9. Chi-i-anden test, case-control data, logistisk regression.
|
|
|
- Kristen Dideriksen
- 10 år siden
- Visninger:
Transkript
1 Biostatistik - Cand.Scient.San. 2. semester Karl Bang Christensen Biostatististisk afdeling, KU [email protected], Chi-i-anden test, case-control data, logistisk regression. 1

2 bronkitis data hoster om natten som 14 årig bronkitis som 5 årig ja nej total ja nej total Hvis π ja = π nej = π ville vi estimere p =

3 Opgave 0 data fra artikel om dødelighed efter udskrivelse. Group 0: patients discharged on day of prediction of risk Group 1: patients who stayed additional 24 hours Alive (%) Died (%) total Group (72) 230 (28) 811 Group (87) 19 (13) 145 Hvis der er samme risiko π 0 = π 1 = π hvad ville vi da estimere den til at være. Daly et al. Reduction in mortality after inappropriate early discharge from intensive care unit: logistic regression triage model, BMJ 2001;322:

4 Obs. vs. forv. hoster om natten som 14 årig bronkitis som 5 årig ja nej total ja nej total Ville forvente at p = ud af de 273 hostede om natten som 14-årige. 4

5 Tilsvarende ville vi forvente at 1046 p = ud af de 1046 hostede om natten som 14-årige. Forventet antal i en givet celle beregnes som rækkesum søjlesum total 5

6 Opgave 1 data fra artikel om dødelighed efter udskrivelse. Group 0: patients discharged on day of prediction of risk Group 1: patients who stayed additional 24 hours Alive (%) Died (%) total Group (72) 230 (28) 811 Group (87) 19 (13) 145 Beregn den forventede tabel. Daly et al. Reduction in mortality after inappropriate early discharge from intensive care unit: logistic regression triage model, BMJ 2001;322:

7 χ 2 test Sammenligner observerede antal med forventede antal under nulhypotesen. Test for H 0 : π ja = π nej observeret forventet 1 2 total 1 O 11 O 12 E 11 E 12 2 O 21 O 22 E 21 E 22 total χ 2 = (O 11 E 11 ) 2 E 11 + (O 12 E 12 ) 2 E 12 + (O 21 E 21 ) 2 E 21 + (O 22 E 22 ) 2 Store værdier: data passer dårligt med H 0 χ 2 -fordeling med 1 frihedsgrad. Kan beregne og slå p-værdi op (tabel A5). E 22 7

8 χ 2 test - bronkitis data χ 2 = ( ) observeret forventet bronkitis ja nej total ja nej total ( ) ( ) ( ) = 12.1 Kan slå p-værdi op i tabel A5 (χ 2 -fordeling med 1 frihedsgrad) p <
2 55.5 + (1002 990.5)2 990.5 = 12.")
9 Opgave 2 dødelighed efter udskrivelse. Group 1: patients who stayed additional 24 hours Group 2: patients who stayed additional 48 hours Alive (%) Died (%) total Group (87) 19 (13) 145 Group 2 86 (83) 17 (17) 103 forventede antal under nulhypotesen: Alive Died total Group Group Beregn χ 2 testet. Daly et al. Reduction in mortality after inappropriate early discharge from intensive care unit: logistic regression triage model, BMJ 2001;322:

10 χ 2 test i 2 2 tabeller status population ja nej total ssh 1 a b n 1 π 1 2 c d n 2 π 2 total s 1 s 2 N Nulhypotese - ingen association H 0 : π 1 = π 2 (ækvivalent med H 0 : OR = 1 og med H 0 : RR = 1): nemmere formel χ 2 = (ad bc)2 N n 1 n 2 s 1 s 2 χ 2 -fordelt med 1 frihedsgrad. 10
2 N n 1 n 2 s 1 s 2 χ 2 -fordelt med 1 frihedsgrad.")
11 Opgave 2 revisited dødelighed efter udskrivelse. Group 1: patients who stayed additional 24 hours Group 2: patients who stayed additional 48 hours Alive (%) Died (%) total Group (87) 19 (13) 145 Group 2 86 (83) 17 (17) 103 Beregn χ 2 testet med den nemme formel og sammenlign med resultatet fra tidligere. Daly et al. Reduction in mortality after inappropriate early discharge from intensive care unit: logistic regression triage model, BMJ 2001;322:

12 R C tabel (dvs. R rækker og C søjler) Forventet antal i celle i j beregnes som Teststørrelse række sum(i) søjle sum(j) E ij = Total χ 2 = alle celler (O ij E ij ) 2 E ij (ingen nem formel). Under nulhypotesen χ 2 -fordelt med frihedsgrader. (R 1) (C 1) (I en 2 2 tabel er R = C = 2, dvs. (2 1) (2 1) = 1 frihedsgrad.) 12
. Under nulhypotesen χ 2 -fordelt med frihedsgrader.")
13 Odds anden måde at udtrykke sandsynlighed kan regne frem og tilbage O = p/(1 p) og p = O/(1 + O). Tre ækvivalente formuleringer H 0 : π 1 = π 2 H 0 : RR = π 1 π 2 = 1 H 0 : OR = π 1/(1 π 1 ) π 2 /(1 π 2 ) = 1 Odds giver nemmere beregninger, men er sværere at forstå. Nødvendigt at bruge odds til: (i) case-control, (ii) logistisk regression 13
 π 2 /(1 π 2 ) = 1 Odds giver nemmere beregninger, men er sværere at forstå.")
14 For at regne på odds transformeres med logaritmen Test af nulhypotesen H 0 : OR = 1 kan laves som z-test: Vi tester H 0 : β = log(or) = 0 Test z = β/s.e.(β). Slå op i Tabel A1. Bemærk s.e.(β) = s.e.(log(or)) Vi bruger altid den naturlige logaritme ( ln ). 14
 = s.e.(log(or)) Vi bruger altid den naturlige logaritme ( ln ).")
15 Case-control data Data indsamlet ved at man har nogen cases og derefter indsamler data på sammenlignelige kontroller (typisk 5 gange så mange). Man kan ikke beregne ikke beregne risikoestimater. Man kan beregne OR præcis som hvis data havde været indsamlet som et kohorte studium. Fordel: nemmere at få mange cases (og dermed større styrke) end i kohortestudie Ulemper: ingen ordning hen over tid (først eksponering siden sygdom) kan kun estimere OR. Mulig bias (f.eks. forsk. information for cases og kontroller). 15
 end i kohortestudie Ulemper: ingen ordning hen over tid (først")
16 Case-control data Hele populationen case control total exposed A B A+B unexposed C D C+D total A+C B+D A+B+C+D Sampler cases med hyppighed f 1, kontroller med hyppighed f 2. Typisk er f 1 > f 2. Den forventede værdi af samplet bliver case control total exposed f 1 A f 2 B f 1 A+f 2 B unexposed f 1 C f 2 D f 1 C+f 2 D total f 1 (A+C) f 2 (B+D) f 1 (A+C)+f 2 (B+D) 16

17 Den forventede værdi af odds-ratio i case-control studiet er f 1 f 2 AD f 1 f 2 BC = AD BC Bemærk risiko hos eksponerede er A/(A + B). I case-control studiet får vi f 1 A/(f 1 A + f 2 C) risiko hos ikke-eksp. C/(C + D). I case-control studiet får vi f 1 C/(f 1 C + f 2 D). 17
.")
