Logistisk regression
|
|
|
- Lucas Lauridsen
- 10 år siden
- Visninger:
Transkript
1 Logistisk regression Test af antagelsen om lineære effekter Modelkonstruktion og modelsøgning Hvilke variable og hvilke interaktioner skal inkluderes i regressionsmodellerne? 1

2 Logistiske regressionsmodeller med kvantitative variable Y = arbejdsløs X = intelligens målt 25 år tidligere 2


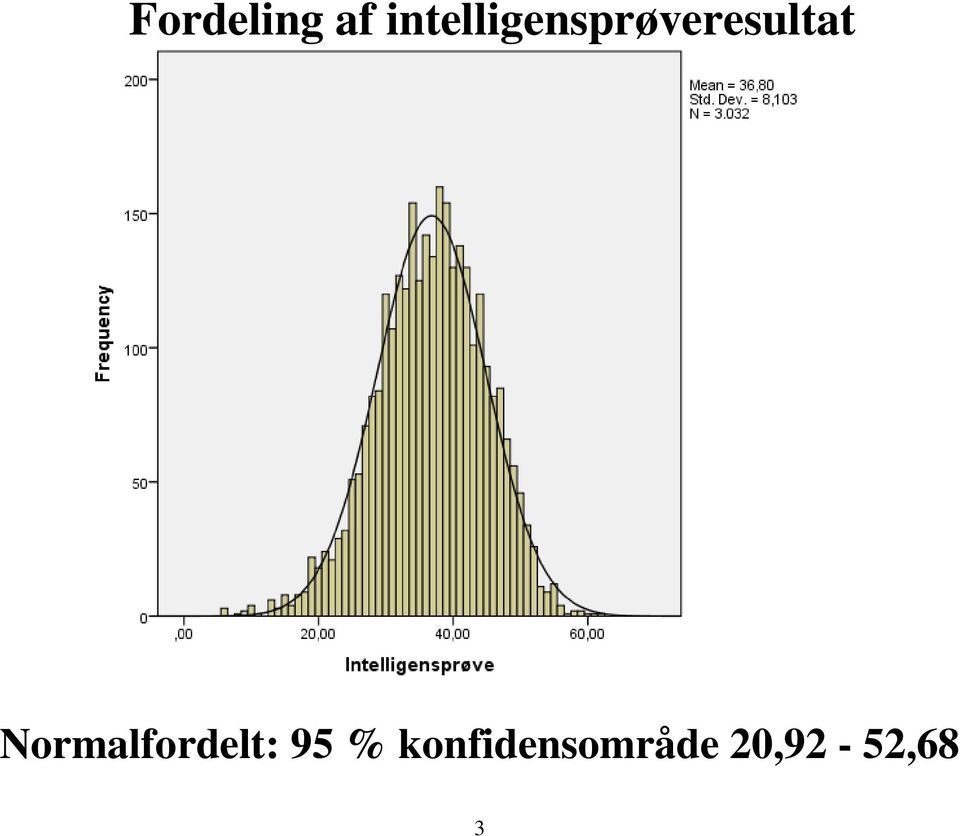
3 Fordeling af intelligensprøveresultat Normalfordelt: 95 % konfidensområde 20,92-52,68 3
4 Den logistiske regressionsmodel P(Arbejdsløs Intelligens) = e 1 + e α+β x α+β x Dvs. P(Arbejdsløs Intelligens) = e 1 + e x x 4

5 Tolkning af modellen Et trin op ad intelligensskalaen: Risikoen på odds skalaen reduceres med faktoren Risikoen på logit skalaen reduceres med point 5

6 Sandsynlighed for arbejdsløshed som funktion af intelligens Bemærk, at kurven krummer lidt 6

7 Logit-værdi for arbejdsløshed som funktion af intelligens En ret linie. Effekten af intelligens målt på logitskalaen er lineær. 7

8 Er det en troværdig beskrivelse af effekten? Hvis effekten på logitskalaen er en kontinuert funktion, f(x), af intelligensen kan man altid skrive den som en potensrække f(x) = α + β 1 x + β 2 x 2 + β 3 x β n x n +. Den logistiske regressionsmodel antager, at β 2 = β 3 = β 4 = = 0 Det behøver naturligvis ikke at være rigtigt 8

9 Kontrol af linearitet i logistiske regressionsmodeller Beregn nye variable, X 2 = X 2, X 3 = X 3,, etc., og inkluder dem i den logistiske regressionsmodel P(Arbejdsløs Intelligens) = e 1 + e 2 3 1x 2x 3x α+β +β +β 2 3 1x 2x 3x α+β +β +β 9
 = e 1 + e 2 3 1x 2x 3x α+β +β +β")
10 Analysen Signifikant effekt af både 2. og 3. gradsledet Effekten er altså ikke lineær 10

11 Estimerede sandsynligheder 11

12 Effekt målt på logitskalaen 12

13 Modeller med interaktioner Det hierarkiske princip for interaktioner i regressionsmodeller Hvis en model indeholder interaktionen mellem et vist antal variable, skal den også indeholde interaktionsparametre svarende til hver delmængde af disse variable inklusiv parametre for hovedvirkningen for disse variable. 13

14 En model med interaktion mellem tre variable, A, B og C skal indeholde følgende parametre: 1) Trefaktor-interaktionerne, β abc. 2) Samtlige tofaktor-interaktioner, β ab, β ac og β bc. 3) Alle hovedvirkninger, β a, β b og β c. 4) Konstantleddet, α. 14
 Alle hovedvirkninger, β a, β b og β c. 4) Konstantleddet, α.")
15 Et eksempel : Hvilke faktorer har betydning om man bliver arbejdsløs? Potentielle faktorer: 1) K = Køn 2) U = Uddannelse opdelt i fem kategorier, LVU, MVU, KVU, Erhvervsrettet, Restgruppen 3) F = Familiesocialgruppe under opvækst 4) O = Opvækstområde (urbanisering) opdelt i fire kategorier, København, Provinsby, Mindre by og Landkommune 5) I = Intelligens målt i syvende klasse. 15
 opdelt i fire kategorier, København, Provinsby, Mindre by og Landkommune 5) I =")
16

17 Antal rigtige Fordeling af intelligensprøveresultat i syvende klasse 17

18 Valg og prioritering af variable. 1) De primære variable er de uafhængige variable, som er af særlig faglig interesse. Sammenhængene mellem de primære variable og den afhængige variabel er de primære sammenhænge. 2) De sekundære variable er variable, hvis eneste funktion er at optræde som kontrolvariable. Sammenhængene mellem den afhængige variabel og de sekundære variable omtales som sekundære sammenhænge.. 18
 De sekundære variable er variable, hvis eneste funktion er at optræde som kontrolvariable.")
19 Unødvendige kontrolvariable En sekundær variabel, Z, er uden betydning som kontrolvariabel i en logistisk regressionsanalyse, hvis samtlige parametre med reference til Z er lig med nul Sådanne variable bør derfor ekskluderes. 19

20 Overordnet analysestrategi 1) Modellens primære struktur drejer sig om alt det, der har direkte reference til de faglige problemer, der skal belyses. 2) Modellens sekundære struktur er alt det ved modellen, der ikke henviser til disse problemer. Den sekundære struktur kan på denne måde omfatte alt fra modelegenskaber, der kan motiveres ud fra den teoretiske referenceramme, over helt åbne spørgsmål, til antagelser, der er motiveret af ønsket om at komme til at arbejde med enkle modeller, der i det mindste fungerer i praksis. 20

