1. Lav en passende arbejdstegning, der illustrerer samtlige enkeltobservationer.
|
|
|
- Sidsel Nørgaard
- 8 år siden
- Visninger:
Transkript
1 Vejledende besvarelse af hjemmeopgave Basal statistik, efterår 2008 En gruppe bestående af 45 patienter med reumatoid arthrit randomiseres til en af 6 mulige behandlinger, nemlig placebo, aspirin eller en af 4 doser af et aktivt anti-inflammatorisk stof, her kaldet X. Der anvendes et samlet index (Index) til beskrivelse af behandlingens effektivitet (et mål for en samlet forbedring af symptomerne), som er listet som talværdier under de enkelte 6 grupper. 1. Lav en passende arbejdstegning, der illustrerer samtlige enkeltobservationer. En passende arbejdstegning kan f.eks. være at plotte data i et scatterplot, så man kan få et overblik over data inden der udføres analyser. En plot af data kan også give ideer til den videre analyse af data. Der kan uddrages følgende ting af scatterplottet : 1

2 Placebo har ca. samme værdier som behandlingen med Dose 1 (D1) af X, endda ligger Placebo måske en smule højere, det må vurderes ved nærmere analyse. Aspirin-behandlingen ser ud til på plottet at placere sig et sted i mellem Dose 2 af X (D2)og Dose 3 af X (D3), mest i nærheden af Dose 2. De 4 behandlinger med X i 4 forskellelige doser ser ud til at samle sig om en ret linie. Man kunne også have valgt at lave et boxplot som arbejdstegning, men i det aktuelle tilfælde med forholdsvis få observationer (45) er et scatterplot er bedre valg, da man kan se alle observationer på dette plot. 2. Lav en ensidet-variansanalyse til vurdering af om der er forskel på de 6 grupper. Selve beregningen suppleres selvfølgelig med en passende fortolkning af resultatet. Index-niveauet i grupperne sammenlignes vha. en ensidet variansanalyse. Her testes hypotesen µ PLA = µ ASP = µ d1 = µ d2 = µ d3 = µ d4 der siger at alle grupper har samme middelværdi. I Analyst kan dette f.eks gøres under Statistics / ANOVA / One- Way ANOVA. Index vægles som Dependent og gruppe som Independent. Output: The ANOVA Procedure Class Level Information Class Levels Values 2
 er et scatterplot er bedre valg, da man kan se alle observationer på")
3 gruppe 6 as d1 d2 d3 d4 p Number of Observations Read 45 Number of Observations Used 45 The ANOVA Procedure Dependent Variable: index Sum of Source DF Squares Mean Square F Value Pr > F Model <.0001 Error Corrected Total R-Square Coeff Var Root MSE index Mean Source DF Anova SS Mean Square F Value Pr > F gruppe <.0001 P-værdien for gruppe er < , dvs hypotesen forkastes. Middelværdien i de 6 grupper kan ikke antages at være ens. 3. Kontrol af model fra spg. 2. Er normalfordelingsantagelsen fornuftig? Er der varianshomogenitet? Følgende antagelser skal kunne siges at være opfyldt for at vi kan benytte resultatet fra den ensidede-variansanalyse: Observationerne skal kunne antages at være indbyrdes uafhængige. Observationerne skal kunne antages at være normalfordelte. Observationerne skal kunne antages at have samme varians σ antagelse Hvis observationerne skal kunne antages at være indbyrdes uafhængige, kræver det, at disse mennesker kun optræder en gang i forsøget, og at de ikke er indbyrdes i familie. I opgaveteksten er der ikke oplyst noget om dette, så vi må antage, at observationerne kan antages at være 3

4 indbyrdes uafhængige. 2. antagelse Observationerne kan antages at være normalfordelte, hvis fraktildiagrammer ser fornuftige ud. Vi starter med at lave et diagram særskilt for hver behandling, men man kan også lave en fælles tegning efter fratrækning af gruppegennemsnit ( dvs. af residualerne ). 4

5 5
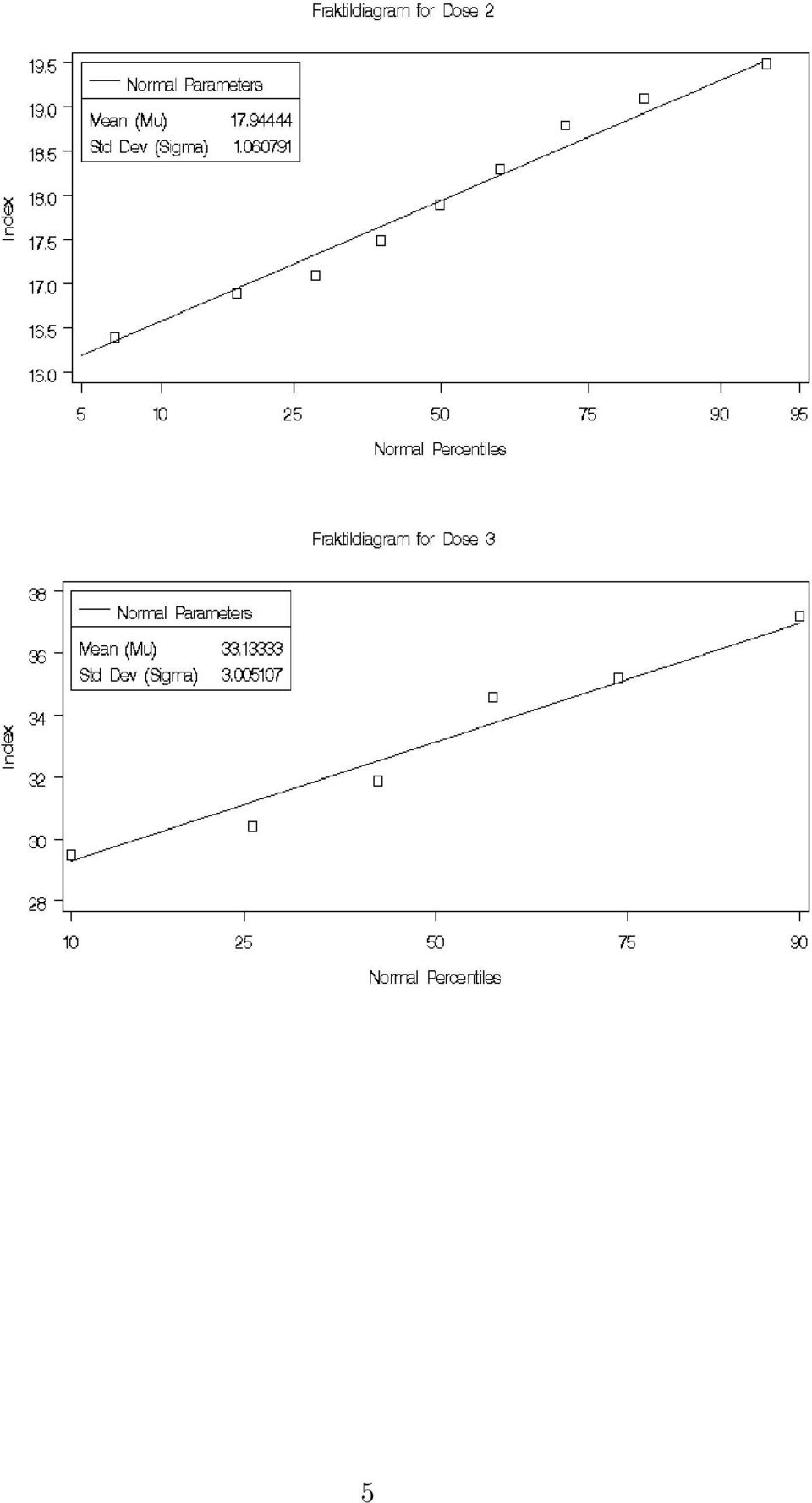
6 Alle de 6 fraktildiagrammer ser pæne ud, men det ses, at de behandlinger med flest observationer (Aspirin, Placebo og Dose 2) ligger pæntest omkring normalfordelings-linien, mens de behandlinger med få observationer (Dose 1, 2 og 4) ligger mere spredt i forhold til linien. Dette er ganske naturligt, idet det afspejler sensitiviteten overfor enkeltobservationer i datamaterialet. Istedet for at opdele efter behandling kunne man også have lavet en fælles tegning efter fratrækning af gruppegennemsnit ( dvs. af residualerne ). Med denne metode er der observationer nok til at det giver 6
.")
7 mening at lave et histogram. Et sådant er derfor inkluderet nedenfor: Igen ses en god overensstemmelse med normalfordelingen. Det kan derfor antages, at observationerne i hver gruppe følger en normalfordeling. Test for normalfordeling er også en mulighed til at afgøre dette spørgsmål, så nedenfor følger et test for normalfordeling, testet laves igen for hver gruppe for sig. The UNIVARIATE Procedure Fitted distribution for Index Behandling = Asp Parameters for Mormal Distribution Parameter Symbol Estimate Mean Mu Std Dev Sigma Goodness-of-fit Tests for Normal Distribution Test Statistic p Value Kolmogorov-Smirnov D PR > D >0.150 Cramer-von Mises W-sq Pr > W-sq >0.250 Anderson-Darling A-sq Pr > A-sq >