18 logistisk regression 2. sem: binomialfordeling (risiko) 1. sem: normalfordeling (middelværdi) π svarer til MEAN p = d/n svarer til x s.e.(p) svarer til s.e.( x) = SEM 2 2 tabel svarer til t-test logistisk regression svarer til lineær regression 18

19 Eksempel: lungefunktion hos peruvianske børn FEV1 normalfordeling, middelværdi, t-test, lineær regression. respsymp= { 1, symptomer; 0, ellers. vi vil sige noget om en risiko/sandsynlighed p = P (respsymp = 1), vi ved at 0 < p < 1, men observerer kun respsymp = 0 eller respsymp = 1. 19
, vi")
20 20
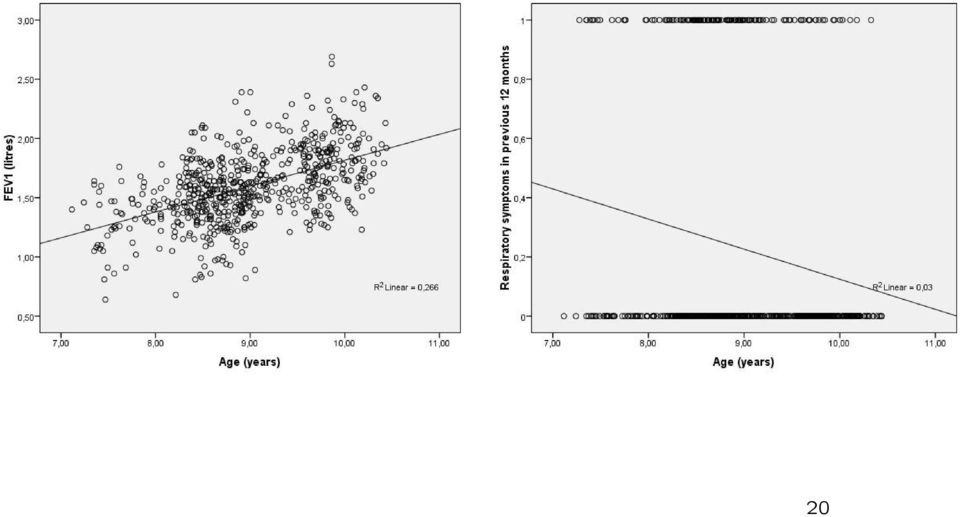
21 Transformation 0 < p < 1 0 < p 1 p < p < log( 1 p ) < ssh odds log(odds) p/(1 p) log(p/(1 p)) p p/(1 p) 21
22 Transformation Regner på log(odds) skalaen for at lave regression p = 0.01 ODDS = p 1 p = p = 0.05 ODDS = p 1 p = p = 0.10 ODDS = p 1 p = p = 0.50 ODDS = p 1 p = p log(odds) = log( 1 p ) = 4.60 p log(odds) = log( 1 p ) = 2.95 p log(odds) = log( 1 p ) = 2.20 p log(odds) = log( 1 p ) = 0 22
23 Data En linie for hvert barn. En søjle for hver variabel id fev1 age height sex Y = respsymp 1 1,56 9,59 124, ,18 7,49 111, ,87 9,86 135, ,49 8,59 119, ,62 8,97 120, : Y i = 1, hvis barn i har haft symptomer, Y i = 0 ellers. 23
24 Logistisk regression Modellen er givet ved dvs. kan regne tilbage log(odds i ) = β 0 + β 1 alder i P (Y log( i = 1) 1 P (Y i = 1) ) = β 0 + β 1 alder i P (Y i = 1) = exp(β 0 + β 1 alder i ) 1 + exp(β 0 + β alder i ) 24
25 Prædiktion for alder=7,8 er sandsynligheden π 7 = exp(β 0 + β 1 7) 1 + exp(β 0 + β 1 7) og π 8 = exp(β 0 + β 1 8) 1 + exp(β 0 + β 1 8). Effekten af alder så β = log(or) OR = (π 8/(1 π 8 )) (π 7 /(1 π 7 )) = = exp(β 1). 25
26 Opgave 3 Artikel om apnø. Søvn-apnø og andre variables effekt på hypertension, logistisk regression: hvordan køn påvirker (logaritmen til) odds Variable Estimate (95% CI) OR Intercept ( to ) Sex (male) ( to 0.383) 1.17 Lav et 95% sikkerhedsinterval for OR. Beregn en p-værdi ud fra sikkerhedsintervallet. Lavie et al. Obstructive sleep apnoea syndrome as a risk factor for hypertension: population study, BMJ 2000;320: Vi bruger altid den naturlige logaritme ( ln ). 26
27 Alder og risiko for malaria Hvis der er data nok og der inddeles i aldersgrupper kunne vi f.eks. se dette ALDER ANTAL MALARIA : kun muligt med mange data. Problem med afrunding. 27
28 Sandsynlighed, odds, log-odds ALDER ANTAL MALARIA SSH ODDS LOG(ODDS) : 28
29 29
30 Logistisk regression - alder og risiko for malaria Stikprøve (n=303) fra en population i Sudan indeholder oplysning om forekomst af klinisk malaria og alder. Definer Y i = { 1, person i har malaria, 0, person i er rask, og beskriv P (Y i = 1) ved regressionsmodellen: log(odds i ) = β 0 + β 1 alder i β beskriver hvordan ssh ændrer sig med alder på logit-skalaen 30
31 Som før kan vi regne tilbage P (Y i = 1) = exp(β 0 + β 1 alder i ) 1 + exp(β 0 + β 1 alder i ), OR for en x + 1 årig mod en x årig er exp(β): β > 0: ssh øges β < 0: ssh falde β 0 beskriver ssh for malaria hos en person med alder 0: p = exp(β 0 + 0) 1 + exp(β 0 + 0), hvilket jo ikke giver særlig meget mening. 31
32 Estimaterne (beregnet på computer) bliver Parameter Estimate Std Err INTERCEPT ALDER (dvs. β 0 = og β 1 = 0.737) Alder har beskyttende effekt, odds ratio er exp( ) = 0.47, dvs. når alder øges med 1, falder odds med 53%. 95% SI for β 1 = log(or) er [ ), ] = [ 1.034, 0.446]. 95% SI for OR er givet ved [exp( 1.034), exp( 0.446)] = [0.35, 0.64]. 32
33 Vi kan udregne konsekvenser af modellen baseret på vores estimater - prædiktere risikoen for at få malaria som 6 årig: P (Y i = 1) = exp(β 0 + β 1 6) 1 + exp(β 0 + β 1 6) exp( ) = 1 + exp( ) = Kan teste nulhypotesen om at der ikke er sammenhæng mellem alder og malariarisiko: H 0 : β 1 = 0 Z = = 4.93 (slå op i Tabel A1, p <
34 Opgave 4 Søvn-apnø og hypertension 0/1 variabel, logistisk regression: hvordan apnoea-hypopnoea index påvirker (logaritmen til) odds Variable Estimate (95% CI) OR Intercept ( to ) Apnoea-hypopnoea index (10 events) (0.275 to 0.456) 1.37 Beregn prædikteret ssh for hypertension for værdi 1 af apnoeahypopnoen index. Hvordan ændrer det sig hvis værdien er 2? Vi bruger altid den naturlige logaritme ( ln ). 34
35 Malaria Vi ved nu at alder påvirker risikoen. Hvis vi skal teste om der er en effekt af køn har vi to muligheder 1. Er der effekt af køn? 2. Er der effekt af køn kontrolleret for effekten af alder? Sammenhæng mellem køn og risiko + - n ssh OR drenge piger Hvad hvis vi inddeler i aldersgrupper 35
36 Opdelt i aldersgrupper + - n ssh OR drenge piger drenge piger drenge piger drenge piger altså: effekten er lidt mindre indenfor aldersgrupper 36
37 Multipel logistisk regression Vi kan korrigere for effekt af andre variable Udvid logistisk regression log(odds i ) = β 0 + β 1 alder i ved at tilføje flere forklarende variable log(odds i ) = β 0 + β 1 alder i + β 2 køn i 37