21 To analysefaser: Indledende modelkonstruktion Analyse af primære problemstillinger 21
22 1) Indledende modelkonstruktion - Definition af startmodel. Startmodellen bør indeholde hele den primære modelstruktur og så meget af den sekundære struktur, som det i praksis er muligt at arbejde med. - Modelsøgning. Trinvis søgning efter en model med en mere enkel sekundær struktur. - Modelkontrol. Kontrol af, at der ikke er åbenlyse tegn på at modellen er udtryk for overforenkling. 22
23 2) Analyse af primære problemstillinger. - Test af primære hypoteser. Bemærk, at disse test kan resultere i at nogle af de primære variable skal fjernes fra modellen. - Modelkontrol. - Estimation og tolkning af primære parametre. I praksis sker dette sammen med beregningerne af teststørrelserne for de primære hypoteser. De har dog først interesse, hvis modelkontrollen har vist, at der ikke ser ud til at være problemer med modellen. 23
24
25 Modelnotation og model formler for hierarkiske modeller En modelformel = en række additive model-led, der angiver, hvilke uafhængige variable, der indgår i modellen, og hvilke interaktioner, der er mellem effekten af disse variable. Interaktioner angives som produkter af variable ved hjælp af operatoren *. A+B*C = e P(Y=1 A=a,B=b,C=c) = 1 + A+B+C = P(Y=1 A=a,B=b,C=c) = α + β a+ β b+ β c+ β bc e e 1 + a b c bc α + β a+ β b+ β c+ β bc e a b c bc α + β a+ β b+ β c a b c α + β a+ β b+ β c a b c 25
26 Modeluniverset Model Model Kommentar nr. 1 A*B*C Trefaktor interaktion den mest komplicerede model. 2 A*B+A*C +B*C Ingen trefaktor, men samtlige tofaktor interaktioner. 3 A*B+A*C Ingen interaktion mellem B og C. 4 A*B+B*C Ingen interaktion mellem A og C. 5 A*C+B*C Ingen interaktion mellem A og B. 6 A*B+C Alle variable har betydning. Kun interaktion mellem A og B. 7 A*C+B Alle variable har betydning. Kun interaktion mellem A og C. 8 A+B*C Alle variable har betydning. Kun interaktion mellem B og C. 9 A*B C er uden betydning. Interaktion mellem A og B. 10 A*C B er uden betydning. Interaktion mellem A og C. 11 B*C A er uden betydning. Interaktion mellem B og C. 12 A+B+C Alle variable har betydning. Ingen interaktioner. 13 A+B C er uden betydning. Ingen interaktion. 14 A+C B er uden betydning. Ingen interaktion. 15 B+C A er uden betydning. Ingen interaktion. 16 A A er den eneste variabel, der har betydning. 17 B ditto 18 C ditto 19 - Hverken A, B eller C har betydning. En model, M 0, siges at være indlejret i en anden model, M 1, hvis M 1 dels indeholder alle de parametre, som M 0 indeholder og dels indeholder nogle parametre, der ikke indgår i M 0. 26
27 Indlejringer af modeller i model-universet defineret ved tre variable, A, B og C. Model nr. Model Indlejret * i 1 A*B*C - 2 A*B+A*C+B*C 1 3 A*B+A*C 1,2 4 A*B+B*C 1,2 5 A*C+B*C 1,2 6 A*B+C 1,2,3,4 7 A*C+B 1,2,3,5 8 A+B*C 1,2,4,5 9 A*B 1-4,6 10 A*C 1-3,5,7 11 B*C 1-2,4-5,8 12 A+B+C 1-5, A+B 1-8,9,12 14 A+C 1-8,10,12 15 B+C 1-8,11,12 16 A 1-10,12,13,14 17 B 1-9,11,12,13,15 18 C 1-8,10-12,14, ,
28 Modelsøgning Mættet model Start model Sand model tom model 28
29 A*B*C A*B+A*C+B*C A*B+A*C A*B+B*C A*C+B*C A*B+C A*C+B A+B*C A*B A*C B*C A+B+C A+B A+C B+C A B C - 29
30
31 Elimination af Første trin af modelsøgning med modellen K*U+K*F+K*O+K*I+U*F+U*O+U*I+F*O+F*I+O*I+I 2 +I 3 som startmodel ny model Χ 2 df p K*U K*F+K*O+K*I+U*F+U*O+U*I+F*O+F*I+O*I+I 2 +I K*F K*U+K*O+K*I+U*F+U*O+U*I+F*O+F*I+O*I+I 2 +I K*O K*U+K*F+K*I+U*F+U*O+U*I+F*O+F*I+O*I+I 2 +I K*I K*U+K*F+K*O+U*F+U*O+U*I+F*O+F*I+O*I+I 2 +I U*F K*U+K*F+K*O+K*I+U*O+U*I+F*O+F*I+O*I+I 2 +I U*O K*U+K*F+K*O+K*I+U*F+U*I+F*O+F*I+O*I+I 2 +I U*I K*U+K*F+K*O+K*I+U*F+U*O+F*O+F*I+O*I+I 2 +I F*O K*U+K*F+K*O+K*I+U*F+U*O+U*I+F*I+O*I+I 2 +I F*I K*U+K*F+K*O+K*I+U*F+U*O+U*I+F*O+O*I+I 2 +I O*I K*U+K*F+K*O+K*I+U*F+U*O+U*I+F*O+F*I+I 2 +I I 2 K*U+K*F+K*O+K*I+U*F+U*O+U*I+F*O+F*I+O*I+I I 3 K*U+K*F+K*O+K*I+U*F+U*O+U*I+F*O+F*I+O*I+I
32 Andet trin af modelsøgning. Den aktuelle model er K*U+K*O+K*I+U*F+U*O+U*I+F*O+F*I+O*I+I 2 +I 3. Elimination ny model LR df p af K*U K*O+K*I+U*F+U*O+U*I+F*O+F*I+O*I+I 2 +I K*O K*U+K*I+U*F+U*O+U*I+F*O+F*I+O*I+I 2 +I K*I K*U+K*O+U*F+U*O+U*I+F*O+F*I+O*I+I 2 +I U*F K*U+K*O+K*I+U*O+U*I+F*O+F*I+O*I+I 2 +I U*O K*U+K*O+K*I+U*F+U*I+F*O+F*I+O*I+I 2 +I U*I K*U+K*O+K*I+U*F+U*O+F*O+F*I+O*I+I 2 +I F*O K*U+K*O+K*I+U*F+U*O+U*I+F*I+O*I+I 2 +I F*I K*U+K*O+K*I+U*F+U*O+U*I+F*O+O*I+I 2 +I O*I K*U+K*O+K*I+U*F+U*O+U*I+F*O+F*I+I 2 +I I 2 K*U+K*O+K*I+U*F+U*O+U*I+F*O+F*I+O*I+I I 3 K*U+K*O+K*I+U*F+U*O+U*I+F*O+F*I+O*I+I
33 Oversigt over interaktioner og hovedvirkninger, der blev elimineret fra modellen for arbejdsløshed blandt 32-årige. Trin model-led LR df p 1 K*F F*U O*I U*O K*O K*I K*U F*O F*I F Slutmodellen: K+O+U*I+I 2 +I 3 33
34 Forløbet af modelsøgningen Oversigt over beregnede signifikanssandsynligheder Trin Led K*U * K*F.862 * K*O * K*I * U*F * U*O * U*I ** F*O * F*I * O*I * I I O K F * U
35 Modelsøgningen slutter med en model, hvor 1) effekten af intelligens ikke kan beskrives ved en logitlineær model, 2) der optræder én interaktion mellem uddannelse og intelligens, 3) effekten af familiesocialgruppe helt er elimineret. 35
36
37 Estimater af parametre i to modeller. β 1, β 2 og β 3 er parametrene for henholdsvis I (intelligens), I 2 og I 3 model interaktion inkluderet interaktion ekskluderet parameter estimat stand.fejl estimat stand.fejl α Køn β mand β kvinde Opv.område β kbh β provinsby β mindre by β land Uddannelse β LVU β MVU β KVU β Erhv.udd β restgruppe Intelligens β β β Interaktion Udd*intel. β LVU,Int β MVU,int β KVU,Int β Erhv,Int β Rest,Int
38 4,0 Samlet effekt af uddannelse og intelligens 3,5 3,0 2,5 2,0 1,5 Uddannelse Restgruppe Erhvervsfaglig uddannelse KVU MVU 1, LVU Antal rigtige Samlet effekt af intelligens og uddannelse beregnet af en model uden interaktion mellem de to variable. 38
39 0,0 Samlet effekt af uddannelse og intelligens -,5-1,0-1,5-2,0-2,5-3,0-3,5 Uddannelse Restgruppe Erhvervsfaglig uddannelse KVU MVU -4, LVU Antal rigtige Samlet effekt af intelligens og uddannelse beregnet af en model med interaktion mellem de to variable. 39
Regressionsanalyser. Hvad er det statistiske problem? Primære og sekundære problemer. Metodeproblemer.
 Regressionsanalyser Hvad er det statistiske problem? Primære og sekundære problemer. Metodeproblemer. Hvilke faglige problemer kan man løse vha. regressionsanalyser? 1 Regressionsanalyser Det primære problem
Regressionsanalyser Hvad er det statistiske problem? Primære og sekundære problemer. Metodeproblemer. Hvilke faglige problemer kan man løse vha. regressionsanalyser? 1 Regressionsanalyser Det primære problem
Statistik II Lektion 3. Logistisk Regression Kategoriske og Kontinuerte Forklarende Variable
