant. Opgavesættet er på
Statistik Lektion 20 Ikke-parametriske metoder. Repetition Kruskal-Wallis Test Friedman Test Chi-i-anden Test
 Statistik Lektion 0 Ikkeparametriske metoder Repetition KruskalWallis Test Friedman Test Chiianden Test Run Test Er sekvensen opstået tilfældigt? PPPKKKPPPKKKPPKKKPPP Et run er en sekvens af ens elementer,
Statistik Lektion 0 Ikkeparametriske metoder Repetition KruskalWallis Test Friedman Test Chiianden Test Run Test Er sekvensen opstået tilfældigt? PPPKKKPPPKKKPPKKKPPP Et run er en sekvens af ens elementer,
Program. Konfidensinterval og hypotesetest, del 2 en enkelt normalfordelt stikprøve I SAS. Øvelse: effekt af diæter
 Program Konfidensinterval og hypotesetest, del 2 en enkelt normalfordelt stikprøve Helle Sørensen E-mail: helle@math.ku.dk I formiddag: Øvelse: effekt af diæter. Repetition fra sidst... Parrede og ikke-parrede
Program Konfidensinterval og hypotesetest, del 2 en enkelt normalfordelt stikprøve Helle Sørensen E-mail: helle@math.ku.dk I formiddag: Øvelse: effekt af diæter. Repetition fra sidst... Parrede og ikke-parrede