38 For 2 2 tabel er logistisk regression bare det samme som før hoster ja nej total p odds /273=0.095 p/(1-p)=26/247= /1046=0.042 p/(1-p)=44/1002= Variable: Y i viser om barn i hoster. Eksponering X i er bronkitis. Datasæt med 1319 linier. H 0 : π 1 = π 2 H 0 : RR = 1 H 0 : OR = 1 38
39 Estimater for β 0 og β 1 (beregnet i SPSS) bliver Altså: β 0 = og β 1 =0.874, dette passer med exp(-3.126)/(1+exp(-3.126))=0.042 exp( )/(1+exp( ))=0.095 videre ses = s.e.(β 1 ) = s.e.(log(or)) =
40 Test af nulhypotesen H 0 : OR = 1 kan laves som z-test: Vi tester H 0 : β = log(or) = 0 Test z = β/s.e.(β) = 0.874/0.257 = Slå op i Tabel A1. 40
Logistisk regression
 Logistisk regression http://biostat.ku.dk/ kach/css2 Thomas A Gerds & Karl B Christensen 1 / 18 Logistisk regression I dag 1 Binær outcome variable død : i live syg : rask gravid : ikke gravid etc 1 prædiktor
Logistisk regression http://biostat.ku.dk/ kach/css2 Thomas A Gerds & Karl B Christensen 1 / 18 Logistisk regression I dag 1 Binær outcome variable død : i live syg : rask gravid : ikke gravid etc 1 prædiktor
Logistisk regression. Basal Statistik for medicinske PhD-studerende November 2008
 Logistisk regression Basal Statistik for medicinske PhD-studerende November 2008 Bendix Carstensen Steno Diabetes Center, Gentofte & Biostatististisk afdeling, Københavns Universitet [email protected] www.biostat.ku.dk/~bxc
Logistisk regression Basal Statistik for medicinske PhD-studerende November 2008 Bendix Carstensen Steno Diabetes Center, Gentofte & Biostatististisk afdeling, Københavns Universitet [email protected] www.biostat.ku.dk/~bxc
Besvarelse af opgavesættet ved Reeksamen forår 2008
 Besvarelse af opgavesættet ved Reeksamen forår 2008 10. marts 2008 1. Angiv formål med undersøgelsen. Beskriv kort hvordan cases og kontroller er udvalgt. Vurder om kontrolgruppen i det aktuelle studie
Besvarelse af opgavesættet ved Reeksamen forår 2008 10. marts 2008 1. Angiv formål med undersøgelsen. Beskriv kort hvordan cases og kontroller er udvalgt. Vurder om kontrolgruppen i det aktuelle studie
Simpel og multipel logistisk regression
 Faculty of Health Sciences Logistisk regression Simpel og multipel logistisk regression 16. Maj 2012 Analyse af en binær responsvariabel. syg/rask, død/levende, ja/nej... Ud fra en eller flere forklarende
Faculty of Health Sciences Logistisk regression Simpel og multipel logistisk regression 16. Maj 2012 Analyse af en binær responsvariabel. syg/rask, død/levende, ja/nej... Ud fra en eller flere forklarende
Multipel regression. M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model
 M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model") Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
Mantel-Haenszel analyser. Stratificerede epidemiologiske analyser
 Mantel-Haensel analyser Stratificerede epidemiologiske analyser 1 Den epidemiologiske synsvinkel: 1) Oftest asymmetriske (kausale) sammenhænge (Eksposition Sygdom/død) 2) Risikoen vurderes bedst ved hjælp
Mantel-Haensel analyser Stratificerede epidemiologiske analyser 1 Den epidemiologiske synsvinkel: 1) Oftest asymmetriske (kausale) sammenhænge (Eksposition Sygdom/død) 2) Risikoen vurderes bedst ved hjælp
Morten Frydenberg 26. april 2004
 Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik RESUME: 2 2. gang: 2002 Institut for Biostatistik, Århus Universitet MPH. studieår Specialmodul 4 Cand. San. uddannelsen.
Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik RESUME: 2 2. gang: 2002 Institut for Biostatistik, Århus Universitet MPH. studieår Specialmodul 4 Cand. San. uddannelsen.
3 typer. Case-kohorte. Nested case-kontrol. Case-non case (klassisk case-kontrol us.)
") EPIDEMIOLOGI CASE-KONTROL STUDIER September 2011 Søren Friis Institut for Epidemiologisk Kræftforskning Kræftens Bekæmpelse Case kontrol studie 3 typer Case-kohorte Nested case-kontrol Case-non case (klassisk
EPIDEMIOLOGI CASE-KONTROL STUDIER September 2011 Søren Friis Institut for Epidemiologisk Kræftforskning Kræftens Bekæmpelse Case kontrol studie 3 typer Case-kohorte Nested case-kontrol Case-non case (klassisk
Præcision og effektivitet (efficiency)?
?") Case-kontrol studier PhD kursus i Epidemiologi Københavns Universitet 18 Sep 2012 Søren Friis Center for Kræftforskning, Kræftens Bekæmpelse Valg af design Problemstilling? Validitet? Præcision og effektivitet
Case-kontrol studier PhD kursus i Epidemiologi Københavns Universitet 18 Sep 2012 Søren Friis Center for Kræftforskning, Kræftens Bekæmpelse Valg af design Problemstilling? Validitet? Præcision og effektivitet
Postoperative komplikationer
 Løsninger til øvelser i kategoriske data, oktober 2008 1 Postoperative komplikationer Udgangspunktet for vurdering af den ny metode må være en nulhypotese om at der er samme komplikationshyppighed, 20%.
Løsninger til øvelser i kategoriske data, oktober 2008 1 Postoperative komplikationer Udgangspunktet for vurdering af den ny metode må være en nulhypotese om at der er samme komplikationshyppighed, 20%.