 Statistik II Lektion 3 Logistisk Regression Kategoriske og Kontinuerte Forklarende Variable Setup: To binære variable X og Y. Statistisk model: Konsekvens: Logistisk regression: 2 binære var. e e X Y P
Statistik II Lektion 3 Logistisk Regression Kategoriske og Kontinuerte Forklarende Variable Setup: To binære variable X og Y. Statistisk model: Konsekvens: Logistisk regression: 2 binære var. e e X Y P
Statistik og skalavalidering. Opgave 1
 Statistik og skalavalidering Opgave 1 Opgavens formål: Denne opgave har, ligesom det vil være tilfældet for de fleste andre øvelsesopgaver på dette kursus, flere forskellige formål. For det første et praktisk/teknisk
Statistik og skalavalidering Opgave 1 Opgavens formål: Denne opgave har, ligesom det vil være tilfældet for de fleste andre øvelsesopgaver på dette kursus, flere forskellige formål. For det første et praktisk/teknisk
Statikstik II 2. Lektion. Lidt sandsynlighedsregning Lidt mere om signifikanstest Logistisk regression
 Statikstik II 2. Lektion Lidt sandsynlighedsregning Lidt mere om signifikanstest Logistisk regression Sandsynlighedsregningsrepetition Antag at Svar kan være Ja og Nej. Sandsynligheden for at Svar Ja skrives
Statikstik II 2. Lektion Lidt sandsynlighedsregning Lidt mere om signifikanstest Logistisk regression Sandsynlighedsregningsrepetition Antag at Svar kan være Ja og Nej. Sandsynligheden for at Svar Ja skrives
Opsamling Modeltyper: Tabelanalyse Logistisk regression Generaliserede lineære modeller Log-lineære modeller
 Opsamling Modeltyper: Tabelanalyse Logistisk regression Binær respons og kategorisk eller kontinuerte forklarende variable. Generaliserede lineære modeller Normalfordelt respons og kategoriske forklarende
Opsamling Modeltyper: Tabelanalyse Logistisk regression Binær respons og kategorisk eller kontinuerte forklarende variable. Generaliserede lineære modeller Normalfordelt respons og kategoriske forklarende
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab. Eksamensopgave E05. Socialklasse og kronisk sygdom
 Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Eksamensopgave E05 Socialklasse og kronisk sygdom Data: Tværsnitsundersøgelse fra 1986 Datamaterialet indeholder: Køn, alder, Højest opnåede
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Eksamensopgave E05 Socialklasse og kronisk sygdom Data: Tværsnitsundersøgelse fra 1986 Datamaterialet indeholder: Køn, alder, Højest opnåede
Eksamen i statistik 2010 Kandidatuddannelsen i folkesundhedsvidenskab
 D E T S U N D H E D S V I D E N S K A B E L I G E F A K U L T E T K Ø B E N H A V N S U N I V E R S I T E T Eksamen i statistik 2010 Kandidatuddannelsen i folkesundhedsvidenskab Eksamensnummer: 16, 23
D E T S U N D H E D S V I D E N S K A B E L I G E F A K U L T E T K Ø B E N H A V N S U N I V E R S I T E T Eksamen i statistik 2010 Kandidatuddannelsen i folkesundhedsvidenskab Eksamensnummer: 16, 23
Synopsis til eksamen i Statistik
 Synopsis til eksamen i Statistik Kandidatuddannelsen i Folkesundhedsvidenskab Københavns Universitet december 2010 Eksamensnummer: 12 Antal anslag: 23.839 (svarende til 9,9 normalsider) - 1 - Indholdsfortegnelse
Synopsis til eksamen i Statistik Kandidatuddannelsen i Folkesundhedsvidenskab Københavns Universitet december 2010 Eksamensnummer: 12 Antal anslag: 23.839 (svarende til 9,9 normalsider) - 1 - Indholdsfortegnelse
Statistik II 4. Lektion. Logistisk regression
 Statistik II 4. Lektion Logistisk regression Logistisk regression: Motivation Generelt setup: Dikotom(binær) afhængig variabel Kontinuerte og kategoriske forklarende variable (som i lineær reg.) Eksempel:
Statistik II 4. Lektion Logistisk regression Logistisk regression: Motivation Generelt setup: Dikotom(binær) afhængig variabel Kontinuerte og kategoriske forklarende variable (som i lineær reg.) Eksempel:
Regneregler for middelværdier M(X+Y) = M X +M Y. Spredning varians og standardafvigelse. 1 n VAR(X) Y = a + bx VAR(Y) = VAR(a+bX) = b²var(x)
 = M X +M Y. Spredning varians og standardafvigelse. 1 n VAR(X) Y = a + bx VAR(Y) = VAR(a+bX) = b²var(x)") Formelsamlingen 1 Regneregler for middelværdier M(a + bx) a + bm X M(X+Y) M X +M Y Spredning varians og standardafvigelse VAR(X) 1 n n i1 ( X i - M x ) 2 Y a + bx VAR(Y) VAR(a+bX) b²var(x) 2 Kovariansen
Formelsamlingen 1 Regneregler for middelværdier M(a + bx) a + bm X M(X+Y) M X +M Y Spredning varians og standardafvigelse VAR(X) 1 n n i1 ( X i - M x ) 2 Y a + bx VAR(Y) VAR(a+bX) b²var(x) 2 Kovariansen
Multipel Linear Regression. Repetition Partiel F-test Modelsøgning Logistisk Regression
 Multipel Linear Regression Repetition Partiel F-test Modelsøgning Logistisk Regression Test for en eller alle parametre I jagten på en god statistisk model har vi set på følgende to hypoteser og tilhørende
Multipel Linear Regression Repetition Partiel F-test Modelsøgning Logistisk Regression Test for en eller alle parametre I jagten på en god statistisk model har vi set på følgende to hypoteser og tilhørende
Generelle lineære modeller
 Generelle lineære modeller Regressionsmodeller med én uafhængig intervalskala variabel: Y en eller flere uafhængige variable: X 1,..,X k Den betingede fordeling af Y givet X 1,..,X k antages at være normal
Generelle lineære modeller Regressionsmodeller med én uafhængig intervalskala variabel: Y en eller flere uafhængige variable: X 1,..,X k Den betingede fordeling af Y givet X 1,..,X k antages at være normal
Anvendt Statistik Lektion 9. Variansanalyse (ANOVA)
") Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Statistik II 1. Lektion. Analyse af kontingenstabeller
 Statistik II 1. Lektion Analyse af kontingenstabeller Kursusbeskrivelse Omfang 5 kursusgange (forelæsning + opgaveregning) 5 kursusgange (mini-projekt) Emner Analyse af kontingenstabeller Logistisk regression
Statistik II 1. Lektion Analyse af kontingenstabeller Kursusbeskrivelse Omfang 5 kursusgange (forelæsning + opgaveregning) 5 kursusgange (mini-projekt) Emner Analyse af kontingenstabeller Logistisk regression
Anvendt Statistik Lektion 9. Variansanalyse (ANOVA)
") Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Normalfordelingen. Det centrale er gentagne målinger/observationer (en stikprøve), der kan beskrives ved den normale fordeling: 1 2πσ
, der kan beskrives ved den normale fordeling: 1 2πσ") Normalfordelingen Det centrale er gentagne målinger/observationer (en stikprøve), der kan beskrives ved den normale fordeling: f(x) = ( ) 1 exp (x µ)2 2πσ 2 σ 2 Frekvensen af observationer i intervallet
Normalfordelingen Det centrale er gentagne målinger/observationer (en stikprøve), der kan beskrives ved den normale fordeling: f(x) = ( ) 1 exp (x µ)2 2πσ 2 σ 2 Frekvensen af observationer i intervallet