8 Behandling = Pla Parameters for Mormal Distribution Parameter Symbol Estimate Mean Mu Std Dev Sigma Goodness-of-fit Tests for Normal Distribution Test Statistic p Value Kolmogorov-Smirnov D PR > D >0.150 Cramer-von Mises W-sq Pr > W-sq >0.250 Anderson-Darling A-sq Pr > A-sq >0.250 Behandling = D1 Parameters for Mormal Distribution Parameter Symbol Estimate Mean Mu 5.96 Std Dev Sigma Goodness-of-fit Tests for Normal Distribution Test Statistic p Value Kolmogorov-Smirnov D PR > D >0.150 Cramer-von Mises W-sq Pr > W-sq >0.250 Anderson-Darling A-sq Pr > A-sq >0.250 Behandling = D2 Parameters for Mormal Distribution Parameter Symbol Estimate Mean Mu Std Dev Sigma Goodness-of-fit Tests for Normal Distribution Test Statistic p Value Kolmogorov-Smirnov D PR > D >0.150 Cramer-von Mises W-sq Pr > W-sq >0.250 Anderson-Darling A-sq Pr > A-sq >0.250 Behandling = D3 Parameters for Mormal Distribution 8

9 Parameter Symbol Estimate Mean Mu Std Dev Sigma Goodness-of-fit Tests for Normal Distribution Test Statistic p Value Kolmogorov-Smirnov D PR > D >0.150 Cramer-von Mises W-sq Pr > W-sq >0.250 Anderson-Darling A-sq Pr > A-sq >0.250 Behandling = D4 Parameters for Mormal Distribution Parameter Symbol Estimate Mean Mu Std Dev Sigma Goodness-of-fit Tests for Normal Distribution Test Statistic p Value Kolmogorov-Smirnov D PR > D >0.150 Cramer-von Mises W-sq Pr > W-sq >0.250 Anderson-Darling A-sq Pr > A-sq >0.250 På disse test for normalfordeling ses det, at de enkelte grupper kan antages at følge en normalfordeling 9

10 3. antagelse Antagelsen om ens varianser kan testes ved hjælp af Levene s test. Dette bør gøres sammen med variansanalysen i Analyst under A- NOVA / One-Way ANOVA / Test : Levene s test for varianshomogenitet ser på hypotesen : σ 2 PLA = σ2 ASP = σ2 D1 = σ2 D2 = σ2 D3 = σ2 D4 og giver her følgende resultat : The ANOVA Procedure Levene s Test for Homogeneity of index Variance ANOVA of Squared Deviations from Group Means Sum of Mean Source DF Squares Square F Value Pr > F gruppe Error Med en p-værdi på kan hypotesen ikke afvises. Vi konkludere og at de 6 varianser ikke er signifikant forskellige. Dette er i overensstemmelse med kravet om varianshomogenitet. Ser vi på scatterplottet på s.1, ser vi, at specielt Dose 1 og Dose 2 har ret små varianser i forhold til de andre grupper. Ifølge Levene s tests kunne disse afvigelser godt være opstået tilfældigt. Istedet for at benytte Levene s test kunne vi have valgt Bartlett s test eller Brown-Forsythe test for varianshomogenitet. Begge disse test giver forkast af hypotesen. Er man usikker på om varianshomogeniteten holder kan man istedet teste hypotesen om ens middelværdier ved et såkladt Welch-test, Testet findes i Analyst under ANOVA / One-Way ANOVA / Test. The VAR Procedure Dependent Variable: Index Welsh s ANOVA for Index 10

11 DF F Value Pr > F Gruppe <.0001 Error Dette Welsh-test giver ligeledes, at der er en klar forskel på de 6 behandlinger (p < ). Ved et Krushal-Wallis-test er det muligt at teste forskel på flere grupper uden at have en antagelse om, at data følger en normalfordeling. Da denne antagelse i dette tilfælde imidlertid er opfyldt, er det ikke relevant at anvende et Krushal-Wallis-test i dette tilfælde. 4. Sammenlign niveauet i placebo-gruppen med aspirin-gruppen. Her er der to muligheder. Enten kan vi bruge et uparret t-test eller også kan vi bruge ANOVA-modellen for alle 6 grupper. Hvis ANOVAmodellens forudsætninger er opfyldt er det bedre at bruge outputtet fra denne model. Analysen er stærkere end for et uparret t-test fordi ANOVA-modellen benytter information fra alle grupper til at estimere den fælles varians. Vi har tidligere set at ANOVA-modellen antagelser er nogenlunde opfyldt, men her benyttes begge metoder: Vi stater med det uparrede t-test: Uparret t-test i Analyst: under Hypothesis Tests / Two-Sample t-test for Means fåes følgende størrelser: T-test procedure Dependent Variable: Index Sample Statistics Group N Mean Std.Dev Std Error Asp Pla Hypothesis Test : Null Hypothesis : MEAN(ASP) - MEAN(PLA) = 0 Alternative : MEAN(ASP) - MEAN(PLA) 0 If Variances Are t statistic Df PR > t Equal <.0001 Not Equal < % Confidence Interval for the Difference between Two Means : 11

12 ( 12.25, ) Med denne analyses P-værdier ses det, at hypotesen om, at de 2 middelværdier er ens må forkastes, og der er dermed forskel på de 2 grupper. Fra scatterplottet og middelværdierne ses det, at det er Aspirin, der har de største Index-værdier. Forskellen på de 2 grupper estimeres til : = Med et konfidensinterval på : ( 12.25, ) Man kan se på konfidensintervallet, at der er klar forskel på de 2 grupper. For at få analyseret forskellen i ANOVA- modellen klikkes Statistics / ANOVA / Linear Models. Herefter Statistics / Parameter Estimates. Endelig går jeg ud i koden og tilføjer clparm i linjen model index=gruppe / solution clparm; Del af output: Standard Parameter Estimate Error t Value Pr > t 95% Confidence Limits Intercept B < gruppe as B < gruppe d B gruppe d B < gruppe d B < gruppe d B < gruppe p B..... I overensstemmelse med det uparrede t-test ses at Aspirin-gruppen ligger 14.6 endheder over placebo og at denne forskel er statistisk signifikant (p < ). Sikkerhedsintervallet er her (12.63; 16.63), dvs lidt smallere end med det uparrede t-test. 5. Sammenlign niveauet i placebo-gruppen med henholdsvis Dose 1 og Dose 4-gruppen. Her benytter jeg output fra ANOVA-modellen. Jeg kunne også have valgt to uparrede t-test, men fordi forudsætningerne i ANOVAmodellen ser ud til at være opfyldt benytter jeg den. 12

13 Standard Parameter Estimate Error t Value Pr > t 95% Confidence Limits Intercept B < gruppe as B < gruppe d B gruppe d B < gruppe d B < gruppe d B < gruppe p B..... Heraf ses Placebo gruppen ligger 2.66 (95% CI: 0.180; 5.14) over D1-gruppen. Forskellen er statistisk signifikant med en p-værdi på D4-gruppen ligger (95% CI: 32.58; 37.54) over placebo-gruppen. Forskellen er statistisk signifikant med en p-værdi på < Korrektion for multipel testning: Opgaveteksten specificerer at det netop drejer sig om disse to sammenligninger: placebo mod d1 og d4. Det er derfor forkert at lave en Bonferroni-korrektion for de ialt 15 sammenligninger vi kunne have lavet. Det eneste Bonferroni-korrektionen gør er at p-værdierne ganges op med antallet af udførte tests. Her har vi lavet to tests, så hvis man vil korrigere for multipel testning er det mere rigtigt kun at gange med For de 4 grupper, der har modtaget det aktive stof X ønskes en beskrivelse af dosisafhængigheden: (a) Giv et estimat for effekten af en 10 mg forøgelse af dosis, baseret på en antagelse om en lineær sammenhæng mellem index og dosis. Som tidligere bemærket ser der ud til at være pæn linearitet mellem dosis af medicin X og Index. Først laves der derfor en ny variabel Dosis, der angiver hvilken dosis af medicin X den enkelte person har modtaget. Herunder er der et scatterplot, hvor Index er tegnet mod Dosis (NB Dosis=0 er Placebo-gruppen, og den medtages ikke i analysen i første omgang). 13
 over D1-gruppen. Forskellen er statistisk signifikant med en p-værdi på 0.036. D4-gruppen ligger 35.05 (95% CI: 32.58; 37.54) over placebo-gruppen.")

14 På baggrund af dette plot opstilles der nu en lineær regressionsmodel : Modellen er : Y i = α + βx i + ε i, ε i N(0, σ 2 ) hvor Y i er Index hvor X i er Dosis hvor α er skæringen med Y-aksen hvor β er hældningen af linien hvor ε i er afstanden til linien målt lodret På baggrund af denne model laves der regressionsanalysen i Analyst under Statistics / Regression / Linear. Herved får man følgende output : The REG Procedure Dependent Variable: Index Analysis of Variance Sum of Mean Source DF Squares Square F Value Pr > F Model <.0001 Error Corrected Total

15 Root MSE R-Square Coeff Var Parameter Estimates Parameter Standard Variable Df Estimate Error t Value Pr> t Intercept <.0001 Dosis < % Confidence Limits for Intercept : , % Confidence Limits for Dosis : , 2,75078 Dermed fremkommer der estimater for både hældningen β (Dosis) og skæringen α (Intercept) i modellen, og det er nu muligt at beregne et estimat for effekten af en 10 mg s forøgelse af dosis. Vi har vores model : Y i = α + βx i + ε i Her svarer ˆβ til et estimat for ændringen på 1 mg af dosis, dvs hver gang dosis vokser med 1 mg forventer vi at Index vokser med Et estimat for effekten af en 10 mg s forøgelse af dosis fås som 10 ˆβ = Konfidensinterval for 10 ˆβ : ( , ) Der skal her bemærkes at der selvfølelig bør lave modelkontrol for den lineære regression i form af residualplot osv. Residualerne ændrer sig når modellen ændres, dvs vi kan ikke bare henvise til resultaterne fra spørgsmål 3. Lineariteten testes i spørgsmål 6b. Residualplots er angivet nedenfor og de viser ikke tegn på at modellen skulle være misspecificeret. Dog ses af fraktil-diagrammet at residualernes fordeling passer lidt dårligere med normalfordelingsantagelsen end i spg 3, hvor vi ikke krævede en lineær sammenhæng mellem gruppe-niveauerne. 15