Morten Frydenberg Biostatistik version dato:
 Caerphilly studiet Design og Data Biostatistik uge 14 mandag Morten Frydenberg, Afdeling for Biostatistik Poisson regression En primær tidsakse og ikke stykkevise konstante rater Cox proportional hazard
Caerphilly studiet Design og Data Biostatistik uge 14 mandag Morten Frydenberg, Afdeling for Biostatistik Poisson regression En primær tidsakse og ikke stykkevise konstante rater Cox proportional hazard
Epidemiologiske associationsmål
 Epidemiologiske associationsmål Mads Kamper-Jørgensen, lektor, [email protected] Afdeling for Social Medicin, Institut for Folkesundhedsvidenskab It og sundhed l 16. april 2015 l Dias nummer 1 Sidste gang
Epidemiologiske associationsmål Mads Kamper-Jørgensen, lektor, [email protected] Afdeling for Social Medicin, Institut for Folkesundhedsvidenskab It og sundhed l 16. april 2015 l Dias nummer 1 Sidste gang
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab. Mantel-Haenszel analyser
 Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Mantel-Haenszel analyser Mantel-Haenszel analyser Sidst lærte vi om stratificerede analyser. I dag kigger vi på et specialtilfælde: både exposure
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Mantel-Haenszel analyser Mantel-Haenszel analyser Sidst lærte vi om stratificerede analyser. I dag kigger vi på et specialtilfælde: både exposure
Basal Statistik Kategoriske Data
 Basal Statistik Kategoriske Data 8 oktober 2013 E 2013 Basal Statistik - Kategoriske data Michael Gamborg Institut for sygdomsforebyggelse Københavns Universitetshospital [email protected]
Basal Statistik Kategoriske Data 8 oktober 2013 E 2013 Basal Statistik - Kategoriske data Michael Gamborg Institut for sygdomsforebyggelse Københavns Universitetshospital [email protected]
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006
 PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006 I dag: To stikprøver fra en normalfordeling, ikke-parametriske metoder og beregning af stikprøvestørrelse Eksempel: Fiskeolie
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006 I dag: To stikprøver fra en normalfordeling, ikke-parametriske metoder og beregning af stikprøvestørrelse Eksempel: Fiskeolie
1. februar Lungefunktions data fra tirsdags Gennemsnit l/min
 Epidemiologi og biostatistik Uge, torsdag 3. februar 005 Morten Frydenberg, Afdeling for Biostatistik. og hoste estimation sikkerhedsintervaller antagelr Normalfordelingen Prædiktion Statistisk test (ud
Epidemiologi og biostatistik Uge, torsdag 3. februar 005 Morten Frydenberg, Afdeling for Biostatistik. og hoste estimation sikkerhedsintervaller antagelr Normalfordelingen Prædiktion Statistisk test (ud
Statistik II Lektion 3. Logistisk Regression Kategoriske og Kontinuerte Forklarende Variable
 Statistik II Lektion 3 Logistisk Regression Kategoriske og Kontinuerte Forklarende Variable Setup: To binære variable X og Y. Statistisk model: Konsekvens: Logistisk regression: 2 binære var. e e X Y P
Statistik II Lektion 3 Logistisk Regression Kategoriske og Kontinuerte Forklarende Variable Setup: To binære variable X og Y. Statistisk model: Konsekvens: Logistisk regression: 2 binære var. e e X Y P
02402 Løsning til testquiz02402f (Test VI)
") 02402 Løsning til testquiz02402f (Test VI) Spørgsmål 4. En ejendomsmægler ønsker at undersøge om hans kunder får mindre end hvad de har forlangt, når de sælger deres bolig. Han har regisreret følgende:
02402 Løsning til testquiz02402f (Test VI) Spørgsmål 4. En ejendomsmægler ønsker at undersøge om hans kunder får mindre end hvad de har forlangt, når de sælger deres bolig. Han har regisreret følgende:
Det kunne godt se ud til at ikke-rygere er ældre. Spredningen ser ud til at være nogenlunde ens i de to grupper.
 1. Indlæs data. * HUSK at angive din egen placering af filen; data framing; infile '/home/sro00/mph2016/framing.txt' firstobs=2; input id sex age frw sbp sbp10 dbp chol cig chd yrschd death yrsdth cause;
1. Indlæs data. * HUSK at angive din egen placering af filen; data framing; infile '/home/sro00/mph2016/framing.txt' firstobs=2; input id sex age frw sbp sbp10 dbp chol cig chd yrschd death yrsdth cause;
Statikstik II 2. Lektion. Lidt sandsynlighedsregning Lidt mere om signifikanstest Logistisk regression
 Statikstik II 2. Lektion Lidt sandsynlighedsregning Lidt mere om signifikanstest Logistisk regression Sandsynlighedsregningsrepetition Antag at Svar kan være Ja og Nej. Sandsynligheden for at Svar Ja skrives
Statikstik II 2. Lektion Lidt sandsynlighedsregning Lidt mere om signifikanstest Logistisk regression Sandsynlighedsregningsrepetition Antag at Svar kan være Ja og Nej. Sandsynligheden for at Svar Ja skrives
Epidemiologi og Biostatistik Opgaver i Biostatistik Uge 10: 13. april
 Århus 8. april 2011 Morten Frydenberg Epidemiologi og Biostatistik Opgaver i Biostatistik Uge 10: 13. april Opgave 1 ( gruppe 1: sp 1-4, gruppe 5: sp 5-9 og gruppe 6: 10-14) I denne opgaveser vi på et
Århus 8. april 2011 Morten Frydenberg Epidemiologi og Biostatistik Opgaver i Biostatistik Uge 10: 13. april Opgave 1 ( gruppe 1: sp 1-4, gruppe 5: sp 5-9 og gruppe 6: 10-14) I denne opgaveser vi på et
Statistikøvelse Kandidatstudiet i Folkesundhedsvidenskab 28. September 2004
 Statistikøvelse Kandidatstudiet i Folkesundhedsvidenskab 28. September 2004 Formål med Øvelsen: Formålet med øvelsen er at analysere om risikoen for død er forbundet med to forskellige vacciner BCG (mod
Statistikøvelse Kandidatstudiet i Folkesundhedsvidenskab 28. September 2004 Formål med Øvelsen: Formålet med øvelsen er at analysere om risikoen for død er forbundet med to forskellige vacciner BCG (mod
Chi-i-anden Test. Repetition Goodness of Fit Uafhængighed i Kontingenstabeller
 Chi-i-anden Test Repetition Goodness of Fit Uafhængighed i Kontingenstabeller Chi-i-anden Test Chi-i-anden test omhandler data, der har form af antal eller frekvenser. Antag, at n observationer kan inddeles
Chi-i-anden Test Repetition Goodness of Fit Uafhængighed i Kontingenstabeller Chi-i-anden Test Chi-i-anden test omhandler data, der har form af antal eller frekvenser. Antag, at n observationer kan inddeles
Opgavebesvarelse, Basalkursus, uge 3
 Opgavebesvarelse, Basalkursus, uge 3 Opgave 1: Udskrivning af astma patienter (DGA s. 273) I en randomiseret undersøgelse foretaget af Storr et. al. (Lancet, i, 1987) sammenlignes effekten af en enkelt
Opgavebesvarelse, Basalkursus, uge 3 Opgave 1: Udskrivning af astma patienter (DGA s. 273) I en randomiseret undersøgelse foretaget af Storr et. al. (Lancet, i, 1987) sammenlignes effekten af en enkelt
Normalfordelingen. Statistik og Sandsynlighedsregning 2
 Normalfordelingen Statistik og Sandsynlighedsregning 2 Repetition og eksamen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige fejl på
Normalfordelingen Statistik og Sandsynlighedsregning 2 Repetition og eksamen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige fejl på
Program. Modelkontrol og prædiktion. Multiple sammenligninger. Opgave 5.2: fosforkoncentration
 Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: [email protected] Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: [email protected] Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
Morten Frydenberg Biostatistik version dato:
 Tye og Tye 2 fejl Statistisk styrke Biostatistik uge 2 mandag Morten Frydenberg, Afdeling for Biostatistik Styrkeovervejelser i lanlægning af et studie Logistisk regression Præterm fødsel, rygning, alder,
Tye og Tye 2 fejl Statistisk styrke Biostatistik uge 2 mandag Morten Frydenberg, Afdeling for Biostatistik Styrkeovervejelser i lanlægning af et studie Logistisk regression Præterm fødsel, rygning, alder,
Statistik kommandoer i Stata opdateret 16/3 2009 Erik Parner
 Statistik kommandoer i Stata opdateret 16/3 2009 Erik Parner Indledning... 1 Hukommelse... 1 Simple beskrivelser... 1 Data manipulation... 2 Estimation af proportioner... 2 Estimation af rater... 2 Estimation
Statistik kommandoer i Stata opdateret 16/3 2009 Erik Parner Indledning... 1 Hukommelse... 1 Simple beskrivelser... 1 Data manipulation... 2 Estimation af proportioner... 2 Estimation af rater... 2 Estimation
Dagens Temaer. Test for lineær regression. Test for lineær regression - via proc glm. k normalfordelte obs. rækker i proc glm. p. 1/??