Vi vil analysere effekten af rygning og alkohol på chancen for at blive gravid ved at benytte forskellige Cox regressions modeller.
 Løsning til øvelse i TTP dag 3 Denne øvelse omhandler tid til graviditet. Et studie vedrørende tid til graviditet (Time To Pregnancy = TTP) inkluderede 423 par i alderen 20-35 år. Parrene blev fulgt i
Løsning til øvelse i TTP dag 3 Denne øvelse omhandler tid til graviditet. Et studie vedrørende tid til graviditet (Time To Pregnancy = TTP) inkluderede 423 par i alderen 20-35 år. Parrene blev fulgt i
Log-lineære modeller. Analyse af symmetriske sammenhænge mellem kategoriske variable. Ordinal information ignoreres.
 Log-lineære modeller Analyse af symmetriske sammenhænge mellem kategoriske variable. Ordinal information ignoreres. Kontingenstabel Contingency: mulighed/tilfælde Kontingenstabel: antal observationer (frekvenser)
Log-lineære modeller Analyse af symmetriske sammenhænge mellem kategoriske variable. Ordinal information ignoreres. Kontingenstabel Contingency: mulighed/tilfælde Kontingenstabel: antal observationer (frekvenser)
Statistik & Skalavalidering
 å Statistik & Skalavalidering Synopsis til mundtlig eksamen d. 24. januar 2011 K ø b e n h a v n s U n i v e r s i t e t K a n d i d a t u d d a n n e l s e n i F o l k e s u n d h e d s v i d e n s k
å Statistik & Skalavalidering Synopsis til mundtlig eksamen d. 24. januar 2011 K ø b e n h a v n s U n i v e r s i t e t K a n d i d a t u d d a n n e l s e n i F o l k e s u n d h e d s v i d e n s k
INDLEDNING...2 DATAMATERIALET... 2 KARAKTERISTIK AF POPULATIONEN... 4
 Indholdsfortegnelse INDLEDNING...2 DATAMATERIALET... 2 KARAKTERISTIK AF OULATIONEN... 4 DELOGAVE 1...5 BEGREBSVALIDITET... 6 Differentiel item funktionsanalyser...7 Differentiel item effekt...10 Lokal
Indholdsfortegnelse INDLEDNING...2 DATAMATERIALET... 2 KARAKTERISTIK AF OULATIONEN... 4 DELOGAVE 1...5 BEGREBSVALIDITET... 6 Differentiel item funktionsanalyser...7 Differentiel item effekt...10 Lokal
Overlevelse efter AMI. Hvilken betydning har følgende faktorer for risikoen for ikke at overleve: Køn og alder betragtes som confoundere.
 Overlevelse efter AMI Hvilken betydning har følgende faktorer for risikoen for ikke at overleve: Diabetes VF (Venticular fibrillation) WMI (Wall motion index) CHF (Cardiac Heart Failure) Køn og alder betragtes
Overlevelse efter AMI Hvilken betydning har følgende faktorer for risikoen for ikke at overleve: Diabetes VF (Venticular fibrillation) WMI (Wall motion index) CHF (Cardiac Heart Failure) Køn og alder betragtes
Eksamen i Statistik og skalavalidering
 Eksamen i Statistik og skalavalidering 2009-studieordning Til aflevering d. 22. december 2010 Efterårssemestret 2010, Kandidatuddannelsen i Folkesundhedsvidenskab Opgaven er udarbejdet af: Eksamensnummer
Eksamen i Statistik og skalavalidering 2009-studieordning Til aflevering d. 22. december 2010 Efterårssemestret 2010, Kandidatuddannelsen i Folkesundhedsvidenskab Opgaven er udarbejdet af: Eksamensnummer
SYNOPSIS TIL EKSAMEN I STATISTIK OG SKALAVALIDERING
 SYNOPSIS TIL EKSAMEN I STATISTIK OG SKALAVALIDERING Kandidatuddanelsen i Folkesundhedsvidenskab Københavns Universitet, 2010 EKSAMENSNUMMER: 7 & 40 Antal anslag: 23.576 December 2010 INDHOLDSFORTEGNELSE
SYNOPSIS TIL EKSAMEN I STATISTIK OG SKALAVALIDERING Kandidatuddanelsen i Folkesundhedsvidenskab Københavns Universitet, 2010 EKSAMENSNUMMER: 7 & 40 Antal anslag: 23.576 December 2010 INDHOLDSFORTEGNELSE
Analysestrategi. Lektion 7 slides kompileret 27. oktober 200315:24 p.1/17
 nalysestrategi Vælg statistisk model. Estimere parametre i model. fx. lineær regression Udføre modelkontrol beskriver modellen data tilstrækkelig godt og er modellens antagelser opfyldte fx. vha. residualanalyse
nalysestrategi Vælg statistisk model. Estimere parametre i model. fx. lineær regression Udføre modelkontrol beskriver modellen data tilstrækkelig godt og er modellens antagelser opfyldte fx. vha. residualanalyse
Anvendt Statistik Lektion 8. Multipel Lineær Regression
 Anvendt Statistik Lektion 8 Multipel Lineær Regression 1 Simpel Lineær Regression (SLR) y Sammenhængen mellem den afhængige variabel (y) og den forklarende variabel (x) beskrives vha. en SLR: ligger ikke
Anvendt Statistik Lektion 8 Multipel Lineær Regression 1 Simpel Lineær Regression (SLR) y Sammenhængen mellem den afhængige variabel (y) og den forklarende variabel (x) beskrives vha. en SLR: ligger ikke
Program. Logistisk regression. Eksempel: pesticider og møl. Odds og odds-ratios (igen)
") Faculty of Life Sciences Program Logistisk regression Claus Ekstrøm E-mail: [email protected] Odds og odds-ratios igen Logistisk regression Estimation og inferens Modelkontrol Slide 2 Statistisk Dataanalyse
Faculty of Life Sciences Program Logistisk regression Claus Ekstrøm E-mail: [email protected] Odds og odds-ratios igen Logistisk regression Estimation og inferens Modelkontrol Slide 2 Statistisk Dataanalyse
Sammenhængsanalyser. Et eksempel: Sammenhæng mellem rygevaner som 45-årig og selvvurderet helbred som 51 blandt mænd fra Københavns amt.
 Sammenhængsanalyser Et eksempel: Sammenhæng mellem rygevaner som 45-årig og selvvurderet helbred som 51 blandt mænd fra Københavns amt. rygevaner som 45 årig * helbred som 51 årig Crosstabulation rygevaner
Sammenhængsanalyser Et eksempel: Sammenhæng mellem rygevaner som 45-årig og selvvurderet helbred som 51 blandt mænd fra Københavns amt. rygevaner som 45 årig * helbred som 51 årig Crosstabulation rygevaner
12. september Epidemiologi og biostatistik. Forelæsning 4 Uge 3, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Regressionsanalyse
 . september 5 Epidemiologi og biostatistik. Forelæsning Uge, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression
. september 5 Epidemiologi og biostatistik. Forelæsning Uge, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression
Epidemiologi og biostatistik. Uge 3, torsdag. Erik Parner, Institut for Biostatistik. Regressionsanalyse
 Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Institut for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression Regressionsanalyse Regressionsanalyser
Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Institut for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression Regressionsanalyse Regressionsanalyser
Statistik II 1. Lektion. Sandsynlighedsregning Analyse af kontingenstabeller
 Statistik II 1. Lektion Sandsynlighedsregning Analyse af kontingenstabeller Kursusbeskrivelse Omfang 5 kursusgange (forelæsning + opgaveregning) 5 kursusgange (mini-projekt) Emner Analyse af kontingenstabeller