16 (b) Kan en lineær dosiseffekt forklare hele forskellen på de 4 aktivt behandlede grupper? Denne analyse er lidt speciel, men den er meget anvendelig og god at kende. Til analysen anvendes kun observationer for behandling med X, som under forrige spørgsmål, og man anvender desuden den nye variabel Dosis. Testet laves i Analyst under ANOVA / Linear Models. Index er stadig den afhængige, så den placeres i Dependent, og Gruppe sættes under Class, og til sidst sættes Dosis under Quantitative. Dette vil give et test af linearitet mellem Dosis og Index, idet man vurderer, om Gruppe kan testes væk. The GLM Procedure Class Level Information Class Levels Values Gruppe 4 d1,d2,d3,d4 Number of observations 25 Dependent Variable : Index Sum of Source DF Squares Mean Square F Value Pr> F Model <.0001 Error

17 Corrected Total R-Square Coeff Var Root MSE Index Mean Source DF Type III SS Mean Square F Value Pr> F Gruppe Dosis Det man skal kigge under, er Type III SS testet, hvor der er en p-værdi på for Gruppe, så det vil sige, at det er lige på kanten af, at en lineær dosiseffekt kan forklare hele forskellen. NB Hvis man ser på R 2 for den lineære regression, så er R 2 = , og så kunne man argumentere, at med denne R 2 -værdi, så er langt det meste af forskellen mellem de 4 aktivt-behandlede grupper forklaret ved den lineære regression. Dette er imidlertid en forkert tolkning, da R 2 er afhængig af fordelingen af X-værdier, og dermed af datasættets design. Formel for R 2 (jævnfør overheadkopier fra 5. forelæsning : Regressionsanalyse ) : 1 R 2 xy = s 2 s 2 + ˆβ 2 s xx n 2 Hvis ˆβ 2 og s 2 fastholdes, ses følgende : Hvis s xx er stor, bliver 1 R 2 xy er tæt på 0 og dermed bliver R2 xy tæt på 1. Heraf ses, at R 2 xy kan gøres vilkårlig tæt på 1 ved at sprede x-erne. Det betyder, at korrelationen er meningsløs, når x-værdierne styres, og der er jo tilfældet her, hvor Dosis-værdien = x-værdien er selvvalgt. (c) Estimer index-niveauet ved dosis 0. Angiv sikkerhedsinterval. Interceptet angiver Index niveau ved dosis 0. Fra outputtet aflæses direkte 17

18 Intercept= og 95% Confidence Limits for Intercept : ( ; ) Vi har ingen data under dosis 10mg, vores estimat er derfor baseret på en ekstrapolation. (d) Passer placebo-gruppen ind i antagelsen om en lineær dosisafhængighed? Eftersom placebo-gruppen ingen medicin har taget, burde et estimat for denne gruppes middelværdi være mindre end den estimerede middelværdi for Dose 1-gruppen, men allerede fra scatterplottet ses, at dette ikke er tilfældet. Endvidere har vi set at placebo-gruppen klarer sig (signifikant) bedre end den laveste dosis-gruppe. Konklusionen må derfor være, at placebo-gruppen ikke passer ind i antagelsen om en lineær afhængighed. 7. Tilsidst sammenlignes aspirin-behandling med X-behandling: (a) Sammenlign niveauet aspirin-gruppen med hver af de fire X-dosis grupper. Her benytter jeg igen ANOVA-modellen med alle grupper. Alternativt kunne jeg have lavet 4 uparrede t-tests. I ANOVA-outputtet vælger SAS placebo-gruppen som reference, men jeg vil jo sammenligne Aspirin-gruppen med 4 andre grupper. Jeg vælger derfor et nyt navn til Aspirin-gruppen: z:aspiri. Herved bliver Aspirin-gruppen valgt som reference-gruppe: Standard Parameter Estimate Error t Value Pr > t Intercept B <.0001 gruppe placebo B <.0001 gruppe x B <.0001 gruppe x B <.0001 gruppe x B <.0001 gruppe x B <.0001 gruppe z:aspiri B... Parameter 95% Confidence Limits 18
 bedre end den laveste dosis-gruppe.")
19 Intercept gruppe placebo gruppe x gruppe x gruppe x gruppe x gruppe z:aspiri.. Estimeret forskel mellem dosis 10 gruppen og Aspirin-gruppen er med sikkerhedsinterval ( 19.70; 14.89). Forskellen er stærkt signifikant (p < ). Estimeret forskel mellem dosis 15 gruppen og Aspirin-gruppen er med sikkerhedsinterval ( 7.31; 3.31). Forskellen er stærkt signifikant (p < ). Estimeret forskel mellem dosis 20 gruppen og Aspirin-gruppen er 9.88 med sikkerhedsinterval (7.62; 12.14). Forskellen er stærkt signifikant (p < ). Estimeret forskel mellem dosis 25 gruppen og Aspirin-gruppen er med sikkerhedsinterval (18.02; 22.83). Forskellen er stærkt signifikant (p < ). Hvis man skulle korrigere for multipel testning kunne man gange p-værdierne med 4. Det ville ændre ikke konklusionerne. (b) Hvilken X-dosis svarer aspirin-behandlingen til? Resultaterne i 7a viser at aspirin-behandlingen svarer til en X- dosis mellem 15 og 20 mg. Et mere præcist estimat kan opnås ved at benytte den estimerede lineære sammenhæng mellem dosis og index, som vi fandt i spørgsmål 6: index = dosis Index-niveauet i aspirin-gruppen er For at finde dosis svarende til denne respons skal vi altså løse ligningen: = dosis, hvilket giver: dosis = ( )/2.58 = 16.78mg 19
. Forskellen er stærkt signifikant (p < 0.0001).")
20 En korrekt beregning af et sikkerhedsinterval for denne dosis kræver at der tages hensyn til estimations-usikkerheden i asprin-niveauet, interceptet samt hældningsestimatet. En sådan beregning ligger u- denfor rammerne af dette kursus. Samlet konklusion om aspirinbehandlingen af reumatoid arthrit: Ud fra de analyser, der er gennemgået tidligere i denne opgave i spm 2, kan man sige, at aspirinbehandling af reumatoid arthrit for Index-værdien virker omtrent som en mellemting mellem Dose 2 og Dose 3, og den ligger klart over placebo. Hvis f.eks. X er et nyt og dyrt behandlingsmiddel i forhold til aspirin, er det en opvejning af ø- konomi og forbedringen af helbredstilstanden hos den enkelte person, men aspirin kan med fordel bruges som erstatning for X ved de lettere symptomer på baggrund af analyserne i denne opgave. Reference: Woolson, R.F. & Clarke, W.R.: Statistical methods for the analysis of biomedical data. 2ed., Wiley, 2002 (Opgave 10.4 side 409) 20