 Dagens Temaer k normalfordelte obs. rækker i proc glm. Test for lineær regression Test for lineær regression - via proc glm p. 1/?? Proc glm Vi indlæser data i datasættet stress, der har to variable: areal,
Dagens Temaer k normalfordelte obs. rækker i proc glm. Test for lineær regression Test for lineær regression - via proc glm p. 1/?? Proc glm Vi indlæser data i datasættet stress, der har to variable: areal,
Morten Frydenberg 14. marts 2006
 Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik 1 RESUME: 2 2. gang: 2006 Institut for Biostatistik, Århus Universitet MPH 1. studieår Specialmodul 4 Cand. San. uddannelsen
Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik 1 RESUME: 2 2. gang: 2006 Institut for Biostatistik, Århus Universitet MPH 1. studieår Specialmodul 4 Cand. San. uddannelsen
Kvantitative Metoder 1 - Forår 2007. Dagens program
 Dagens program Hypoteser: kap: 10.1-10.2 Eksempler på Maximum likelihood analyser kap 9.10 Test Hypoteser kap. 10.1 Testprocedure kap 10.2 Teststørrelsen Testsandsynlighed 1 Estimationsmetoder Kvantitative
Dagens program Hypoteser: kap: 10.1-10.2 Eksempler på Maximum likelihood analyser kap 9.10 Test Hypoteser kap. 10.1 Testprocedure kap 10.2 Teststørrelsen Testsandsynlighed 1 Estimationsmetoder Kvantitative
Dag 6: Interaktion. Overlevelsesanalyse
 Dag 6: Interaktion. Overlevelsesanalyse How does CHD depend on gender and hypertension? Males: hypertension chd01 Females: Frequency Row Pct 0 1 Total ---------+--------+--------+ 0 352 95 447 78.75 21.25
Dag 6: Interaktion. Overlevelsesanalyse How does CHD depend on gender and hypertension? Males: hypertension chd01 Females: Frequency Row Pct 0 1 Total ---------+--------+--------+ 0 352 95 447 78.75 21.25
Resumé: En statistisk analyse resulterer ofte i : Et estimat θˆmed en tilhørende se
 Epidemiologi og biostatistik. Uge, torsdag 5. februar 00 Morten Frydenberg, Institut for Biostatistik. Type og type fejl Statistisk styrke Nogle speciale metoder: Normalfordelte data : t-test eksakte sikkerhedsintervaller
Epidemiologi og biostatistik. Uge, torsdag 5. februar 00 Morten Frydenberg, Institut for Biostatistik. Type og type fejl Statistisk styrke Nogle speciale metoder: Normalfordelte data : t-test eksakte sikkerhedsintervaller
Korrelation Pearson korrelationen
 -9- Eidemiologi og biostatistik. Forelæsning Uge, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Korrelation Kliniske målinger - Kliniske målinger og variationskilder - Estimation af størrelsen
-9- Eidemiologi og biostatistik. Forelæsning Uge, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Korrelation Kliniske målinger - Kliniske målinger og variationskilder - Estimation af størrelsen
Program. Logistisk regression. Eksempel: pesticider og møl. Odds og odds-ratios (igen)
") Faculty of Life Sciences Program Logistisk regression Claus Ekstrøm E-mail: [email protected] Odds og odds-ratios igen Logistisk regression Estimation og inferens Modelkontrol Slide 2 Statistisk Dataanalyse
Faculty of Life Sciences Program Logistisk regression Claus Ekstrøm E-mail: [email protected] Odds og odds-ratios igen Logistisk regression Estimation og inferens Modelkontrol Slide 2 Statistisk Dataanalyse
Overlevelse efter AMI. Hvilken betydning har følgende faktorer for risikoen for ikke at overleve: Køn og alder betragtes som confoundere.
 Overlevelse efter AMI Hvilken betydning har følgende faktorer for risikoen for ikke at overleve: Diabetes VF (Venticular fibrillation) WMI (Wall motion index) CHF (Cardiac Heart Failure) Køn og alder betragtes
Overlevelse efter AMI Hvilken betydning har følgende faktorer for risikoen for ikke at overleve: Diabetes VF (Venticular fibrillation) WMI (Wall motion index) CHF (Cardiac Heart Failure) Køn og alder betragtes
Statistik II 4. Lektion. Logistisk regression
 Statistik II 4. Lektion Logistisk regression Logistisk regression: Motivation Generelt setup: Dikotom(binær) afhængig variabel Kontinuerte og kategoriske forklarende variable (som i lineær reg.) Eksempel:
Statistik II 4. Lektion Logistisk regression Logistisk regression: Motivation Generelt setup: Dikotom(binær) afhængig variabel Kontinuerte og kategoriske forklarende variable (som i lineær reg.) Eksempel:
Analyse af binære responsvariable
 Analyse af binære responsvariable Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet 23. november 2012 Har mænd lettere ved at komme ind på Berkeley? UC Berkeley
Analyse af binære responsvariable Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet 23. november 2012 Har mænd lettere ved at komme ind på Berkeley? UC Berkeley
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab. Stratificerede analyser
 Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Stratificerede analyser Dødsstraf-eksempel Betyder morderens farve noget for risikoen for dødsstraf? 1 Dødsstraf-eksempel: data Variable: Dødsstraf
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Stratificerede analyser Dødsstraf-eksempel Betyder morderens farve noget for risikoen for dødsstraf? 1 Dødsstraf-eksempel: data Variable: Dødsstraf
Konfidensinterval for µ (σ kendt)
") Program 1. Repetition: konfidens-intervaller. 2. Hypotese test 3. Type I og type II fejl, p-værdi 4. En og to-sidede tests 5. Test for middelværdi (kendt varians) 6. Test for middelværdi (ukendt varians)
Program 1. Repetition: konfidens-intervaller. 2. Hypotese test 3. Type I og type II fejl, p-værdi 4. En og to-sidede tests 5. Test for middelværdi (kendt varians) 6. Test for middelværdi (ukendt varians)
Logistisk regression
 Logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Kursushjemmeside: www.biostat.ku.dk/~sr/forskningsaar/regression2012/
Logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Kursushjemmeside: www.biostat.ku.dk/~sr/forskningsaar/regression2012/
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab. Eksamensopgave E05. Socialklasse og kronisk sygdom
 Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Eksamensopgave E05 Socialklasse og kronisk sygdom Data: Tværsnitsundersøgelse fra 1986 Datamaterialet indeholder: Køn, alder, Højest opnåede
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Eksamensopgave E05 Socialklasse og kronisk sygdom Data: Tværsnitsundersøgelse fra 1986 Datamaterialet indeholder: Køn, alder, Højest opnåede
Epidemiologi og Biostatistik Opgaver i Biostatistik Uge 4: 2. marts
 Århus 27. februar 2011 Morten Frydenberg Epidemiologi og Biostatistik Opgaver i Biostatistik Uge 4: 2. marts Epibasic er nu opdateret til version 2.02 (obs. der er ikke ændret ved arket C-risk) Start med
Århus 27. februar 2011 Morten Frydenberg Epidemiologi og Biostatistik Opgaver i Biostatistik Uge 4: 2. marts Epibasic er nu opdateret til version 2.02 (obs. der er ikke ændret ved arket C-risk) Start med
Anvendt Statistik Lektion 6. Kontingenstabeller χ 2 -test [ki-i-anden-test]
![Anvendt Statistik Lektion 6. Kontingenstabeller χ 2 -test [ki-i-anden-test]](/thumbs/30/14715329.jpg "Anvendt Statistik Lektion 6. Kontingenstabeller χ 2 -test [ki-i-anden-test]") Anvendt Statistik Lektion 6 Kontingenstabeller χ 2 -test [ki-i-anden-test] 1 Kontingenstabel Formål: Illustrere/finde sammenhænge mellem to kategoriske variable Opbygning: En celle for hver kombination
Anvendt Statistik Lektion 6 Kontingenstabeller χ 2 -test [ki-i-anden-test] 1 Kontingenstabel Formål: Illustrere/finde sammenhænge mellem to kategoriske variable Opbygning: En celle for hver kombination
Epidemiologiske associationsmål
 Epidemiologiske associationsmål Mads Kamper-Jørgensen, lektor, [email protected] Afdeling for Social Medicin, Institut for Folkesundhedsvidenskab It og sundhed l 21. april 2016 l Dias nummer 1 Sidste gang
Epidemiologiske associationsmål Mads Kamper-Jørgensen, lektor, [email protected] Afdeling for Social Medicin, Institut for Folkesundhedsvidenskab It og sundhed l 21. april 2016 l Dias nummer 1 Sidste gang
c) For, er, hvorefter. Forklar.