Statistik II 1. Lektion Sandsynlighedsregning Analyse af kontingenstabeller Kursusbeskrivelse Omfang 5 kursusgange (forelæsning + opgaveregning) 5 kursusgange (mini-projekt) Emner Analyse af kontingenstabeller
Tema. Dagens tema: Indfør centrale statistiske begreber.
 Tema Dagens tema: Indfør centrale statistiske begreber. Model og modelkontrol Estimation af parametre. Fordeling. Hypotese og test. Teststørrelse. konfidensintervaller Vi tager udgangspunkt i Ex. 3.1 i
Tema Dagens tema: Indfør centrale statistiske begreber. Model og modelkontrol Estimation af parametre. Fordeling. Hypotese og test. Teststørrelse. konfidensintervaller Vi tager udgangspunkt i Ex. 3.1 i
Statistiske Modeller 1: Kontingenstabeller i SAS
 Statistiske Modeller 1: Kontingenstabeller i SAS Jens Ledet Jensen October 31, 2005 1 Indledning Som vist i Notat 1 afsnit 13 er 2 log Q for et test i en multinomialmodel ækvivalent med et test i en poissonmodel.
Statistiske Modeller 1: Kontingenstabeller i SAS Jens Ledet Jensen October 31, 2005 1 Indledning Som vist i Notat 1 afsnit 13 er 2 log Q for et test i en multinomialmodel ækvivalent med et test i en poissonmodel.
Epidemiologi og biostatistik. Uge 3, torsdag. Erik Parner, Afdeling for Biostatistik. Eksempel: Systolisk blodtryk
 Eksempel: Systolisk blodtryk Udgangspunkt: Vi ønsker at prædiktere det systoliske blodtryk hos en gruppe af personer. Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Afdeling for Biostatistik.
Eksempel: Systolisk blodtryk Udgangspunkt: Vi ønsker at prædiktere det systoliske blodtryk hos en gruppe af personer. Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Afdeling for Biostatistik.
Statistik Lektion 4. Variansanalyse Modelkontrol
 Statistik Lektion 4 Variansanalyse Modelkontrol Eksempel Spørgsmål: Er der sammenhæng mellem udetemperaturen og forbruget af gas? Y : Forbrug af gas (gas) X : Udetemperatur (temp) Scatterplot SPSS: Estimerede
Statistik Lektion 4 Variansanalyse Modelkontrol Eksempel Spørgsmål: Er der sammenhæng mellem udetemperaturen og forbruget af gas? Y : Forbrug af gas (gas) X : Udetemperatur (temp) Scatterplot SPSS: Estimerede
Lineær og logistisk regression
 Faculty of Health Sciences Lineær og logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Dagens program Lineær regression
Faculty of Health Sciences Lineær og logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Dagens program Lineær regression
Anvendt Statistik Lektion 5. Sammenligning af to grupper * Sammenligning af middelværdier * Sammenligning af andele
 Anvendt Statistik Lektion 5 Sammenligning af to grupper * Sammenligning af middelværdier * Sammenligning af andele Motiverende eksempel Antal minutter brugt på rengøring/madlavning: Rengøring/Madlavning
Anvendt Statistik Lektion 5 Sammenligning af to grupper * Sammenligning af middelværdier * Sammenligning af andele Motiverende eksempel Antal minutter brugt på rengøring/madlavning: Rengøring/Madlavning
Oversigt. 1 Gennemgående eksempel: Højde og vægt. 2 Korrelation. 3 Regressionsanalyse (kap 11) 4 Mindste kvadraters metode
 4 Mindste kvadraters metode") Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Oversigt 1 Gennemgående eksempel: Højde og vægt 2 Korrelation 3 Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse
Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Oversigt 1 Gennemgående eksempel: Højde og vægt 2 Korrelation 3 Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse
Forelæsning 11: Kapitel 11: Regressionsanalyse
 Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks Tekniske Universitet 2800
Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks Tekniske Universitet 2800
3.600 kg og den gennemsnitlige fødselsvægt kg i stikprøven.
 PhD-kursus i Basal Biostatistik, efterår 2006 Dag 1, onsdag den 6. september 2006 Eksempel: Sammenhæng mellem moderens alder og fødselsvægt I dag: Introduktion til statistik gennem analyse af en stikprøve
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 1, onsdag den 6. september 2006 Eksempel: Sammenhæng mellem moderens alder og fødselsvægt I dag: Introduktion til statistik gennem analyse af en stikprøve
Anvendt Statistik Lektion 5. Sammenligning af to grupper * Sammenligning af middelværdier * Sammenligning af andele
 Anvendt Statistik Lektion 5 Sammenligning af to grupper * Sammenligning af middelværdier * Sammenligning af andele Motiverende eksempel Antal minutter brugt på rengøring/madlavning: Rengøring/Madlavning
Anvendt Statistik Lektion 5 Sammenligning af to grupper * Sammenligning af middelværdier * Sammenligning af andele Motiverende eksempel Antal minutter brugt på rengøring/madlavning: Rengøring/Madlavning
Økonometri 1. Kvalitative variabler. Kvalitative variabler. Dagens program. Kvalitative variable 8. marts 2006
 Dagens program Økonometri 1 Kvalitative variable 8. marts 2006 Kvalitative variabler som forklarende variabler i en lineær regressionsmodel (Wooldridge kap. 7.1-7.4) Kvalitative variabler generelt Dummy
Dagens program Økonometri 1 Kvalitative variable 8. marts 2006 Kvalitative variabler som forklarende variabler i en lineær regressionsmodel (Wooldridge kap. 7.1-7.4) Kvalitative variabler generelt Dummy
Mantel-Haenszel analyser. Stratificerede epidemiologiske analyser
 Mantel-Haensel analyser Stratificerede epidemiologiske analyser 1 Den epidemiologiske synsvinkel: 1) Oftest asymmetriske (kausale) sammenhænge (Eksposition Sygdom/død) 2) Risikoen vurderes bedst ved hjælp
Mantel-Haensel analyser Stratificerede epidemiologiske analyser 1 Den epidemiologiske synsvinkel: 1) Oftest asymmetriske (kausale) sammenhænge (Eksposition Sygdom/død) 2) Risikoen vurderes bedst ved hjælp
Multipel Lineær Regression
 Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk model Specificer
Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk model Specificer
Eksamen i Statistik for biokemikere. Blok
 Eksamen i Statistik for biokemikere. Blok 2 2007. Vejledende besvarelse 22-01-2007, Niels Richard Hansen Bemærkning: Flere steder er der givet en argumentation (f.eks. baseret på konfidensintervaller)
Eksamen i Statistik for biokemikere. Blok 2 2007. Vejledende besvarelse 22-01-2007, Niels Richard Hansen Bemærkning: Flere steder er der givet en argumentation (f.eks. baseret på konfidensintervaller)
Faculty of Health Sciences. Logistisk regression: Kvantitative forklarende variable
 Faculty of Health Sciences Logistisk regression: Kvantitative forklarende variable Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Sammenhæng
Faculty of Health Sciences Logistisk regression: Kvantitative forklarende variable Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Sammenhæng
Morten Frydenberg 14. marts 2006
 Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik 1 RESUME: 2 2. gang: 2006 Institut for Biostatistik, Århus Universitet MPH 1. studieår Specialmodul 4 Cand. San. uddannelsen
Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik 1 RESUME: 2 2. gang: 2006 Institut for Biostatistik, Århus Universitet MPH 1. studieår Specialmodul 4 Cand. San. uddannelsen
Logistisk regression. Statistik Kandidatuddannelsen i Folkesundhedsvidenskab
 Logistis regression Statisti Kandidatuddannelsen i Folesundhedsvidensab Multipel logistis regression Antagelser: Binære observationer (Y i, i=,.,n) f.es Ja/Nej Høj/Lav Død/Levende Kodet: / 0 Y i uafhængige
Logistis regression Statisti Kandidatuddannelsen i Folesundhedsvidensab Multipel logistis regression Antagelser: Binære observationer (Y i, i=,.,n) f.es Ja/Nej Høj/Lav Død/Levende Kodet: / 0 Y i uafhængige
Logistisk Regression - fortsat
 Logistisk Regression - fortsat Likelihood Ratio test Generel hypotese test Modelanalyse Indtil nu har vi set på to slags modeller: 1) Generelle Lineære Modeller Kvantitav afhængig variabel. Kvantitative
Logistisk Regression - fortsat Likelihood Ratio test Generel hypotese test Modelanalyse Indtil nu har vi set på to slags modeller: 1) Generelle Lineære Modeller Kvantitav afhængig variabel. Kvantitative
Morten Frydenberg 26. april 2004
 Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik RESUME: 2 2. gang: 2002 Institut for Biostatistik, Århus Universitet MPH. studieår Specialmodul 4 Cand. San. uddannelsen.
Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik RESUME: 2 2. gang: 2002 Institut for Biostatistik, Århus Universitet MPH. studieår Specialmodul 4 Cand. San. uddannelsen.
Logistisk regression
 Logistisk regression Anvendt statistik Anders Tolver Jensen Institut for Grundvidenskab og Miljø Onsdag d. 25/2-2009 ATJ (IGM KU-LIFE) Logistisk regression Anvendt statistik 25/2-2009 1 / 12 (Multinomial)
Logistisk regression Anvendt statistik Anders Tolver Jensen Institut for Grundvidenskab og Miljø Onsdag d. 25/2-2009 ATJ (IGM KU-LIFE) Logistisk regression Anvendt statistik 25/2-2009 1 / 12 (Multinomial)
Tema. Model og modelkontrol ( Fx. en normalfordelt obs. række m. kendt varians) Estimation af parametre. Fordeling. Hypotese og test. Teststørrelse.
 Estimation af parametre. Fordeling. Hypotese og test. Teststørrelse.") Tema Model og modelkontrol ( Fx. en normalfordelt obs. række m. kendt varians) Estimation af parametre. Fordeling. (Fx. x. µ) Hypotese og test. Teststørrelse. (Fx. H 0 : µ = µ 0 ) konfidensintervaller
Tema Model og modelkontrol ( Fx. en normalfordelt obs. række m. kendt varians) Estimation af parametre. Fordeling. (Fx. x. µ) Hypotese og test. Teststørrelse. (Fx. H 0 : µ = µ 0 ) konfidensintervaller
Statistik og skalavalidering Synopsis. Eksamensnumre 15, 33 og 45
 Statistik og skalavalidering Synopsis Københavns Universitet Folkesundhedsvidenskab, 7. semester Typografiske enheder: 22.615 December 2010 Indholdsfortegnelse 1.0 Indledning... 3 1.1 Karakteristika af
Statistik og skalavalidering Synopsis Københavns Universitet Folkesundhedsvidenskab, 7. semester Typografiske enheder: 22.615 December 2010 Indholdsfortegnelse 1.0 Indledning... 3 1.1 Karakteristika af
ØVELSER Statistik, Logistikøkonom Lektion 8 og 9: Simpel og multipel lineær regression
 ! ØVELSER Statistik, Logistikøkonom Lektion 8 og 9: Simpel og multipel lineær regression Eksempel 1 AT OPSTILLE EN SIMPEL LINEÆR REGRESSIONSMODEL - GENNEMGÅS AF JAKOB Et stort lager måler løbende sine
! ØVELSER Statistik, Logistikøkonom Lektion 8 og 9: Simpel og multipel lineær regression Eksempel 1 AT OPSTILLE EN SIMPEL LINEÆR REGRESSIONSMODEL - GENNEMGÅS AF JAKOB Et stort lager måler løbende sine
MPH specialmodul i biostatistik og epidemiologi SAS-øvelser vedr. case-control studie af malignt melanom.
 MPH specialmodul i biostatistik og epidemiologi SAS-øvelser vedr. case-control studie af malignt melanom. For at I skal kunne regne på tallene fra undersøgelsen har vi taget en delmængde af variablene
MPH specialmodul i biostatistik og epidemiologi SAS-øvelser vedr. case-control studie af malignt melanom. For at I skal kunne regne på tallene fra undersøgelsen har vi taget en delmængde af variablene
Økonometri 1. Dummyvariabler 13. oktober Økonometri 1: F10 1
 Økonometri 1 Dummyvariabler 13. oktober 2006 Økonometri 1: F10 1 Dagens program Dummyvariabler i den multiple regressionsmodel (Wooldridge kap. 7.3-7.6) Dummy variabler for kvalitative egenskaber med flere
Økonometri 1 Dummyvariabler 13. oktober 2006 Økonometri 1: F10 1 Dagens program Dummyvariabler i den multiple regressionsmodel (Wooldridge kap. 7.3-7.6) Dummy variabler for kvalitative egenskaber med flere
Indvandrere og efterkommere i foreninger er frivillige i samme grad som danskere
 Indvandrere og efterkommere i foreninger er frivillige i samme grad som danskere Bilag I afrapportering af signifikanstest i tabeller i artikel er der benyttet følgende illustration af signifikans: * p
Indvandrere og efterkommere i foreninger er frivillige i samme grad som danskere Bilag I afrapportering af signifikanstest i tabeller i artikel er der benyttet følgende illustration af signifikans: * p
1 Hb SS Hb Sβ Hb SC = , (s = )
") PhD-kursus i Basal Biostatistik, efterår 2006 Dag 6, onsdag den 11. oktober 2006 Eksempel 9.1: Hæmoglobin-niveau og seglcellesygdom Data: Hæmoglobin-niveau (g/dl) for 41 patienter med en af tre typer seglcellesygdom.
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 6, onsdag den 11. oktober 2006 Eksempel 9.1: Hæmoglobin-niveau og seglcellesygdom Data: Hæmoglobin-niveau (g/dl) for 41 patienter med en af tre typer seglcellesygdom.
Synopsis til kursus i Statistik og skalavalidering på Folkesundhedsvidenskab
 Synopsis til kursus i Statistik og skalavalidering på Folkesundhedsvidenskab Eksamensnr. 26, 41 og 11 Anslag (uden tabeller og figurer): 23.933 1 1. Indledning...3 2. Deskriptiv statistik...3 3. Indledende
Synopsis til kursus i Statistik og skalavalidering på Folkesundhedsvidenskab Eksamensnr. 26, 41 og 11 Anslag (uden tabeller og figurer): 23.933 1 1. Indledning...3 2. Deskriptiv statistik...3 3. Indledende
1 Multipel lineær regression
 Indhold 1 Multipel lineær regression 2 1.1 Regression med 2 eksponeringsvariable......................... 2 1.2 Fortolkning og estimation................................ 3 1.3 AnovaTabel og multipel R
Indhold 1 Multipel lineær regression 2 1.1 Regression med 2 eksponeringsvariable......................... 2 1.2 Fortolkning og estimation................................ 3 1.3 AnovaTabel og multipel R
Multipel regression. Data fra opgave 3 side 453: Multipel regressionsmodel: Y = α + β 1 x 1 + β 2 x 2 + ǫ. hvor ǫ N(0, σ 2 ).
