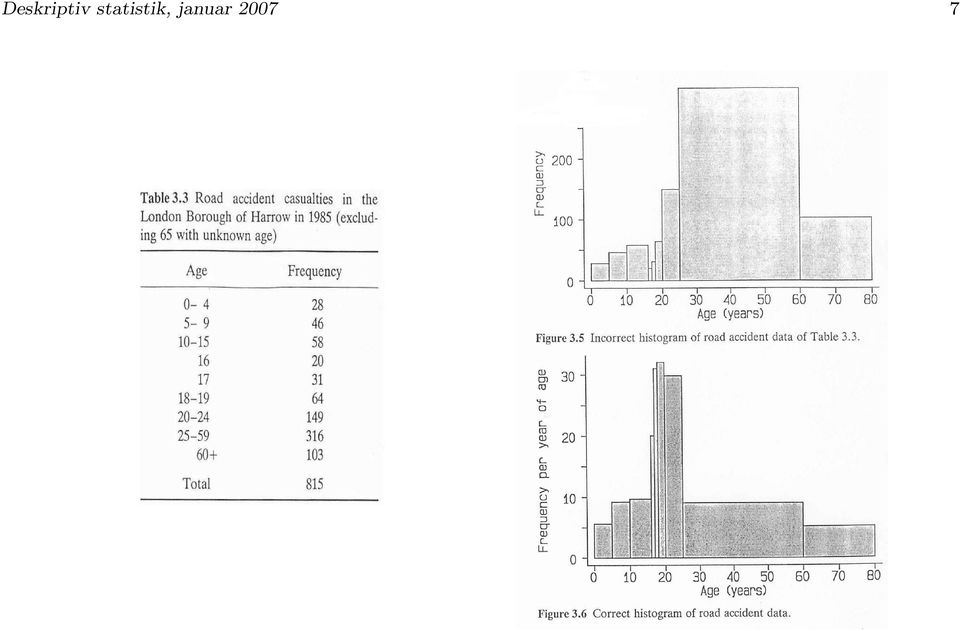
Basal statistik. 30. januar 2007
|
|
|
- Nicklas Ludvigsen
- 10 år siden
- Visninger:
Transkript
1 Basal statistik 30. januar 2007

2 Deskriptiv statistik Typer af data Tabeller Grafik Summary statistics

3 Lene Theil Skovgaard, Biostatistisk Afdeling Institut for Folkesundhedsvidenskab, Københavns Universitet

4 Deskriptiv statistik, januar Eksempel på kvantitative data

5 Deskriptiv statistik, januar Statistik Handler om ud fra tal, data at udtale sig om aspekter af virkeligheden (sundhedsvidenskabelige problemstillinger) (Ikke officiel statistik, statistikproduktion) Ud fra stikprøve: 1. Deskriptiv statistik: beskrive niveau og variation i population 2. Statistisk inferens: drage konklusioner om ukendte størrelser, parametre, knyttet til populationen, f.eks. forskel i niveau for mænd og kvinder eller stigning i niveau pr. år.

6 Deskriptiv statistik, januar Nøgleord Datareduktion Datapræsentation Statistiske modeller Værktøjer matematik, sandsynlighedsregning edb grafik og sund fornuft!

7 Deskriptiv statistik, januar Scatter plot af PImax mod alder

8 Deskriptiv statistik, januar Histogram SAS ANALYST: Graph/Histogram pimax i Analysis

9 Deskriptiv statistik, januar Beskrivelse af kvantitative variable Histogram Location, centrum Gennemsnit: ȳ = 1 n (y y n ) Median: midterste observation, efter størrelsesorden (50% fraktil) Variation Varians: s 2 = 1 n 1 Σ(y i ȳ) 2 spredning = standardafvigelse = varians Fraktiler (kumuleret fordelingsfunktion) Fraktildiagram Boxplot
")
10 Deskriptiv statistik, januar
11 Deskriptiv statistik, januar Gennemsnit Eksempel: Indlæggelsestider: 5,5,5,7,10,16,106 dage Gennemsnit: 154/7=22 dage. Repræsentativt for hvad?? På den anden side, hvis omkostninger er kan opfattes som ligevægtspunkt påvirkes kraftigt af yderlige observationer proportionale med indlæggelsestiden, så er det måske gennemsnittet, der er interessant for hospitalsledelsen.