Variansanalyse i SAS. Institut for Matematiske Fag December 2007
 Københavns Universitet Statistik for Biokemikere Det naturvidenskabelige fakultet Institut for Matematiske Fag December 2007 Variansanalyse i SAS 2 Tosidet variansanalyse Residualplot Tosidet variansanalyse
Københavns Universitet Statistik for Biokemikere Det naturvidenskabelige fakultet Institut for Matematiske Fag December 2007 Variansanalyse i SAS 2 Tosidet variansanalyse Residualplot Tosidet variansanalyse
Lineær regression. Simpel regression. Model. ofte bruges følgende notation:
 Lineær regression Simpel regression Model Y i X i i ofte bruges følgende notation: Y i 0 1 X 1i i n i 1 i 0 Findes der en linie, der passer bedst? Metode - Generel! least squares (mindste kvadrater) til
Lineær regression Simpel regression Model Y i X i i ofte bruges følgende notation: Y i 0 1 X 1i i n i 1 i 0 Findes der en linie, der passer bedst? Metode - Generel! least squares (mindste kvadrater) til
Besvarelse af vitcap -opgaven
 Besvarelse af -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Beskriv fordelingen af vital capacity og i de 3 grupper ved hjælp af summary statistics.
Besvarelse af -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Beskriv fordelingen af vital capacity og i de 3 grupper ved hjælp af summary statistics.
Opgaver til ZAR II. Afdeling for Anvendt Matematik og Statistik Michael Sørensen Oktober Opgave 1
 Københavns Universitet Afdeling for Anvendt Matematik og Statistik Statistik for biokemikere Inge Henningsen Michael Sørensen Oktober 2003 Opgaver til ZAR II Opgave 1 Et datasæt består af 20 observationer.
Københavns Universitet Afdeling for Anvendt Matematik og Statistik Statistik for biokemikere Inge Henningsen Michael Sørensen Oktober 2003 Opgaver til ZAR II Opgave 1 Et datasæt består af 20 observationer.
Kommentarer til opg. 1 og 3 ved øvelser i basalkursus, 3. uge
 Kommentarer til opg. 1 og 3 ved øvelser i basalkursus, 3. uge Opgave 1. Data indlæses i 3 kolonner, som f.eks. kaldessalt,pre ogpost. Der er således i alt tale om 26 observationer, idet de to grupper lægges
Kommentarer til opg. 1 og 3 ved øvelser i basalkursus, 3. uge Opgave 1. Data indlæses i 3 kolonner, som f.eks. kaldessalt,pre ogpost. Der er således i alt tale om 26 observationer, idet de to grupper lægges
k normalfordelte observationsrækker (ensidet variansanalyse)
") k normalfordelte observationsrækker (ensidet variansanalyse) Lad x ij, i = 1,...,k, j = 1,..., n i, være udfald af stokastiske variable X ij og betragt modellen M 1 : X ij N(µ i, σ 2 ). Estimaterne er
k normalfordelte observationsrækker (ensidet variansanalyse) Lad x ij, i = 1,...,k, j = 1,..., n i, være udfald af stokastiske variable X ij og betragt modellen M 1 : X ij N(µ i, σ 2 ). Estimaterne er
Variansanalyse i SAS 1. Institut for Matematiske Fag December 2007
 Københavns Universitet Statistik for Biokemikere Det naturvidenskabelige fakultet Institut for Matematiske Fag December 2007 Variansanalyse i SAS 1 Ensidet variansanalyse Bartlett s test Tukey s test PROC
Københavns Universitet Statistik for Biokemikere Det naturvidenskabelige fakultet Institut for Matematiske Fag December 2007 Variansanalyse i SAS 1 Ensidet variansanalyse Bartlett s test Tukey s test PROC
Multipel regression. M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model
 M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model") Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
Reeksamen i Statistik for Biokemikere 6. april 2009
 Københavns Universitet Det Naturvidenskabelige Fakultet Reeksamen i Statistik for Biokemikere 6. april 2009 Alle hjælpemidler er tilladt, og besvarelsen må gerne skrives med blyant. Opgavesættet er på
Københavns Universitet Det Naturvidenskabelige Fakultet Reeksamen i Statistik for Biokemikere 6. april 2009 Alle hjælpemidler er tilladt, og besvarelsen må gerne skrives med blyant. Opgavesættet er på
Reeksamen i Statistik for biokemikere. Blok
 Københavns Universitet Det Naturvidenskabelige Fakultet Reeksamen i Statistik for biokemikere. Blok 2 2007-2008. 3 timers skriftlig prøve. Alle hjælpemidler - også blyant - er tilladt. Opgavesættet er
Københavns Universitet Det Naturvidenskabelige Fakultet Reeksamen i Statistik for biokemikere. Blok 2 2007-2008. 3 timers skriftlig prøve. Alle hjælpemidler - også blyant - er tilladt. Opgavesættet er
Naturvidenskabelig Bacheloruddannelse Forår 2006 Matematisk Modellering 1 Side 1
 Matematisk Modellering 1 Side 1 I nærværende opgavesæt er der 16 spørgsmål fordelt på 4 opgaver. Ved bedømmelsen af besvarelsen vægtes alle spørgsmål lige. Endvidere lægges der vægt på, at det af besvarelsen
Matematisk Modellering 1 Side 1 I nærværende opgavesæt er der 16 spørgsmål fordelt på 4 opgaver. Ved bedømmelsen af besvarelsen vægtes alle spørgsmål lige. Endvidere lægges der vægt på, at det af besvarelsen
Vejledende besvarelse af hjemmeopgave i Basal statistik for lægevidenskabelige forskere, forår 2013
 Vejledende besvarelse af hjemmeopgave i Basal statistik for lægevidenskabelige forskere, forår 2013 I forbindelse med reagensglasbehandling blev 100 par randomiseret til to forskellige former for hormonstimulation.
Vejledende besvarelse af hjemmeopgave i Basal statistik for lægevidenskabelige forskere, forår 2013 I forbindelse med reagensglasbehandling blev 100 par randomiseret til to forskellige former for hormonstimulation.
Afdeling for Anvendt Matematik og Statistik Januar Regressionsanalyse i SAS 2. Regressionsanalyse med GLM Sammenligning af regressionslinier
 Københavns Universitet Statistik for Biokemikere Det naturvidenskabelige fakultet Inge Henningsen Afdeling for Anvendt Matematik og Statistik Januar 2007 2 Regressionsanalyse med GLM Sammenligning af regressionslinier
Københavns Universitet Statistik for Biokemikere Det naturvidenskabelige fakultet Inge Henningsen Afdeling for Anvendt Matematik og Statistik Januar 2007 2 Regressionsanalyse med GLM Sammenligning af regressionslinier
Eksamen i Statistik for Biokemikere, Blok januar 2009
 Københavns Universitet Det Naturvidenskabelige Fakultet Eksamen i Statistik for Biokemikere, Blok 2 2008 09 19. januar 2009 Alle hjælpemidler er tilladt, og besvarelsen må gerne skrives med blyant. Opgavesættet
Københavns Universitet Det Naturvidenskabelige Fakultet Eksamen i Statistik for Biokemikere, Blok 2 2008 09 19. januar 2009 Alle hjælpemidler er tilladt, og besvarelsen må gerne skrives med blyant. Opgavesættet
Generelle lineære modeller
 Generelle lineære modeller Regressionsmodeller med én uafhængig intervalskala variabel: Y en eller flere uafhængige variable: X 1,..,X k Den betingede fordeling af Y givet X 1,..,X k antages at være normal
Generelle lineære modeller Regressionsmodeller med én uafhængig intervalskala variabel: Y en eller flere uafhængige variable: X 1,..,X k Den betingede fordeling af Y givet X 1,..,X k antages at være normal
Det kunne godt se ud til at ikke-rygere er ældre. Spredningen ser ud til at være nogenlunde ens i de to grupper.
 1. Indlæs data. * HUSK at angive din egen placering af filen; data framing; infile '/home/sro00/mph2016/framing.txt' firstobs=2; input id sex age frw sbp sbp10 dbp chol cig chd yrschd death yrsdth cause;
1. Indlæs data. * HUSK at angive din egen placering af filen; data framing; infile '/home/sro00/mph2016/framing.txt' firstobs=2; input id sex age frw sbp sbp10 dbp chol cig chd yrschd death yrsdth cause;
Lineær regression i SAS. Lineær regression i SAS p.1/20
 Lineær regression i SAS Lineær regression i SAS p.1/20 Lineær regression i SAS Simpel lineær regression Grafisk modelkontrol Multipel lineær regression SAS-procedurer: PROC REG PROC GPLOT Lineær regression
Lineær regression i SAS Lineær regression i SAS p.1/20 Lineær regression i SAS Simpel lineær regression Grafisk modelkontrol Multipel lineær regression SAS-procedurer: PROC REG PROC GPLOT Lineær regression
Eksamen Bacheloruddannelsen i Medicin med industriel specialisering
 Eksamen 2016 Titel på kursus: Uddannelse: Semester: Forsøgsdesign og metoder Bacheloruddannelsen i Medicin med industriel specialisering 6. semester Eksamensdato: 17-02-2015 Tid: kl. 09.00-11.00 Bedømmelsesform
Eksamen 2016 Titel på kursus: Uddannelse: Semester: Forsøgsdesign og metoder Bacheloruddannelsen i Medicin med industriel specialisering 6. semester Eksamensdato: 17-02-2015 Tid: kl. 09.00-11.00 Bedømmelsesform
Opgavebesvarelse, brain weight
 Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) For 20 nyfødte mus er der i tabellen nedenfor anført oplysning om kuldstørrelsen (fra 3 til 12
Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) For 20 nyfødte mus er der i tabellen nedenfor anført oplysning om kuldstørrelsen (fra 3 til 12
β = SDD xt SSD t σ 2 s 2 02 = SSD 02 f 02 i=1
 Lineær regression Lad x 1,..., x n være udfald af stokastiske variable X 1,..., X n og betragt modellen M 2 : X i N(α + βt i, σ 2 ) hvor t i, i = 1,..., n, er kendte tal. Konkret analyseres (en del af)