.") Program 1. multipel regression 2. polynomiel regression (og andre kurver) 3. kategoriske variable 4. Determinationkoefficient og justeret determinationskoefficient 5. ANOVA-tabel 1/13 Multipel regression
Program 1. multipel regression 2. polynomiel regression (og andre kurver) 3. kategoriske variable 4. Determinationkoefficient og justeret determinationskoefficient 5. ANOVA-tabel 1/13 Multipel regression
Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06)
") Afdeling for Biostatistik Bo Martin Bibby 23. november 2006 Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06) Vi betragter 4699 personer fra Framingham-studiet. Der er oplysninger om follow-up
Afdeling for Biostatistik Bo Martin Bibby 23. november 2006 Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06) Vi betragter 4699 personer fra Framingham-studiet. Der er oplysninger om follow-up
1 Multipel lineær regression
 1 Multipel lineær regression Regression med 2 eksponeringsvariable Fortolkning og estimation AnovaTabel og multipel R 2 Ensidet variansanalyse: Dummy kodning Kovariansanalyse og effektmodifikation Tosidet
1 Multipel lineær regression Regression med 2 eksponeringsvariable Fortolkning og estimation AnovaTabel og multipel R 2 Ensidet variansanalyse: Dummy kodning Kovariansanalyse og effektmodifikation Tosidet
ØVELSER Statistik, Logistikøkonom Lektion 8 og 9: Simpel og multipel lineær regression
 ! ØVELSER Statistik, Logistikøkonom Lektion 8 og 9: Simpel og multipel lineær regression Eksempel 1 AT OPSTILLE EN SIMPEL LINEÆR REGRESSIONSMODEL - GENNEMGÅS AF JAKOB Et stort lager måler løbende sine
! ØVELSER Statistik, Logistikøkonom Lektion 8 og 9: Simpel og multipel lineær regression Eksempel 1 AT OPSTILLE EN SIMPEL LINEÆR REGRESSIONSMODEL - GENNEMGÅS AF JAKOB Et stort lager måler løbende sine
Uge 43 I Teoretisk Statistik, 21. oktober Forudsigelser
 Uge 43 I Teoretisk Statistik,. oktober 3 Simpel lineær regressionsanalyse Forudsigelser Fortolkning af regressionsmodellen Ekstreme observationer Transformationer Sammenligning af to regressionslinier
Uge 43 I Teoretisk Statistik,. oktober 3 Simpel lineær regressionsanalyse Forudsigelser Fortolkning af regressionsmodellen Ekstreme observationer Transformationer Sammenligning af to regressionslinier
Psykisk arbejdsmiljø og stress
 Psykisk arbejdsmiljø og stress - Hvilke faktorer har indflydelse på det psykiske arbejdsmiljø og medarbejdernes stress Marts 2018 Konklusion Denne analyse forsøger at afklare, hvilke faktorer der påvirker
Psykisk arbejdsmiljø og stress - Hvilke faktorer har indflydelse på det psykiske arbejdsmiljø og medarbejdernes stress Marts 2018 Konklusion Denne analyse forsøger at afklare, hvilke faktorer der påvirker
Tandstatus hos søskende
 Tandstatus hos søskende Af Bodil Helbech Kleist, [email protected] Formålet med dette analysenotat er at undersøge forskelle i tandsundheden mellem søskende, herunder betydningen af hvilket nummer i børneflokken,
Tandstatus hos søskende Af Bodil Helbech Kleist, [email protected] Formålet med dette analysenotat er at undersøge forskelle i tandsundheden mellem søskende, herunder betydningen af hvilket nummer i børneflokken,
Logistisk Regression. Repetition Fortolkning af odds Test i logistisk regression
 Logistisk Regression Repetition Fortolkning af odds Test i logistisk regression Logistisk Regression: Definitioner For en binær (0/) variabel Y antager vi P(Y)p P(Y0)-p Eksempel: Bil til arbejde vs alder
Logistisk Regression Repetition Fortolkning af odds Test i logistisk regression Logistisk Regression: Definitioner For en binær (0/) variabel Y antager vi P(Y)p P(Y0)-p Eksempel: Bil til arbejde vs alder
Konfidensintervaller og Hypotesetest
 Konfidensintervaller og Hypotesetest Konfidensinterval for andele χ -fordelingen og konfidensinterval for variansen Hypoteseteori Hypotesetest af middelværdi, varians og andele Repetition fra sidst: Konfidensintervaller
Konfidensintervaller og Hypotesetest Konfidensinterval for andele χ -fordelingen og konfidensinterval for variansen Hypoteseteori Hypotesetest af middelværdi, varians og andele Repetition fra sidst: Konfidensintervaller
Velkommen til kurset. Teoretisk Statistik. Lærer: Niels-Erik Jensen
 1 Velkommen til kurset Teoretisk Statistik Lærer: Niels-Erik Jensen Plan for i dag: 1. Eks: Er euro'en skæv? 4. Praktiske informationer 2. Eks: Regressionsmodel (kap. 1) 5. Lidt om kursets indhold 3. Hvad
1 Velkommen til kurset Teoretisk Statistik Lærer: Niels-Erik Jensen Plan for i dag: 1. Eks: Er euro'en skæv? 4. Praktiske informationer 2. Eks: Regressionsmodel (kap. 1) 5. Lidt om kursets indhold 3. Hvad
UNDERVISNINGSEFFEKT-MODELLEN 2006 METODE OG RESULTATER
 UNDERVISNINGSEFFEKT-MODELLEN 2006 METODE OG RESULTATER Undervisningseffekten udregnes som forskellen mellem den forventede og den faktiske karakter i 9. klasses afgangsprøve. Undervisningseffekten udregnes
UNDERVISNINGSEFFEKT-MODELLEN 2006 METODE OG RESULTATER Undervisningseffekten udregnes som forskellen mellem den forventede og den faktiske karakter i 9. klasses afgangsprøve. Undervisningseffekten udregnes
Program. Konfidensinterval og hypotesetest, del 2 en enkelt normalfordelt stikprøve I SAS. Øvelse: effekt af diæter
 Program Konfidensinterval og hypotesetest, del 2 en enkelt normalfordelt stikprøve Helle Sørensen E-mail: [email protected] I formiddag: Øvelse: effekt af diæter. Repetition fra sidst... Parrede og ikke-parrede
Program Konfidensinterval og hypotesetest, del 2 en enkelt normalfordelt stikprøve Helle Sørensen E-mail: [email protected] I formiddag: Øvelse: effekt af diæter. Repetition fra sidst... Parrede og ikke-parrede
Økonometri 1. Inferens i den lineære regressionsmodel 2. oktober Økonometri 1: F8 1
 Økonometri 1 Inferens i den lineære regressionsmodel 2. oktober 2006 Økonometri 1: F8 1 Dagens program Opsamling om asymptotiske egenskaber: Asymptotisk normalitet Asymptotisk efficiens Test af flere lineære
Økonometri 1 Inferens i den lineære regressionsmodel 2. oktober 2006 Økonometri 1: F8 1 Dagens program Opsamling om asymptotiske egenskaber: Asymptotisk normalitet Asymptotisk efficiens Test af flere lineære
Dagens Emner. Likelihood teori. Lineær regression (intro) p. 1/22
 p. 1/22") Dagens Emner Likelihood teori Lineær regression (intro) p. 1/22 Likelihood-metoden M : X i N(µ,σ 2 ) hvor µ og σ 2 er ukendte Vi har, at L(µ,σ 2 ) = ( 1 2πσ 2)n/2 e 1 2σ 2 P n (x i µ) 2 er tætheden som
Dagens Emner Likelihood teori Lineær regression (intro) p. 1/22 Likelihood-metoden M : X i N(µ,σ 2 ) hvor µ og σ 2 er ukendte Vi har, at L(µ,σ 2 ) = ( 1 2πσ 2)n/2 e 1 2σ 2 P n (x i µ) 2 er tætheden som
Rettevejledning til eksamen i Kvantitative metoder 1, 2. årsprøve 2. januar 2007