12 Deskriptiv statistik, januar Data i rækkefølge: Fraktiler for PImax-eksempel Median: Midterste observation, 50%-fraktil: 95 Kvartiler (25% og 75% fraktiler): 75, 110.

13 Deskriptiv statistik, januar Should we scare the opposition by announcing our mean height, or lull them by announcing our median height?

14 Deskriptiv statistik, januar Håndregning Beregning af gennemsnit: ȳ = 1 n i y i her: ( )/25 = 92.6 Beregning af varians: s 2 = 1 n 1 (y i ȳ) 2 her: (( ) 2 + ( ) ( ) 2 )/24 = Beregning af spredning: her: = 24.9 i s = s 2
 2 + (85 92.6) 2 + + (95 92.6) 2 )/24 = 621.")
15 Deskriptiv statistik, januar Summary statistics i SAS Statistics/Descriptive/Summary Statistics pimax i Analysis i Statistics afkrydses: Mean, Standard Deviation, Minimum, Maximum, Median og Number of Observations samt Standard error The MEANS Procedure Analysis Variable : pimax Mean Std Dev Minimum Maximum Median N Std Error

16 Deskriptiv statistik, januar Fortolkning af spredningen, s Hovedparten af observationerne ligger inden for ȳ ± ca.2 s dvs. sandsynligheden for at en tilfældig udtrukket person fra populationen har en værdi i dette interval er stor... For PImax finder vi 92.6 ± = (42.8, 142.4) Hvis data er normalfordelt, vil dette interval indeholde ca. 95% af fremtidige observationer. Hvis ikke... For at benytte ovenstående, skal der i hvert fald helst være rimelig symmetri...

17 Deskriptiv statistik, januar For kvantitative variable har hver enkelt værdi sandsynlighed 0 for at indtræffe (fordi der i princippet er mange mulige udfald). Vi taler i stedet om sandsynlighedstætheder, således at sandsynligheden for et interval udregnes som arealet under kurven. Område, der dækker de centrale 95% af observationerne, må gå fra % fraktilen til % fraktilen, her... Men hvordan finder man % af kun 25 observationer??

18 Deskriptiv statistik, januar Normalfordelingstætheder benævnes ofte N(µ,σ 2 ) middelværdi = mean, ofte benævnt µ, α el.lign. spredning, ofte benævnt σ

19 Deskriptiv statistik, januar Histogram med overlejret normalfordeling SAS ANALYST: Graph/Histogram pimax i Analysis klik Fit og afkryds Normal Parameters