 For, er, hvorefter. Forklar.") 1 af 13 MATEMATIK B hhx Udskriv siden FACITLISTE TIL KAPITEL 7 ØVELSER ØVELSE 1 c) ØVELSE 2 og. Forklar. c) For, er, hvorefter. Forklar. ØVELSE 3 c) ØVELSE 4 90 % konfidensinterval: 99 % konfidensinterval:
1 af 13 MATEMATIK B hhx Udskriv siden FACITLISTE TIL KAPITEL 7 ØVELSER ØVELSE 1 c) ØVELSE 2 og. Forklar. c) For, er, hvorefter. Forklar. ØVELSE 3 c) ØVELSE 4 90 % konfidensinterval: 99 % konfidensinterval:
Statistik Lektion 17 Multipel Lineær Regression
 Statistik Lektion 7 Multipel Lineær Regression Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test Multipel lineær regression x,x,,x
Statistik Lektion 7 Multipel Lineær Regression Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test Multipel lineær regression x,x,,x
Epidemiologi. Hvad er det? Øjvind Lidegaard og Ulrik Kesmodel
 Epidemiologi. Hvad er det? Øjvind Lidegaard og Ulrik Kesmodel Rigshospitalet Århus Sygehus Epidemiologi. Hvad er det? Definition Læren om sygdommes udbredelse og årsager Indhold To hovedopgaver: Deskriptiv
Epidemiologi. Hvad er det? Øjvind Lidegaard og Ulrik Kesmodel Rigshospitalet Århus Sygehus Epidemiologi. Hvad er det? Definition Læren om sygdommes udbredelse og årsager Indhold To hovedopgaver: Deskriptiv
Regneregler for middelværdier M(X+Y) = M X +M Y. Spredning varians og standardafvigelse. 1 n VAR(X) Y = a + bx VAR(Y) = VAR(a+bX) = b²var(x)
 = M X +M Y. Spredning varians og standardafvigelse. 1 n VAR(X) Y = a + bx VAR(Y) = VAR(a+bX) = b²var(x)") Formelsamlingen 1 Regneregler for middelværdier M(a + bx) a + bm X M(X+Y) M X +M Y Spredning varians og standardafvigelse VAR(X) 1 n n i1 ( X i - M x ) 2 Y a + bx VAR(Y) VAR(a+bX) b²var(x) 2 Kovariansen
Formelsamlingen 1 Regneregler for middelværdier M(a + bx) a + bm X M(X+Y) M X +M Y Spredning varians og standardafvigelse VAR(X) 1 n n i1 ( X i - M x ) 2 Y a + bx VAR(Y) VAR(a+bX) b²var(x) 2 Kovariansen
Eks. 1: Kontinuert variabel som i princippet kan måles med uendelig præcision. tid, vægt,
 Statistik noter Indhold Datatyper... 2 Middelværdi og standardafvigelse... 2 Normalfordelingen og en stikprøve... 2 prædiktionsinteval... 3 Beregne andel mellem 2 værdier, eller over og unden en værdi
Statistik noter Indhold Datatyper... 2 Middelværdi og standardafvigelse... 2 Normalfordelingen og en stikprøve... 2 prædiktionsinteval... 3 Beregne andel mellem 2 værdier, eller over og unden en værdi
Epidemiologi og biostatistik. Uge 3, torsdag. Erik Parner, Institut for Biostatistik. Regressionsanalyse
 Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Institut for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression Regressionsanalyse Regressionsanalyser
Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Institut for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression Regressionsanalyse Regressionsanalyser
Kursus 02402 Introduktion til Statistik. Forelæsning 7: Kapitel 7 og 8: Statistik for to gennemsnit, (7.7-7.8,8.1-8.5) Per Bruun Brockhoff
 Per Bruun Brockhoff") Kursus 02402 Introduktion til Statistik Forelæsning 7: Kapitel 7 og 8: Statistik for to gennemsnit, (7.7-7.8,8.1-8.5) Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks
Kursus 02402 Introduktion til Statistik Forelæsning 7: Kapitel 7 og 8: Statistik for to gennemsnit, (7.7-7.8,8.1-8.5) Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks
Løsning til øvelsesopgaver dag 4 spg 5-9
 Løsning til øvelsesopgaver dag 4 spg 5-9 5: Den multiple model Vi tilføjer nu yderligere to variable til vores model : Køn og kolesterol SBP = a + b*age + c*chol + d*mand hvor mand er 1 for mænd, 0 for
Løsning til øvelsesopgaver dag 4 spg 5-9 5: Den multiple model Vi tilføjer nu yderligere to variable til vores model : Køn og kolesterol SBP = a + b*age + c*chol + d*mand hvor mand er 1 for mænd, 0 for
Eksamen ved. Københavns Universitet i. Kvantitative forskningsmetoder. Det Samfundsvidenskabelige Fakultet
 Eksamen ved Københavns Universitet i Kvantitative forskningsmetoder Det Samfundsvidenskabelige Fakultet 14. december 2011 Eksamensnummer: 5 14. december 2011 Side 1 af 6 1) Af boxplottet kan man aflæse,
Eksamen ved Københavns Universitet i Kvantitative forskningsmetoder Det Samfundsvidenskabelige Fakultet 14. december 2011 Eksamensnummer: 5 14. december 2011 Side 1 af 6 1) Af boxplottet kan man aflæse,
Ved undervisningen i epidemiologi/statistik den 8. og 10. november 2011 vil vi lægge hovedvægten på en fælles diskussion af følgende fire artikler:
 Kære MPH-studerende Ved undervisningen i epidemiologi/statistik den 8. og 10. november 2011 vil vi lægge hovedvægten på en fælles diskussion af følgende fire artikler: 1. E.A. Mitchell et al. Ethnic differences
Kære MPH-studerende Ved undervisningen i epidemiologi/statistik den 8. og 10. november 2011 vil vi lægge hovedvægten på en fælles diskussion af følgende fire artikler: 1. E.A. Mitchell et al. Ethnic differences
Opgavebesvarelse, Basalkursus, uge 3
 Opgavebesvarelse, Basalkursus, uge 3 Opgave 1: Udskrivning af astma patienter (DGA s. 273) I en randomiseret undersøgelse foretaget af Storr et. al. (Lancet, i, 1987) sammenlignes effekten af en enkelt
Opgavebesvarelse, Basalkursus, uge 3 Opgave 1: Udskrivning af astma patienter (DGA s. 273) I en randomiseret undersøgelse foretaget af Storr et. al. (Lancet, i, 1987) sammenlignes effekten af en enkelt
Logistisk Regression - fortsat
 Logistisk Regression - fortsat Likelihood Ratio test Generel hypotese test Modelanalyse Indtil nu har vi set på to slags modeller: 1) Generelle Lineære Modeller Kvantitav afhængig variabel. Kvantitative
Logistisk Regression - fortsat Likelihood Ratio test Generel hypotese test Modelanalyse Indtil nu har vi set på to slags modeller: 1) Generelle Lineære Modeller Kvantitav afhængig variabel. Kvantitative
ORDINÆR EKSAMEN I EPIDEMIOLOGISKE METODER IT & Sundhed, 2. semester
 D E T S U N D H E D S V I D E N S K A B E L I G E F A K U L T E T K Ø B E N H A V N S U N I V E R S I T E T B l e g d a m s v e j 3 B 2 2 0 0 K ø b e n h a v n N ORDINÆR EKSAMEN I EPIDEMIOLOGISKE METODER
D E T S U N D H E D S V I D E N S K A B E L I G E F A K U L T E T K Ø B E N H A V N S U N I V E R S I T E T B l e g d a m s v e j 3 B 2 2 0 0 K ø b e n h a v n N ORDINÆR EKSAMEN I EPIDEMIOLOGISKE METODER
12. september Epidemiologi og biostatistik. Forelæsning 4 Uge 3, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Regressionsanalyse
 . september 5 Epidemiologi og biostatistik. Forelæsning Uge, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression
. september 5 Epidemiologi og biostatistik. Forelæsning Uge, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression
Sammenhængsanalyser. Et eksempel: Sammenhæng mellem rygevaner som 45-årig og selvvurderet helbred som 51 blandt mænd fra Københavns amt.