Lineær regression Lad x 1,..., x n være udfald af stokastiske variable X 1,..., X n og betragt modellen M 2 : X i N(α + βt i, σ 2 ) hvor t i, i = 1,..., n, er kendte tal. Konkret analyseres (en del af)
Eksamen i Statistik for biokemikere. Blok
 Københavns Universitet Det Naturvidenskabelige Fakultet Eksamen i Statistik for biokemikere. Blok 2 2007. 3 timers skriftlig prøve. Alle hjælpemidler - også blyant - er tilladt. Opgavesættet er på 8 sider.
Københavns Universitet Det Naturvidenskabelige Fakultet Eksamen i Statistik for biokemikere. Blok 2 2007. 3 timers skriftlig prøve. Alle hjælpemidler - også blyant - er tilladt. Opgavesættet er på 8 sider.
Øvelser til basalkursus, 5. uge. Opgavebesvarelse: Knogledensitet hos unge piger
 Øvelser til basalkursus, 5. uge Opgavebesvarelse: Knogledensitet hos unge piger I alt 112 piger har fået målt knogledensitet (bone mineral density, bmd) i 11-års alderen (baseline værdi). Pigerne er herefter
Øvelser til basalkursus, 5. uge Opgavebesvarelse: Knogledensitet hos unge piger I alt 112 piger har fået målt knogledensitet (bone mineral density, bmd) i 11-års alderen (baseline værdi). Pigerne er herefter
Model. (m separate analyser). I vores eksempel er m = 2, n 1 = 13 (13 journalister) og
. I vores eksempel er m = 2, n 1 = 13 (13 journalister) og") Model M 0 : X hi N(α h + β h t hi,σ 2 h ), h = 1,...,m, i = 1,...,n h. m separate regressionslinjer. Behandles som i afsnit 3.3. (m separate analyser). I vores eksempel er m = 2, n 1 = 13 (13 journalister)
Model M 0 : X hi N(α h + β h t hi,σ 2 h ), h = 1,...,m, i = 1,...,n h. m separate regressionslinjer. Behandles som i afsnit 3.3. (m separate analyser). I vores eksempel er m = 2, n 1 = 13 (13 journalister)
Øvelser til basalkursus, 5. uge. Opgavebesvarelse: Knogledensitet hos unge piger
 Øvelser til basalkursus, 5. uge Opgavebesvarelse: Knogledensitet hos unge piger I alt 112 piger har fået målt knogledensitet (bone mineral density, bmd) i 11-års alderen (baseline værdi). Pigerne er herefter
Øvelser til basalkursus, 5. uge Opgavebesvarelse: Knogledensitet hos unge piger I alt 112 piger har fået målt knogledensitet (bone mineral density, bmd) i 11-års alderen (baseline værdi). Pigerne er herefter
Hypoteser om mere end to stikprøver ANOVA. k stikprøver: (ikke ordinale eller højere) gælder også for k 2! : i j
 gælder også for k 2! : i j") Hypoteser om mere end to stikprøver ANOVA k stikprøver: (ikke ordinale eller højere) H 0 : 1 2... k gælder også for k 2! H 0ij : i j H 0ij : i j simpelt forslag: k k 1 2 t-tests: i j DUER IKKE! Bonferroni!!
Hypoteser om mere end to stikprøver ANOVA k stikprøver: (ikke ordinale eller højere) H 0 : 1 2... k gælder også for k 2! H 0ij : i j H 0ij : i j simpelt forslag: k k 1 2 t-tests: i j DUER IKKE! Bonferroni!!
Opgavebesvarelse, brain weight
 Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) Spørgsmål 1 Data er indlagt på T:/Basalstatistik/brain.txt og kan indlæses direkte i Analyst med
Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) Spørgsmål 1 Data er indlagt på T:/Basalstatistik/brain.txt og kan indlæses direkte i Analyst med
Modelkontrol i Faktor Modeller
 Modelkontrol i Faktor Modeller Julie Lyng Forman Københavns Universitet Afdeling for Anvendt Matematik og Statistik Statistik for Biokemikere 2003 For at konklusionerne på en ensidet, flersidet eller hierarkisk
Modelkontrol i Faktor Modeller Julie Lyng Forman Københavns Universitet Afdeling for Anvendt Matematik og Statistik Statistik for Biokemikere 2003 For at konklusionerne på en ensidet, flersidet eller hierarkisk
Klasseøvelser dag 2 Opgave 1
 Klasseøvelser dag 2 Opgave 1 1.1. Vi sætter først working directory og data indlæses: library( foreign ) d
Klasseøvelser dag 2 Opgave 1 1.1. Vi sætter først working directory og data indlæses: library( foreign ) d
Eksamen i Statistik for biokemikere. Blok
 Eksamen i Statistik for biokemikere. Blok 2 2007. Vejledende besvarelse 22-01-2007, Niels Richard Hansen Bemærkning: Flere steder er der givet en argumentation (f.eks. baseret på konfidensintervaller)
Eksamen i Statistik for biokemikere. Blok 2 2007. Vejledende besvarelse 22-01-2007, Niels Richard Hansen Bemærkning: Flere steder er der givet en argumentation (f.eks. baseret på konfidensintervaller)
Regressionsanalyse i SAS
 Københavns Universitet Statistik for Biokemikere Det naturvidenskabelige fakultet Inge Henningsen Afdeling for Anvendt Matematik og Statistik December 2006 Regressionsanalyse uden gentagelser Regressionsanalyse
Københavns Universitet Statistik for Biokemikere Det naturvidenskabelige fakultet Inge Henningsen Afdeling for Anvendt Matematik og Statistik December 2006 Regressionsanalyse uden gentagelser Regressionsanalyse
Forelæsning 11: Kapitel 11: Regressionsanalyse
 Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks Tekniske Universitet 2800
Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks Tekniske Universitet 2800
Vi ønsker at konstruere normalområder for stofskiftet, som funktion af kropsvægten.
 Opgavebesvarelse, Resting metabolic rate I filen T:\rmr.txt findes sammenhørende værdier af kropsvægt (bw, i kg) og hvilende stofskifte (rmr, kcal pr. døgn) for 44 kvinder (Altman, 1991 og Owen et.al.,
Opgavebesvarelse, Resting metabolic rate I filen T:\rmr.txt findes sammenhørende værdier af kropsvægt (bw, i kg) og hvilende stofskifte (rmr, kcal pr. døgn) for 44 kvinder (Altman, 1991 og Owen et.al.,
Oversigt. 1 Gennemgående eksempel: Højde og vægt. 2 Korrelation. 3 Regressionsanalyse (kap 11) 4 Mindste kvadraters metode
 4 Mindste kvadraters metode") Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Oversigt 1 Gennemgående eksempel: Højde og vægt 2 Korrelation 3 Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse
Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Oversigt 1 Gennemgående eksempel: Højde og vægt 2 Korrelation 3 Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse
Institut for Matematiske Fag Matematisk Modellering 1 UGESEDDEL 6
 Institut for Matematiske Fag Matematisk Modellering 1 Aarhus Universitet Eva B. Vedel Jensen 25. februar 2008 UGESEDDEL 6 Forelæsningerne torsdag den 21. februar og tirsdag den 26. februar. Jeg har gennemgået
Institut for Matematiske Fag Matematisk Modellering 1 Aarhus Universitet Eva B. Vedel Jensen 25. februar 2008 UGESEDDEL 6 Forelæsningerne torsdag den 21. februar og tirsdag den 26. februar. Jeg har gennemgået
Multipel Lineær Regression
 Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk model Specificer
Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk model Specificer
Besvarelse af juul2 -opgaven
 Besvarelse af juul2 -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Lav regressionsanalyser for hvert køn af igf1 vs. alder for præpubertale (Tanner stadium
Besvarelse af juul2 -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Lav regressionsanalyser for hvert køn af igf1 vs. alder for præpubertale (Tanner stadium
En Introduktion til SAS. Kapitel 5.
 En Introduktion til SAS. Kapitel 5. Inge Henningsen Afdeling for Statistik og Operationsanalyse Københavns Universitet Marts 2005 6. udgave Kapitel 5 T-test og PROC UNIVARIATE 5.1 Indledning Dette kapitel
En Introduktion til SAS. Kapitel 5. Inge Henningsen Afdeling for Statistik og Operationsanalyse Københavns Universitet Marts 2005 6. udgave Kapitel 5 T-test og PROC UNIVARIATE 5.1 Indledning Dette kapitel
Vejledende besvarelse af hjemmeopgave, efterår 2018
 Vejledende besvarelse af hjemmeopgave, efterår 2018 Udleveret 1. oktober, afleveres senest ved øvelserne i uge 44 (30. oktober.-1. november). Der er foretaget en del undersøgelser af krigsveteraner og
Vejledende besvarelse af hjemmeopgave, efterår 2018 Udleveret 1. oktober, afleveres senest ved øvelserne i uge 44 (30. oktober.-1. november). Der er foretaget en del undersøgelser af krigsveteraner og
Løsning eksamen d. 15. december 2008
 Informatik - DTU 02402 Introduktion til Statistik 2010-2-01 LFF/lff Løsning eksamen d. 15. december 2008 Referencer til Probability and Statistics for Engineers er angivet i rækkefølgen [8th edition, 7th
Informatik - DTU 02402 Introduktion til Statistik 2010-2-01 LFF/lff Løsning eksamen d. 15. december 2008 Referencer til Probability and Statistics for Engineers er angivet i rækkefølgen [8th edition, 7th
Anvendt Statistik Lektion 9. Variansanalyse (ANOVA)
") Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Anvendt Statistik Lektion 9. Variansanalyse (ANOVA)
") Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Analysestrategi. Lektion 7 slides kompileret 27. oktober 200315:24 p.1/17
 nalysestrategi Vælg statistisk model. Estimere parametre i model. fx. lineær regression Udføre modelkontrol beskriver modellen data tilstrækkelig godt og er modellens antagelser opfyldte fx. vha. residualanalyse
nalysestrategi Vælg statistisk model. Estimere parametre i model. fx. lineær regression Udføre modelkontrol beskriver modellen data tilstrækkelig godt og er modellens antagelser opfyldte fx. vha. residualanalyse