 Rettevejledning til eksamen i Kvantitative metoder 1,. årsprøve. januar 007 I rettevejledningen henvises der til Berry and Lindgren "Statistics Theory and methods"(b&l) hvis ikke andet er nævnt. Opgave
Rettevejledning til eksamen i Kvantitative metoder 1,. årsprøve. januar 007 I rettevejledningen henvises der til Berry and Lindgren "Statistics Theory and methods"(b&l) hvis ikke andet er nævnt. Opgave
To-sidet varians analyse
 To-sidet varians analyse Repetition En-sidet ANOVA Parvise sammenligninger, Tukey s test Model begrebet To-sidet ANOVA Tre-sidet ANOVA Blok design SPSS ANOVA - definition ANOVA (ANalysis Of VAriance),
To-sidet varians analyse Repetition En-sidet ANOVA Parvise sammenligninger, Tukey s test Model begrebet To-sidet ANOVA Tre-sidet ANOVA Blok design SPSS ANOVA - definition ANOVA (ANalysis Of VAriance),
9. Chi-i-anden test, case-control data, logistisk regression.
 Biostatistik - Cand.Scient.San. 2. semester Karl Bang Christensen Biostatististisk afdeling, KU [email protected], 35327491 9. Chi-i-anden test, case-control data, logistisk regression. http://biostat.ku.dk/~kach/css2014/
Biostatistik - Cand.Scient.San. 2. semester Karl Bang Christensen Biostatististisk afdeling, KU [email protected], 35327491 9. Chi-i-anden test, case-control data, logistisk regression. http://biostat.ku.dk/~kach/css2014/
Basal Statistik Logistisk Regression. Dagens Tekst E Sædvanlig Linear Regression (Repetition) Basal Statistik - Logistisk regression 1
 Basal Statistik - Logistisk regression 1") Basal Statistik Logistisk Regression Judith L. Jacobsen, PhD. Lene Theil Skovgaard http://staff.pubhealth.ku.dk/~lts/basal13_ [email protected] Dagens Tekst Logistisk regression Binære data Logit transformation
Basal Statistik Logistisk Regression Judith L. Jacobsen, PhD. Lene Theil Skovgaard http://staff.pubhealth.ku.dk/~lts/basal13_ [email protected] Dagens Tekst Logistisk regression Binære data Logit transformation
Kapitel 12 Variansanalyse
 Kapitel 12 Variansanalyse Peter Tibert Stoltze stat@peterstoltzedk Elementær statistik F2011 Version 7 april 2011 1 / 43 Indledning Sammenligning af middelværdien i to grupper indenfor en stikprøve kan
Kapitel 12 Variansanalyse Peter Tibert Stoltze stat@peterstoltzedk Elementær statistik F2011 Version 7 april 2011 1 / 43 Indledning Sammenligning af middelværdien i to grupper indenfor en stikprøve kan
Eksempel Multipel regressions model Den generelle model Estimation Multipel R-i-anden F-test for effekt af prædiktorer Test for vekselvirkning
 1 Multipel regressions model Eksempel Multipel regressions model Den generelle model Estimation Multipel R-i-anden F-test for effekt af prædiktorer Test for vekselvirkning PSE (I17) ASTA - 11. lektion
1 Multipel regressions model Eksempel Multipel regressions model Den generelle model Estimation Multipel R-i-anden F-test for effekt af prædiktorer Test for vekselvirkning PSE (I17) ASTA - 11. lektion
Anvendt Statistik Lektion 6. Kontingenstabeller χ 2- test [ki-i-anden-test]
![Anvendt Statistik Lektion 6. Kontingenstabeller χ 2- test [ki-i-anden-test]](/thumbs/54/33241327.jpg "Anvendt Statistik Lektion 6. Kontingenstabeller χ 2- test [ki-i-anden-test]") Anvendt Statistik Lektion 6 Kontingenstabeller χ 2- test [ki-i-anden-test] Kontingenstabel Formål: Illustrere/finde sammenhænge mellem to kategoriske variable Opbygning: En celle for hver kombination af
Anvendt Statistik Lektion 6 Kontingenstabeller χ 2- test [ki-i-anden-test] Kontingenstabel Formål: Illustrere/finde sammenhænge mellem to kategoriske variable Opbygning: En celle for hver kombination af
Vejledende besvarelse af eksamen i Statistik for biokemikere, blok
 Opgave 1 Vejledende besvarelse af eksamen i Statistik for biokemikere, blok 2 2006 Inge Henningsen og Niels Richard Hansen Analysevariablen i denne opgave er variablen forskel, der for hver af 10 kvinder
Opgave 1 Vejledende besvarelse af eksamen i Statistik for biokemikere, blok 2 2006 Inge Henningsen og Niels Richard Hansen Analysevariablen i denne opgave er variablen forskel, der for hver af 10 kvinder
Lineære normale modeller (4) udkast
 udkast") E6 efterår 1999 Notat 21 Jørgen Larsen 2. december 1999 Lineære normale modeller (4) udkast 4.5 Regressionsanalyse 4.5.1 Præsentation 1 Regressionsanalyse handler om at undersøge hvordan én målt størrelse
E6 efterår 1999 Notat 21 Jørgen Larsen 2. december 1999 Lineære normale modeller (4) udkast 4.5 Regressionsanalyse 4.5.1 Præsentation 1 Regressionsanalyse handler om at undersøge hvordan én målt størrelse
Multipel regression. M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model
 M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model") Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
Skriftlig Eksamen ST501: Science Statistik Mandag den 11. juni 2007 kl. 15.00 18.00
 Skriftlig Eksamen ST501: Science Statistik Mandag den 11. juni 2007 kl. 15.00 18.00 Forskningsenheden for Statistik IMADA Syddansk Universitet Alle skriftlige hjælpemidler samt brug af lommeregner er tilladt.
Skriftlig Eksamen ST501: Science Statistik Mandag den 11. juni 2007 kl. 15.00 18.00 Forskningsenheden for Statistik IMADA Syddansk Universitet Alle skriftlige hjælpemidler samt brug af lommeregner er tilladt.
Kapitel 11 Lineær regression
 Kapitel 11 Lineær regression Peter Tibert Stoltze [email protected] Elementær statistik F2011 1 / 1 Indledning Vi modellerer en afhængig variabel (responset) på baggrund af en uafhængig variabel (stimulus),
Kapitel 11 Lineær regression Peter Tibert Stoltze [email protected] Elementær statistik F2011 1 / 1 Indledning Vi modellerer en afhængig variabel (responset) på baggrund af en uafhængig variabel (stimulus),
Økonometri 1. Inferens i den lineære regressionsmodel 25. september Økonometri 1: F6 1
 Økonometri 1 Inferens i den lineære regressionsmodel 25. september 2006 Økonometri 1: F6 1 Oversigt: De næste forelæsninger Statistisk inferens: hvorledes man med udgangspunkt i en statistisk model kan
Økonometri 1 Inferens i den lineære regressionsmodel 25. september 2006 Økonometri 1: F6 1 Oversigt: De næste forelæsninger Statistisk inferens: hvorledes man med udgangspunkt i en statistisk model kan
NATURVIDENSKABELIG KANDIDATEKSAMEN VED KØBENHAVNS UNIVERSITET.
 NATURVIDENSKABELIG KANDIDATEKSAMEN VED KØBENHAVNS UNIVERSITET. Eksamen i Statistik 1TS Teoretisk statistik Den skriftlige prøve Sommer 2005 3 timer - alle hjælpemidler tilladt Det er tilladt at skrive
NATURVIDENSKABELIG KANDIDATEKSAMEN VED KØBENHAVNS UNIVERSITET. Eksamen i Statistik 1TS Teoretisk statistik Den skriftlige prøve Sommer 2005 3 timer - alle hjælpemidler tilladt Det er tilladt at skrive