20 Deskriptiv statistik, januar Skæve fordelinger Histogram of IgM Frequency gennemsnit ȳ 0.80g/l spredning s=sd 0.47g/l (ȳ+2s, ȳ+2s) = ( 0.14g/l, 1.74g/l) Urimeligt interval, indeholder f.eks. negative værdier IgM
 Urimeligt interval, indeholder f.eks.")
21 Deskriptiv statistik, januar Fraktiler for IgM-data Kumulativ fordeling: Quantile Estimate 100% Max % % % % Q % Median % Q % 0.4 5% 0.3 1% 0.1 0% Min 0.1 Obs P_2_5 P_5 P_95 P_97_ Intervallet (0.2, 2.0) synes mere repræsentativt
22 Deskriptiv statistik, januar Hvordan kan vi se, om normalfordelingen er en god beskrivelse? Simulation af 50 observationer fra samme normalfordeling, gentaget 16 gange: Nogle af dem ser ikke ret normalfordelte ud! Ganske store afvigelser kan tolereres i visse sammenhænge, specielt når de ikke er for systematiske.
23 Deskriptiv statistik, januar Test af normalitet for PImax blandt meget andet output fra Statistics/Descriptive/Distributions når der afkrydses i Fit/Normal Parameters: The UNIVARIATE Procedure Fitted Distribution for pimax Parameters for Normal Distribution Quantiles for Normal Distribution Test Parameter Symbol Estimate Mean Mu 92.6 Std Dev Sigma Goodness-of-Fit Tests for Normal Distribution ---Statistic p Value----- Kolmogorov-Smirnov D Pr > D >0.150 Cramer-von Mises W-Sq Pr > W-Sq >0.250 Anderson-Darling A-Sq Pr > A-Sq >0.250 Percent Quantile Observed Estimated
24 Deskriptiv statistik, januar Fraktildiagram Graphs/Probability Plot: Hvis data er normalfordelt, skal fraktildiagrammet ligne en ret linie: De observerede fraktiler skal passe med de teoretiske (pånær en skala)
25 Deskriptiv statistik, januar Fitted Distribution for igm Test af normalitet for IgM Parameters for Normal Distribution Parameter Symbol Estimate Mean Mu Std Dev Sigma Test Goodness-of-Fit Tests for Normal Distribution ---Statistic p Value----- Kolmogorov-Smirnov D Pr > D <0.010 Cramer-von Mises W-Sq Pr > W-Sq <0.005 Anderson-Darling A-Sq Pr > A-Sq <0.005 Quantiles for Normal Distribution Quantile Percent Observed Estimated
26 Deskriptiv statistik, januar Fraktildiagram for IgM ses at passe meget dårligt med en ret linie
27 Deskriptiv statistik, januar Normalområde: Område, der omslutter 95% af normale observationer: nedre grænse: % fraktil øvre grænse: % fraktil Hvis fordelingen kan beskrives ved en normalfordeling N(µ,σ 2 ), kan disse fraktiler direkte udtrykkes som % fraktil: µ 1.96σ ȳ 1.96s % fraktil: µ σ ȳ s og normalområdet udregnes derfor som ȳ ± ca.2 s = (ȳ ca.2 s, ȳ + ca.2 s)
28 Deskriptiv statistik, januar Hvorfor benyttes normalfordelingen så ofte? Det er ofte en rimelig approksimation Evt. efter transformation med logaritme, kvadratrod, invers,... Central grænseværdisætning: Summen af et stort antal variable kommer efterhånden til at ligne en normalfordeling (sum af normalfordelinger er igen en normalfordeling). Rimelig let at arbejde med, fordi standard programmel er udviklet for normalfordelingen.
29 Deskriptiv statistik, januar
30 Deskriptiv statistik, januar Transformation med logaritme (log 10 ) gennemsnit spredning Antilog: = = 0.63 Antilog: = = 0.32 Antilog: = 2.08 Frequency Histogram of log10(igm) log10(igm) Bedre grænser: (0.23, 2.08)
31 Deskriptiv statistik, januar Central grænseværdisætning. Spredning på gennemsnit: SEM, standard error of the mean Fordeling af gennemsnit, ȳ??
32 Deskriptiv statistik, januar Hvordan kan vi sige noget om fordelingen af ȳ? Jackknife: Udelad en observation ad gangen Udregn gennemsnit af resten, z i = ȳ ( i) = nȳ y i n 1 Fordeling af disse leave-one-out gennemsnit...?? Bootstrap: Resampling med tilbagelæggelse Udregn gennemsnit af hvert nyt sample Fordeling af Bootstrap gennemsnit...!! Ved at benytte en fordelingsantagelse for selve y erne Hvis y i erne er normalfordelte, vil ȳ også være det, og spredningen i denne fordeling vil være SEM = SD n
33 Deskriptiv statistik, januar Bootstrap distribution of ȳ, 1000 samples "bootstrap gennemsnit" "bootstrap spredning" "bootstrap sem" Frequency Histogram of bootstrap.pimax.snit bootstrap.pimax.snit "fraktiler for bootstrap gennemsnit" 1% 2.5% 5% 50% 95% 97.5% 99%
34 Deskriptiv statistik, januar Konfidensinterval Hvad tror vi på, at den sande middelværdi kan være? Et interval, der fanger den sande middelværdi med en passende høj (95%) sandsynlighed kaldes et 95% konfidensinterval 95% kaldes dækningsgraden eller coverage ȳ ± ca.2 SEM Dette er ofte en god approksimation, selv når data ikke er særligt pænt normalfordelt (på grund af CLT, den centrale grænseværdisætning) For PImax: 92.6 ± = (82.64, )