n r x rs x r = 1 n r s=1 (x rs x r ) 2, s=1
 2, s=1") (a) Denne opgave bygger på resultaterne fra 2 forsøg med epo-behandling af for tidligt fødte børn, idet gruppe 1 og 3 stammer fra første forsøg, mens gruppe 2 og 4 stammer fra det andet. Det må antages,
(a) Denne opgave bygger på resultaterne fra 2 forsøg med epo-behandling af for tidligt fødte børn, idet gruppe 1 og 3 stammer fra første forsøg, mens gruppe 2 og 4 stammer fra det andet. Det må antages,
Normalfordelingen. Statistik og Sandsynlighedsregning 2
 Normalfordelingen Statistik og Sandsynlighedsregning 2 Repetition og eksamen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige fejl på
Normalfordelingen Statistik og Sandsynlighedsregning 2 Repetition og eksamen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige fejl på
Modul 11: Simpel lineær regression
 Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen Modul 11: Simpel lineær regression 11.1 Regression uden gentagelser............................. 1 11.1.1 Oversigt....................................
Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen Modul 11: Simpel lineær regression 11.1 Regression uden gentagelser............................. 1 11.1.1 Oversigt....................................
1 Hb SS Hb Sβ Hb SC = , (s = )
") PhD-kursus i Basal Biostatistik, efterår 2006 Dag 6, onsdag den 11. oktober 2006 Eksempel 9.1: Hæmoglobin-niveau og seglcellesygdom Data: Hæmoglobin-niveau (g/dl) for 41 patienter med en af tre typer seglcellesygdom.
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 6, onsdag den 11. oktober 2006 Eksempel 9.1: Hæmoglobin-niveau og seglcellesygdom Data: Hæmoglobin-niveau (g/dl) for 41 patienter med en af tre typer seglcellesygdom.
Opgavebesvarelse, Basalkursus, uge 2
 Opgavebesvarelse, Basalkursus, uge 2 Opgave 1. Filen "space.txt" fra hjemmesiden ser således ud: salt pre post 1 71 61 1 65 59 1 52 47 1 68 65......... 0 52 77 0 54 80 0 52 79 Data indlæses i 3 kolonner,
Opgavebesvarelse, Basalkursus, uge 2 Opgave 1. Filen "space.txt" fra hjemmesiden ser således ud: salt pre post 1 71 61 1 65 59 1 52 47 1 68 65......... 0 52 77 0 54 80 0 52 79 Data indlæses i 3 kolonner,
Løsning til eksaminen d. 14. december 2009
 DTU Informatik 02402 Introduktion til Statistik 200-2-0 LFF/lff Løsning til eksaminen d. 4. december 2009 Referencer til Probability and Statistics for Engineers er angivet i rækkefølgen [8th edition,
DTU Informatik 02402 Introduktion til Statistik 200-2-0 LFF/lff Løsning til eksaminen d. 4. december 2009 Referencer til Probability and Statistics for Engineers er angivet i rækkefølgen [8th edition,
Program: 1. Repetition: p-værdi 2. Simpel lineær regression. 1/19
 Program: 1. Repetition: p-værdi 2. Simpel lineær regression. 1/19 For test med signifikansniveau α: p < α forkast H 0 2/19 p-værdi Betragt tilfældet med test for H 0 : µ = µ 0 (σ kendt). Idé: jo større
Program: 1. Repetition: p-værdi 2. Simpel lineær regression. 1/19 For test med signifikansniveau α: p < α forkast H 0 2/19 p-værdi Betragt tilfældet med test for H 0 : µ = µ 0 (σ kendt). Idé: jo større
Kursus i varians- og regressionsanalyse Data med detektionsgrænse. Birthe Lykke Thomsen H. Lundbeck A/S
 Kursus i varians- og regressionsanalyse Data med detektionsgrænse Birthe Lykke Thomsen H. Lundbeck A/S 1 Data med detektionsgrænse Venstrecensurering: Baggrundsstøj eller begrænsning i måleudstyrets følsomhed
Kursus i varians- og regressionsanalyse Data med detektionsgrænse Birthe Lykke Thomsen H. Lundbeck A/S 1 Data med detektionsgrænse Venstrecensurering: Baggrundsstøj eller begrænsning i måleudstyrets følsomhed
Normalfordelingen. Statistik og Sandsynlighedsregning 2
 Statistik og Sandsynlighedsregning 2 Repetition og eksamen T-test Normalfordelingen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige
Statistik og Sandsynlighedsregning 2 Repetition og eksamen T-test Normalfordelingen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige
Løsning til eksaminen d. 29. maj 2009
 DTU Informatik 02402 Introduktion til Statistik 20-2-01 LFF/lff Løsning til eksaminen d. 29. maj 2009 Referencer til Probability and Statistics for Engineers er angivet i rækkefølgen [8th edition, 7th
DTU Informatik 02402 Introduktion til Statistik 20-2-01 LFF/lff Løsning til eksaminen d. 29. maj 2009 Referencer til Probability and Statistics for Engineers er angivet i rækkefølgen [8th edition, 7th
Reeksamen Bacheloruddannelsen i Medicin med industriel specialisering. Eksamensdato: Tid: kl
 Reeksamen 2018 Titel på kursus: Uddannelse: Semester: Forsøgsdesign og metoder Bacheloruddannelsen i Medicin med industriel specialisering 6. semester Eksamensdato: 13-08-2018 Tid: kl. 09.00-11.00 Bedømmelsesform
Reeksamen 2018 Titel på kursus: Uddannelse: Semester: Forsøgsdesign og metoder Bacheloruddannelsen i Medicin med industriel specialisering 6. semester Eksamensdato: 13-08-2018 Tid: kl. 09.00-11.00 Bedømmelsesform
grupper(kvalitativ exposure) Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen
 Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen") 1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen
1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen
Basal statistik. 30. januar 2007
 Basal statistik 30. januar 2007 Deskriptiv statistik Typer af data Tabeller Grafik Summary statistics Lene Theil Skovgaard, Biostatistisk Afdeling Institut for Folkesundhedsvidenskab, Københavns Universitet
Basal statistik 30. januar 2007 Deskriptiv statistik Typer af data Tabeller Grafik Summary statistics Lene Theil Skovgaard, Biostatistisk Afdeling Institut for Folkesundhedsvidenskab, Københavns Universitet
Phd-kursus i Basal Statistik, Opgaver til 2. uge
 Phd-kursus i Basal Statistik, Opgaver til 2. uge Opgave 1: Sædkvalitet Filen oeko.txt på hjemmesiden indeholder datamateriale til belysning af forskellen i sædkvalitet mellem SAS-ansatte og mænd, der lever
Phd-kursus i Basal Statistik, Opgaver til 2. uge Opgave 1: Sædkvalitet Filen oeko.txt på hjemmesiden indeholder datamateriale til belysning af forskellen i sædkvalitet mellem SAS-ansatte og mænd, der lever
1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ
 - sammenligning af flere grupper(kvalitativ") Indhold 1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) 2 1.1 Variation indenfor og mellem grupper.......................... 2 1.2 F-test for ingen
Indhold 1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) 2 1.1 Variation indenfor og mellem grupper.......................... 2 1.2 F-test for ingen
Normalfordelingen. Det centrale er gentagne målinger/observationer (en stikprøve), der kan beskrives ved den normale fordeling: 1 2πσ
, der kan beskrives ved den normale fordeling: 1 2πσ") Normalfordelingen Det centrale er gentagne målinger/observationer (en stikprøve), der kan beskrives ved den normale fordeling: f(x) = ( ) 1 exp (x µ)2 2πσ 2 σ 2 Frekvensen af observationer i intervallet
Normalfordelingen Det centrale er gentagne målinger/observationer (en stikprøve), der kan beskrives ved den normale fordeling: f(x) = ( ) 1 exp (x µ)2 2πσ 2 σ 2 Frekvensen af observationer i intervallet
CLASS temp medie; MODEL rate=temp medie/solution; RUN;
 Ugeopgave 2.1 Bakterieprøver fra patienter transporteres ofte til laboratoriet ved stuetemperatur samt mere eller mindre udsat for luftens ilt. Dette er især uheldigt for prøver som indeholder anaerobe
Ugeopgave 2.1 Bakterieprøver fra patienter transporteres ofte til laboratoriet ved stuetemperatur samt mere eller mindre udsat for luftens ilt. Dette er især uheldigt for prøver som indeholder anaerobe
To-sidet varians analyse
 To-sidet varians analyse Repetition En-sidet ANOVA Parvise sammenligninger, Tukey s test Model begrebet To-sidet ANOVA Tre-sidet ANOVA Blok design SPSS ANOVA - definition ANOVA (ANalysis Of VAriance),
To-sidet varians analyse Repetition En-sidet ANOVA Parvise sammenligninger, Tukey s test Model begrebet To-sidet ANOVA Tre-sidet ANOVA Blok design SPSS ANOVA - definition ANOVA (ANalysis Of VAriance),
Vejledende besvarelse af hjemmeopgave i Basal Statistik, forår 2014
 Vejledende besvarelse af hjemmeopgave i Basal Statistik, forår 2014 Garvey et al. interesserer sig for sammenhængen mellem anæstesi og allergiske reaktioner (se f.eks. nedenstående reference, der dog ikke
Vejledende besvarelse af hjemmeopgave i Basal Statistik, forår 2014 Garvey et al. interesserer sig for sammenhængen mellem anæstesi og allergiske reaktioner (se f.eks. nedenstående reference, der dog ikke
Statistik og Sandsynlighedsregning 2. Repetition og eksamen. Overheads til forelæsninger, mandag 7. uge
 Statistik og Sandsynlighedsregning 2 Repetition og eksamen Overheads til forelæsninger, mandag 7. uge 1 Normalfordelingen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange
Statistik og Sandsynlighedsregning 2 Repetition og eksamen Overheads til forelæsninger, mandag 7. uge 1 Normalfordelingen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange
Konfidensintervaller og Hypotesetest
 Konfidensintervaller og Hypotesetest Konfidensinterval for andele χ -fordelingen og konfidensinterval for variansen Hypoteseteori Hypotesetest af middelværdi, varians og andele Repetition fra sidst: Konfidensintervaller
Konfidensintervaller og Hypotesetest Konfidensinterval for andele χ -fordelingen og konfidensinterval for variansen Hypoteseteori Hypotesetest af middelværdi, varians og andele Repetition fra sidst: Konfidensintervaller
Forelæsning 11: Envejs variansanalyse, ANOVA
 Kursus 02323: Introduktion til Statistik Forelæsning 11: Envejs variansanalyse, ANOVA Peder Bacher DTU Compute, Dynamiske Systemer Bygning 303B, Rum 009 Danmarks Tekniske Universitet 2800 Lyngby Danmark
Kursus 02323: Introduktion til Statistik Forelæsning 11: Envejs variansanalyse, ANOVA Peder Bacher DTU Compute, Dynamiske Systemer Bygning 303B, Rum 009 Danmarks Tekniske Universitet 2800 Lyngby Danmark
men nu er Z N((µ 1 µ 0 ) n/σ, 1)!! Forkaster hvis X 191 eller X 209 eller
 n/σ, 1)!! Forkaster hvis X 191 eller X 209 eller") Type I og type II fejl Type I fejl: forkast når hypotese sand. α = signifikansniveau= P(type I fejl) Program (8.15-10): Hvis vi forkaster når Z < 2.58 eller Z > 2.58 er α = P(Z < 2.58) + P(Z > 2.58) =
Type I og type II fejl Type I fejl: forkast når hypotese sand. α = signifikansniveau= P(type I fejl) Program (8.15-10): Hvis vi forkaster når Z < 2.58 eller Z > 2.58 er α = P(Z < 2.58) + P(Z > 2.58) =
Multipel Linear Regression. Repetition Partiel F-test Modelsøgning Logistisk Regression
 Multipel Linear Regression Repetition Partiel F-test Modelsøgning Logistisk Regression Test for en eller alle parametre I jagten på en god statistisk model har vi set på følgende to hypoteser og tilhørende
Multipel Linear Regression Repetition Partiel F-test Modelsøgning Logistisk Regression Test for en eller alle parametre I jagten på en god statistisk model har vi set på følgende to hypoteser og tilhørende
Løsning til øvelsesopgaver dag 4 spg 5-9
 Løsning til øvelsesopgaver dag 4 spg 5-9 5: Den multiple model Vi tilføjer nu yderligere to variable til vores model : Køn og kolesterol SBP = a + b*age + c*chol + d*mand hvor mand er 1 for mænd, 0 for
Løsning til øvelsesopgaver dag 4 spg 5-9 5: Den multiple model Vi tilføjer nu yderligere to variable til vores model : Køn og kolesterol SBP = a + b*age + c*chol + d*mand hvor mand er 1 for mænd, 0 for
Indhold. 2 Tosidet variansanalyse Additive virkninger Vekselvirkning... 9
 Indhold 1 Ensidet variansanalyse 2 1.1 Estimation af middelværdier............................... 3 1.2 Estimation af standardafvigelse............................. 3 1.3 F-test for ens middelværdier...............................
Indhold 1 Ensidet variansanalyse 2 1.1 Estimation af middelværdier............................... 3 1.2 Estimation af standardafvigelse............................. 3 1.3 F-test for ens middelværdier...............................
Anvendt Statistik Lektion 7. Simpel Lineær Regression
 Anvendt Statistik Lektion 7 Simpel Lineær Regression 1 Er der en sammenhæng? Plot af mordraten () mod fattigdomsraten (): Scatterplot Afhænger mordraten af fattigdomsraten? 2 Scatterplot Et scatterplot
Anvendt Statistik Lektion 7 Simpel Lineær Regression 1 Er der en sammenhæng? Plot af mordraten () mod fattigdomsraten (): Scatterplot Afhænger mordraten af fattigdomsraten? 2 Scatterplot Et scatterplot
MPH specialmodul Epidemiologi og Biostatistik
 MPH specialmodul Epidemiologi og Biostatistik Kvantitative udfaldsvariable 23. maj 2011 www.biostat.ku.dk/~sr/mphspec11 Susanne Rosthøj (Per Kragh Andersen) 1 Kapitelhenvisninger Andersen & Skovgaard:
MPH specialmodul Epidemiologi og Biostatistik Kvantitative udfaldsvariable 23. maj 2011 www.biostat.ku.dk/~sr/mphspec11 Susanne Rosthøj (Per Kragh Andersen) 1 Kapitelhenvisninger Andersen & Skovgaard:
Vejledende besvarelse af hjemmeopgave, forår 2015
 Vejledende besvarelse af hjemmeopgave, forår 2015 En stikprøve bestående af 65 mænd og 65 kvinder er blevet undersøgt med henblik på at se på en evt. sammenhæng mellem kropstemperatur og puls. På hjemmesiden
Vejledende besvarelse af hjemmeopgave, forår 2015 En stikprøve bestående af 65 mænd og 65 kvinder er blevet undersøgt med henblik på at se på en evt. sammenhæng mellem kropstemperatur og puls. På hjemmesiden
Opgave 1 Betragt to diskrete stokastiske variable X og Y. Antag at sandsynlighedsfunktionen p X for X er givet ved
 Matematisk Modellering 1 (reeksamen) Side 1 Opgave 1 Betragt to diskrete stokastiske variable X og Y. Antag at sandsynlighedsfunktionen p X for X er givet ved { 1 hvis x {1, 2, 3}, p X (x) = 3 0 ellers,
Matematisk Modellering 1 (reeksamen) Side 1 Opgave 1 Betragt to diskrete stokastiske variable X og Y. Antag at sandsynlighedsfunktionen p X for X er givet ved { 1 hvis x {1, 2, 3}, p X (x) = 3 0 ellers,
Postoperative komplikationer
 Løsninger til øvelser i kategoriske data, oktober 2008 1 Postoperative komplikationer Udgangspunktet for vurdering af den ny metode må være en nulhypotese om at der er samme komplikationshyppighed, 20%.
Løsninger til øvelser i kategoriske data, oktober 2008 1 Postoperative komplikationer Udgangspunktet for vurdering af den ny metode må være en nulhypotese om at der er samme komplikationshyppighed, 20%.
To samhørende variable
 To samhørende variable Statistik er tal brugt som argumenter. - Leonard Louis Levinsen Antagatviharn observationspar x 1, y 1,, x n,y n. Betragt de to tilsvarende variable x og y. Hvordan måles sammenhængen
To samhørende variable Statistik er tal brugt som argumenter. - Leonard Louis Levinsen Antagatviharn observationspar x 1, y 1,, x n,y n. Betragt de to tilsvarende variable x og y. Hvordan måles sammenhængen
Vejledende besvarelse af hjemmeopgave, efterår 2016
 Vejledende besvarelse af hjemmeopgave, efterår 2016 Udleveret 4. oktober, afleveres senest ved øvelserne i uge 44 (1.-4. november) Normal aktivitet af enzymet plasma kolinesterase er en forudsætning for
Vejledende besvarelse af hjemmeopgave, efterår 2016 Udleveret 4. oktober, afleveres senest ved øvelserne i uge 44 (1.-4. november) Normal aktivitet af enzymet plasma kolinesterase er en forudsætning for
Epidemiologi og Biostatistik
 Kapitel 1, Kliniske målinger Epidemiologi og Biostatistik Introduktion til skilder (varianskomponenter) måleusikkerhed sammenligning af målemetoder Mogens Erlandsen, Institut for Biostatistik Uge, torsdag
Kapitel 1, Kliniske målinger Epidemiologi og Biostatistik Introduktion til skilder (varianskomponenter) måleusikkerhed sammenligning af målemetoder Mogens Erlandsen, Institut for Biostatistik Uge, torsdag
Anvendt Statistik Lektion 8. Multipel Lineær Regression
 Anvendt Statistik Lektion 8 Multipel Lineær Regression 1 Simpel Lineær Regression (SLR) y Sammenhængen mellem den afhængige variabel (y) og den forklarende variabel (x) beskrives vha. en SLR: ligger ikke
Anvendt Statistik Lektion 8 Multipel Lineær Regression 1 Simpel Lineær Regression (SLR) y Sammenhængen mellem den afhængige variabel (y) og den forklarende variabel (x) beskrives vha. en SLR: ligger ikke
Kursus 02402 Introduktion til Statistik. Forelæsning 7: Kapitel 7 og 8: Statistik for to gennemsnit, (7.7-7.8,8.1-8.5) Per Bruun Brockhoff
 Per Bruun Brockhoff") Kursus 02402 Introduktion til Statistik Forelæsning 7: Kapitel 7 og 8: Statistik for to gennemsnit, (7.7-7.8,8.1-8.5) Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks
Kursus 02402 Introduktion til Statistik Forelæsning 7: Kapitel 7 og 8: Statistik for to gennemsnit, (7.7-7.8,8.1-8.5) Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks
Muligheder: NB: test for µ 1 = µ 2 i model med blocking ækvivalent med parret t-test! Ide: anskue β j som stikprøve fra normalfordeling.
 Eksempel: dæktyper og brændstofforbrug (opgave 25 side 319) Program: cars 1 2 3 4 5... radial 4.2 4.7 6.6 7.0 6.7... belt 4.1 4.9 6.2 6.9 6.8... Muligheder: 1. vi starter med at gennemgå opgave 7 side
Eksempel: dæktyper og brændstofforbrug (opgave 25 side 319) Program: cars 1 2 3 4 5... radial 4.2 4.7 6.6 7.0 6.7... belt 4.1 4.9 6.2 6.9 6.8... Muligheder: 1. vi starter med at gennemgå opgave 7 side
Filen indeholder 45 linier, først en linie med variabelnavnene (bw og rmr) og derefter 44 datalinier, hver med disse to oplysninger.
 og derefter 44 datalinier, hver med disse to oplysninger.") Opgavebesvarelse, Resting metabolic rate I filen rmr.txt findes sammenhørende værdier af kropsvægt (bw, i kg) og hvilende stofskifte (rmr, kcal pr. døgn) for 44 kvinder (Altman, 1991 og Owen et.al., Am.
Opgavebesvarelse, Resting metabolic rate I filen rmr.txt findes sammenhørende værdier af kropsvægt (bw, i kg) og hvilende stofskifte (rmr, kcal pr. døgn) for 44 kvinder (Altman, 1991 og Owen et.al., Am.
Epidemiologi og biostatistik. Uge 3, torsdag. Erik Parner, Afdeling for Biostatistik. Eksempel: Systolisk blodtryk