 Sammenhængsanalyser Et eksempel: Sammenhæng mellem rygevaner som 45-årig og selvvurderet helbred som 51 blandt mænd fra Københavns amt. rygevaner som 45 årig * helbred som 51 årig Crosstabulation rygevaner
Sammenhængsanalyser Et eksempel: Sammenhæng mellem rygevaner som 45-årig og selvvurderet helbred som 51 blandt mænd fra Københavns amt. rygevaner som 45 årig * helbred som 51 årig Crosstabulation rygevaner
SKRIFTLIG EKSAMEN I BIOSTATISTIK OG EPIDEMIOLOGI Cand.Scient.San, 2. semester 20. februar 2015 (3 timer)
") D E T S U N D H E D S V I D E N S K A B E L I G E F A K U L T E T K Ø B E N H A V N S U N I V E R S I T E T B l e g d a m s v e j 3 B 2 2 0 0 K ø b e n h a v n N SKRIFTLIG EKSAMEN I BIOSTATISTIK OG EPIDEMIOLOGI
D E T S U N D H E D S V I D E N S K A B E L I G E F A K U L T E T K Ø B E N H A V N S U N I V E R S I T E T B l e g d a m s v e j 3 B 2 2 0 0 K ø b e n h a v n N SKRIFTLIG EKSAMEN I BIOSTATISTIK OG EPIDEMIOLOGI
Epidemiologi og biostatistik. Uge 3, torsdag. Erik Parner, Afdeling for Biostatistik. Eksempel: Systolisk blodtryk
 Eksempel: Systolisk blodtryk Udgangspunkt: Vi ønsker at prædiktere det systoliske blodtryk hos en gruppe af personer. Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Afdeling for Biostatistik.
Eksempel: Systolisk blodtryk Udgangspunkt: Vi ønsker at prædiktere det systoliske blodtryk hos en gruppe af personer. Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Afdeling for Biostatistik.
6. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag)
") Institut for Epidemiologi og Socialmedicin Institut for Biostatistik. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag) Opgave 1 Læs afsnit.1 i An Introduction to Medical Statistics, specielt
Institut for Epidemiologi og Socialmedicin Institut for Biostatistik. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag) Opgave 1 Læs afsnit.1 i An Introduction to Medical Statistics, specielt
Lineær og logistisk regression
 Faculty of Health Sciences Lineær og logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Dagens program Lineær regression
Faculty of Health Sciences Lineær og logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Dagens program Lineær regression
Eksempel: PEFR. Epidemiologi og biostatistik. Uge 1, tirsdag. Erik Parner, Institut for Biostatistik.
 Epidemiologi og biostatistik. Uge, tirsdag. Erik Parner, Institut for Biostatistik. Generelt om statistik Dataanalysen - Deskriptiv statistik - Statistisk inferens Sammenligning af to grupper med kontinuerte
Epidemiologi og biostatistik. Uge, tirsdag. Erik Parner, Institut for Biostatistik. Generelt om statistik Dataanalysen - Deskriptiv statistik - Statistisk inferens Sammenligning af to grupper med kontinuerte
Reminder: Hypotesetest for én parameter. Økonometri: Lektion 4. F -test Justeret R 2 Aymptotiske resultater. En god model
 Reminder: Hypotesetest for én parameter Antag vi har model Økonometri: Lektion 4 F -test Justeret R 2 Aymptotiske resultater y = β 0 + β 1 x 2 + β 2 x 2 + + β k x k + u. Vi ønsker at teste hypotesen H
Reminder: Hypotesetest for én parameter Antag vi har model Økonometri: Lektion 4 F -test Justeret R 2 Aymptotiske resultater y = β 0 + β 1 x 2 + β 2 x 2 + + β k x k + u. Vi ønsker at teste hypotesen H
Forelæsning 6: Kapitel 7: Hypotesetest for gennemsnit (one-sample setup). 7.4-7.6
. 7.4-7.6") Kursus 02402 Introduktion til Statistik Forelæsning 6: Kapitel 7: Hypotesetest for gennemsnit (one-sample setup). 7.4-7.6 Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220
Kursus 02402 Introduktion til Statistik Forelæsning 6: Kapitel 7: Hypotesetest for gennemsnit (one-sample setup). 7.4-7.6 Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220
Note til styrkefunktionen
 Teoretisk Statistik. årsprøve Note til styrkefunktionen Først er det vigtigt at gøre sig klart, at når man laver statistiske test, så kan man begå to forskellige typer af fejl: Type fejl: At forkaste H
Teoretisk Statistik. årsprøve Note til styrkefunktionen Først er det vigtigt at gøre sig klart, at når man laver statistiske test, så kan man begå to forskellige typer af fejl: Type fejl: At forkaste H
Faculty of Health Sciences. Logistisk regression: Kvantitative forklarende variable
 Faculty of Health Sciences Logistisk regression: Kvantitative forklarende variable Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Sammenhæng
Faculty of Health Sciences Logistisk regression: Kvantitative forklarende variable Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Sammenhæng
Basal statistik. 30. januar 2007
 Basal statistik 30. januar 2007 Deskriptiv statistik Typer af data Tabeller Grafik Summary statistics Lene Theil Skovgaard, Biostatistisk Afdeling Institut for Folkesundhedsvidenskab, Københavns Universitet
Basal statistik 30. januar 2007 Deskriptiv statistik Typer af data Tabeller Grafik Summary statistics Lene Theil Skovgaard, Biostatistisk Afdeling Institut for Folkesundhedsvidenskab, Københavns Universitet
MPH Introduktionsmodul: Epidemiologi og Biostatistik 23.09.2003
 Opgave 1 (mandag) Figuren nedenfor viser tilfælde af mononukleose i en lille population bestående af 20 personer. Start og slut på en sygdoms periode er angivet med. 20 15 person number 10 5 1 July 1970
Opgave 1 (mandag) Figuren nedenfor viser tilfælde af mononukleose i en lille population bestående af 20 personer. Start og slut på en sygdoms periode er angivet med. 20 15 person number 10 5 1 July 1970
Studiedesign. Rikke Guldberg Ulrik Schiøler Kesmodel Øjvind Lidegaard
 Studiedesign Rikke Guldberg Ulrik Schiøler Kesmodel Øjvind Lidegaard Studiedesign Økologiske studier Tværsnitsstudier Case-kontrolstudier Kohortestudier Randomiserede studier Hvorfor er det vigtigt at
Studiedesign Rikke Guldberg Ulrik Schiøler Kesmodel Øjvind Lidegaard Studiedesign Økologiske studier Tværsnitsstudier Case-kontrolstudier Kohortestudier Randomiserede studier Hvorfor er det vigtigt at
Opsamling Modeltyper: Tabelanalyse Logistisk regression Generaliserede lineære modeller Log-lineære modeller
 Opsamling Modeltyper: Tabelanalyse Logistisk regression Binær respons og kategorisk eller kontinuerte forklarende variable. Generaliserede lineære modeller Normalfordelt respons og kategoriske forklarende
Opsamling Modeltyper: Tabelanalyse Logistisk regression Binær respons og kategorisk eller kontinuerte forklarende variable. Generaliserede lineære modeller Normalfordelt respons og kategoriske forklarende
Logistisk Regression. Repetition Fortolkning af odds Test i logistisk regression
 Logistisk Regression Repetition Fortolkning af odds Test i logistisk regression Logistisk Regression: Definitioner For en binær (0/) variabel Y antager vi P(Y)p P(Y0)-p Eksempel: Bil til arbejde vs alder
Logistisk Regression Repetition Fortolkning af odds Test i logistisk regression Logistisk Regression: Definitioner For en binær (0/) variabel Y antager vi P(Y)p P(Y0)-p Eksempel: Bil til arbejde vs alder
6. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag)
") Institut for Folkesundhed Afdeling for Biostatistik Afdeling for Epidemiologi. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag) Opgave 1 Udgangspunktet for de følgende spørgsmål er artiklen:
Institut for Folkesundhed Afdeling for Biostatistik Afdeling for Epidemiologi. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag) Opgave 1 Udgangspunktet for de følgende spørgsmål er artiklen:
Program. 1. Repetition: konfidens-intervaller. 2. Hypotese test, type I og type II fejl, signifikansniveau, styrke, en- og to-sidede test.