 Eksempel: Systolisk blodtryk Udgangspunkt: Vi ønsker at prædiktere det systoliske blodtryk hos en gruppe af personer. Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Afdeling for Biostatistik.
Eksempel: Systolisk blodtryk Udgangspunkt: Vi ønsker at prædiktere det systoliske blodtryk hos en gruppe af personer. Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Afdeling for Biostatistik.
Besvarelse af opgave om Vital Capacity
 Besvarelse af opgave om Vital Capacity hentet fra P. Armitage & G. Berry: Statistical methods in medical research. 2nd ed. Blackwell, 1987. Spørgsmål 1: Indlæs data og konstruer en faktor (klassevariabel)
Besvarelse af opgave om Vital Capacity hentet fra P. Armitage & G. Berry: Statistical methods in medical research. 2nd ed. Blackwell, 1987. Spørgsmål 1: Indlæs data og konstruer en faktor (klassevariabel)
12. september Epidemiologi og biostatistik. Forelæsning 4 Uge 3, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Regressionsanalyse
 . september 5 Epidemiologi og biostatistik. Forelæsning Uge, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression
. september 5 Epidemiologi og biostatistik. Forelæsning Uge, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression
Statistik Lektion 17 Multipel Lineær Regression
 Statistik Lektion 7 Multipel Lineær Regression Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test Multipel lineær regression x,x,,x
Statistik Lektion 7 Multipel Lineær Regression Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test Multipel lineær regression x,x,,x
Logistisk Regression - fortsat
 Logistisk Regression - fortsat Likelihood Ratio test Generel hypotese test Modelanalyse Indtil nu har vi set på to slags modeller: 1) Generelle Lineære Modeller Kvantitav afhængig variabel. Kvantitative
Logistisk Regression - fortsat Likelihood Ratio test Generel hypotese test Modelanalyse Indtil nu har vi set på to slags modeller: 1) Generelle Lineære Modeller Kvantitav afhængig variabel. Kvantitative
Vejledende besvarelse af hjemmeopgave
 Vejledende besvarelse af hjemmeopgave Basal statistik, efterår 2013 Udleveret 1. oktober, afleveres senest ved øvelserne i uge 44 (29. oktober-1. november) I forbindelse med en undersøgelse af vitamin
Vejledende besvarelse af hjemmeopgave Basal statistik, efterår 2013 Udleveret 1. oktober, afleveres senest ved øvelserne i uge 44 (29. oktober-1. november) I forbindelse med en undersøgelse af vitamin
Reeksamen i Statistik for biokemikere. Blok 3 2007.
 Københavns Universitet Det Naturvidenskabelige Fakultet Reeksamen i Statistik for biokemikere. Blok 3 2007. Opgave 1. 3 timers skriftlig prøve. Alle hjælpemidler - også blyant - er tilladt. Opgavesættet
Københavns Universitet Det Naturvidenskabelige Fakultet Reeksamen i Statistik for biokemikere. Blok 3 2007. Opgave 1. 3 timers skriftlig prøve. Alle hjælpemidler - også blyant - er tilladt. Opgavesættet
Økonometri: Lektion 5. Multipel Lineær Regression: Interaktion, log-transformerede data, kategoriske forklarende variable, modelkontrol
 Økonometri: Lektion 5 Multipel Lineær Regression: Interaktion, log-transformerede data, kategoriske forklarende variable, modelkontrol 1 / 35 Veksekvirkning: Motivation Vi har set på modeller som Price
Økonometri: Lektion 5 Multipel Lineær Regression: Interaktion, log-transformerede data, kategoriske forklarende variable, modelkontrol 1 / 35 Veksekvirkning: Motivation Vi har set på modeller som Price
Epidemiologi og biostatistik. Uge 3, torsdag. Erik Parner, Institut for Biostatistik. Regressionsanalyse
 Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Institut for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression Regressionsanalyse Regressionsanalyser
Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Institut for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression Regressionsanalyse Regressionsanalyser
Side 1 af 17 sider. Danmarks Tekniske Universitet. Skriftlig prøve: 25. maj 2007 Kursus navn og nr: Introduktion til Statistik, 02402
 Danmarks Tekniske Universitet Side 1 af 17 sider. Skriftlig prøve: 25. maj 2007 Kursus navn og nr: Introduktion til Statistik, 02402 Tilladte hjælpemidler: Alle Dette sæt er besvaret af (navn) (underskrift)
Danmarks Tekniske Universitet Side 1 af 17 sider. Skriftlig prøve: 25. maj 2007 Kursus navn og nr: Introduktion til Statistik, 02402 Tilladte hjælpemidler: Alle Dette sæt er besvaret af (navn) (underskrift)
Opgavebesvarelse, brain weight
 Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) For 20 musekuld er der i tabellen nedenfor anført oplysning om kuldstørrelsen (fra 3 til 12 mus
Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) For 20 musekuld er der i tabellen nedenfor anført oplysning om kuldstørrelsen (fra 3 til 12 mus
Program. Modelkontrol og prædiktion. Multiple sammenligninger. Opgave 5.2: fosforkoncentration
 Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: ekstrom@life.ku.dk Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: ekstrom@life.ku.dk Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
Statistik Lektion 4. Variansanalyse Modelkontrol
 Statistik Lektion 4 Variansanalyse Modelkontrol Eksempel Spørgsmål: Er der sammenhæng mellem udetemperaturen og forbruget af gas? Y : Forbrug af gas (gas) X : Udetemperatur (temp) Scatterplot SPSS: Estimerede
Statistik Lektion 4 Variansanalyse Modelkontrol Eksempel Spørgsmål: Er der sammenhæng mellem udetemperaturen og forbruget af gas? Y : Forbrug af gas (gas) X : Udetemperatur (temp) Scatterplot SPSS: Estimerede
Vejledende besvarelse af hjemmeopgave, forår 2018
 Vejledende besvarelse af hjemmeopgave, forår 2018 Udleveret 12. februar, afleveres senest ved øvelserne i uge 10 (6.-9.marts) I forbindelse med reagensglasbehandling blev 100 par randomiseret til to forskellige
Vejledende besvarelse af hjemmeopgave, forår 2018 Udleveret 12. februar, afleveres senest ved øvelserne i uge 10 (6.-9.marts) I forbindelse med reagensglasbehandling blev 100 par randomiseret til to forskellige
Tovejs-ANOVA (Faktoriel) Regler og problemer kan generaliseres til mere end to hovedfaktorer med tilhørende interaktioner
 Regler og problemer kan generaliseres til mere end to hovedfaktorer med tilhørende interaktioner") Tovejs-ANOVA (Faktoriel) Regler og problemer kan generaliseres til mere end to hovedfaktorer med tilhørende interaktioner I modsætning til envejs-anova kan flervejs-anova udføres selv om der er kun én
Tovejs-ANOVA (Faktoriel) Regler og problemer kan generaliseres til mere end to hovedfaktorer med tilhørende interaktioner I modsætning til envejs-anova kan flervejs-anova udføres selv om der er kun én
Statistik Lektion 16 Multipel Lineær Regression
 Statistik Lektion 6 Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk
Statistik Lektion 6 Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk
k UAFHÆNGIGE grupper Oversigt 1 Intro eksempel 2 Model og hypotese 3 Beregning - variationsopspaltning og ANOVA tabellen 4 Hypotesetest (F-test)
") Kursus 02323: Introduktion til Statistik Forelæsning 11: Envejs variansanalse, ANOVA Peder Bacher DTU Compute, Dnamiske Sstemer Bgning 303B, Rum 009 Danmarks Tekniske Universitet 2800 Lngb Danmark e-mail:
Kursus 02323: Introduktion til Statistik Forelæsning 11: Envejs variansanalse, ANOVA Peder Bacher DTU Compute, Dnamiske Sstemer Bgning 303B, Rum 009 Danmarks Tekniske Universitet 2800 Lngb Danmark e-mail:
Vejledende besvarelse af hjemmeopgave, forår 2017
 Vejledende besvarelse af hjemmeopgave, forår 2017 På hjemmesiden http://publicifsv.sund.ku.dk/~lts/basal17_1/hjemmeopgave/hjemmeopgave.txt ligger data fra 400 fødende kvinder. Der er tale om et uddrag
Vejledende besvarelse af hjemmeopgave, forår 2017 På hjemmesiden http://publicifsv.sund.ku.dk/~lts/basal17_1/hjemmeopgave/hjemmeopgave.txt ligger data fra 400 fødende kvinder. Der er tale om et uddrag
Basal Statistik. Simpel lineær regression. Simpel lineær regression. Data. Faculty of Health Sciences
 Faculty of Health Sciences Simpel lineær regression Basal Statistik Regressionsanalyse. Lene Theil Skovgaard 21. februar 2017 Regression og korrelation Simpel lineær regression Todimensionale normalfordelinger
Faculty of Health Sciences Simpel lineær regression Basal Statistik Regressionsanalyse. Lene Theil Skovgaard 21. februar 2017 Regression og korrelation Simpel lineær regression Todimensionale normalfordelinger
Basal statistik. Logaritmer og kovariansanalyse. Nyt eksempel vedr. sammenligning af målemetoder. Scatter plot af de to metoder
 Faculty of Health Sciences Logaritmer og kovariansanalyse Basal statistik Logaritmer. Kovariansanalyse Lene Theil Skovgaard 29. september 2015 Parret sammenligning, målemetoder med logaritmer Tosidet variansanalyse
Faculty of Health Sciences Logaritmer og kovariansanalyse Basal statistik Logaritmer. Kovariansanalyse Lene Theil Skovgaard 29. september 2015 Parret sammenligning, målemetoder med logaritmer Tosidet variansanalyse