 Program 1. Repetition: konfidens-intervaller. 2. Hypotese test, type I og type II fejl, signifikansniveau, styrke, en- og to-sidede test. 1/19 Konfidensinterval for µ (σ kendt) Estimat ˆµ = X bedste bud
Program 1. Repetition: konfidens-intervaller. 2. Hypotese test, type I og type II fejl, signifikansniveau, styrke, en- og to-sidede test. 1/19 Konfidensinterval for µ (σ kendt) Estimat ˆµ = X bedste bud
Studiedesigns: Case-kontrolundersøgelser
 Studiedesigns: Case-kontrolundersøgelser Mads Kamper-Jørgensen, lektor, [email protected] Afdeling for Social Medicin, Institut for Folkesundhedsvidenskab It og sundhed l 12. maj 2016 l Dias nummer 1 Sidste
Studiedesigns: Case-kontrolundersøgelser Mads Kamper-Jørgensen, lektor, [email protected] Afdeling for Social Medicin, Institut for Folkesundhedsvidenskab It og sundhed l 12. maj 2016 l Dias nummer 1 Sidste
OR stiger eksponentielt med forskellen i BMI komplicet model svær at forstå og analysere simpel model
 Epidemiologi og biostatistik. Uge 5, torsdag. marts 1 Morten Frydenberg, Institut for Biostatistik. 1 Analyse af overlevelsesdata (ventetidsdata) Censurering (højre + andet) Kaplan-Meyer kurver Det statistiske
Epidemiologi og biostatistik. Uge 5, torsdag. marts 1 Morten Frydenberg, Institut for Biostatistik. 1 Analyse af overlevelsesdata (ventetidsdata) Censurering (højre + andet) Kaplan-Meyer kurver Det statistiske
Statistik Lektion 20 Ikke-parametriske metoder. Repetition Kruskal-Wallis Test Friedman Test Chi-i-anden Test
 Statistik Lektion 0 Ikkeparametriske metoder Repetition KruskalWallis Test Friedman Test Chiianden Test Run Test Er sekvensen opstået tilfældigt? PPPKKKPPPKKKPPKKKPPP Et run er en sekvens af ens elementer,
Statistik Lektion 0 Ikkeparametriske metoder Repetition KruskalWallis Test Friedman Test Chiianden Test Run Test Er sekvensen opstået tilfældigt? PPPKKKPPPKKKPPKKKPPP Et run er en sekvens af ens elementer,
Statistik i basketball
 En note til opgaveskrivning [email protected] 4. marts 200 Indledning I Falcon og andre klubber er der en del gymnasieelever, der på et tidspunkt i løbet af deres gymnasietid skal skrive en større
En note til opgaveskrivning [email protected] 4. marts 200 Indledning I Falcon og andre klubber er der en del gymnasieelever, der på et tidspunkt i løbet af deres gymnasietid skal skrive en større
Man indlæser en såkaldt frequency-table i SAS ved følgende kommandoer:
 1 IHD-Lexis 1.1 Spørgsmål 1 Man indlæser en såkaldt frequency-table i SAS ved følgende kommandoer: data ihdfreq; input eksp alder pyrs cases; lpyrs=log(pyrs); cards; 0 2 346.87 2 0 1 979.34 12 0 0 699.14
1 IHD-Lexis 1.1 Spørgsmål 1 Man indlæser en såkaldt frequency-table i SAS ved følgende kommandoer: data ihdfreq; input eksp alder pyrs cases; lpyrs=log(pyrs); cards; 0 2 346.87 2 0 1 979.34 12 0 0 699.14
Lægevidenskabelig Embedseksamen, 6. semester Forår 2009 Epidemiologi og Biostatistik Rettevejledning
 Lægevidenskabelig Embedseksamen, 6. semester Forår 2009 Epidemiologi og Biostatistik Rettevejledning Opgave 1. Angiv studiets formål, design og hvilke associationsmål, der bruges. Beskriv hovedresultaterne
Lægevidenskabelig Embedseksamen, 6. semester Forår 2009 Epidemiologi og Biostatistik Rettevejledning Opgave 1. Angiv studiets formål, design og hvilke associationsmål, der bruges. Beskriv hovedresultaterne
Multipel Linear Regression. Repetition Partiel F-test Modelsøgning Logistisk Regression
 Multipel Linear Regression Repetition Partiel F-test Modelsøgning Logistisk Regression Test for en eller alle parametre I jagten på en god statistisk model har vi set på følgende to hypoteser og tilhørende
Multipel Linear Regression Repetition Partiel F-test Modelsøgning Logistisk Regression Test for en eller alle parametre I jagten på en god statistisk model har vi set på følgende to hypoteser og tilhørende
MPH specialmodul i biostatistik og epidemiologi SAS-øvelser vedr. case-control studie af malignt melanom.
 MPH specialmodul i biostatistik og epidemiologi SAS-øvelser vedr. case-control studie af malignt melanom. For at I skal kunne regne på tallene fra undersøgelsen har vi taget en delmængde af variablene
MPH specialmodul i biostatistik og epidemiologi SAS-øvelser vedr. case-control studie af malignt melanom. For at I skal kunne regne på tallene fra undersøgelsen har vi taget en delmængde af variablene
Multipel Lineær Regression. Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test
 Multipel Lineær Regression Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test Multipel lineær regression x,x,,x k uafhængige variable
Multipel Lineær Regression Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test Multipel lineær regression x,x,,x k uafhængige variable
Maple 11 - Chi-i-anden test
 Maple 11 - Chi-i-anden test Erik Vestergaard 2014 Indledning I dette dokument skal vi se hvordan Maple kan bruges til at løse opgaver indenfor χ 2 tests: χ 2 - Goodness of fit test samt χ 2 -uafhængighedstest.
Maple 11 - Chi-i-anden test Erik Vestergaard 2014 Indledning I dette dokument skal vi se hvordan Maple kan bruges til at løse opgaver indenfor χ 2 tests: χ 2 - Goodness of fit test samt χ 2 -uafhængighedstest.