35 Deskriptiv statistik, januar Spredning=standard deviation, SD siger noget om variationen i vores sample, og formentlig i populationen benyttes ved beskrivelser af data Standard error (of the mean), SEM siger noget om usikkerheden på gennemsnittet SEM = SD n standard error (of mean, of estimate) = 1 n standard deviation benyttes ved sammenligninger, sammenhænge etc.
36 Deskriptiv statistik, januar Boxplot for PImax-eksempel Graph/Box Plot i Display skiftes til Schematic God ved sammenligning af fordelinger
37 Deskriptiv statistik, januar Hvis fordelingen er tydeligt skæv eller på anden måde afviger tydeligt fra normalfordelingen, bør man ikke angive gennemsnit og spredning, men snarere: fraktiler: median inter-quartile range, IQR: intervallet mellem 25% og 75% fraktil range Om muligt bør fordelingen illustreres grafisk! Alternativ: Transformer til normalitet. For små materialer angives median og range
38 Deskriptiv statistik, januar Hvis variablen Y er normalfordelt med middelværdi µ og varians σ 2, skriver vi y N(µ, σ 2 ) Standardiseret/normeret variabel: z = y µ s t(df) N(0, 1) når df = n 1 er stor
39 Deskriptiv statistik, januar
40 Deskriptiv statistik, januar Eksempel: Ud fra et stort materiale har vi fundet en gennemsnitlig Se-albumin på (g/l) og en empirisk varians på (g/l) 2 Hvis vi udfra dette antager at Se-albumin er normalfordelt med middelværdi g/l og spredning 5.84 g/l, hvad er så sandsynligheden for at en tilfældigt udvalgt person har en værdi over 42.0 g/l? Hvor mange standardafvigelser er 42.0 fra 34.46? = 1.29 Tabelopslag i standardnormalfordeling (B1) eller computer: P = %
41 Deskriptiv statistik, januar Kategoriske kun distinkte værdier mulige død ja/nej Typer af data fysisk aktivitet i 4 kategorier Kvantitative (numeriske) Diskrete (tælledata) antal børn i en famile antal metastaser Kontinuerte (måledata) Censurerede (e.g. levetider)
42 Deskriptiv statistik, januar Kategoriske data To kategorier (dikotom/binær): Mand/kvinde dør/overlever Gift/ugift Ryger/ikke ryger Flere end to: Nominal: Gift/ugift/fraskilt/enke(mand) Ordinal: minimal/moderat/alvorlig/uudholdelig smerte
43 Deskriptiv statistik, januar Diskrete kvantitative/numeriske data Tælletal Antal børn i en familie Antal metastaser/celler/bakteriekolonier Flydende grænser mellem diskrete numeriske og ordinale kategoriske data. OBS: Ofte meningsløst at behandle ordinale data som om de var numeriske. Gennemsnitlig socialklasse eller cancerstadium??
44 Deskriptiv statistik, januar Højde Vægt Se-kolesterol Blodtryk Kontinuerte data Måling på en sammenhængende skala. I praksis afrundede tal. Variable der antager mange værdier. Ofte noget med normalfordelingen
45 Deskriptiv statistik, januar Censurerede data Typisk overlevelsesdata For nogen data vides kun om de er større end en vis værdi. For andre kendes værdien. Patienten var i live ved sidste follow-up / pr. 1.jan NB: der er også trunkerede data hvor man slet ikke har data hvis de er mindre/større end en vis værdi: Tid til diagnose blandt patienter med symptomstart i 1995, fx.
46 Deskriptiv statistik, januar Outcome Forklarende variable = Kovariater Respons Dikotom Kategorisk Kontinuert Kategoriske og kontinuerte Dikotom 2*2-tabeller χ 2 -test Logistisk regression Kategorisk Kontingenstabeller/χ 2 -test Generaliseret logistisk regression Ordinale svært, f.eks. proportional odds modeller Kontinuert Mann-Whitney Kruskal-Wallis Robust multipel Wilcoxon signed rank Friedman regression Normalfordelt T-test Variansanalyse Kovariansanalyse parret/uparret ensidet/tosidet Multipel regression Censureret Log-rank test Cox regression Korrelerede Varianskomponent- Modeller for normalfordelte modeller gentagne målinger
47 Deskriptiv statistik, januar Beskrivelse af kategoriske data Stolpediagrammer (barplots) Tabeller Absolutte hyppigheder/frekvenser (antal) Relative hyppigheder (procenter)
48 Deskriptiv statistik, januar
49 Deskriptiv statistik, januar Tabeller Kejsersnit og skostørrelse: Absolutte frekvenser (antal) Shoe size Sectio < Total Yes No Total
50 Deskriptiv statistik, januar Tabeller - i procent Kejsersnit og skostørrelse: Relative frekvenser (i %) Shoe size Sectio < Total Yes No Total Fordel: direkte sammenlignelighed Ulempe: mister de faktiske antal
51 Deskriptiv statistik, januar Procenter, den anden vej Kejsersnit og skostørrelse: Relative frekvenser (i %) Shoe size Sectio < Total Yes No Total Dette siger noget om fodstørrelse og ikke så meget om hyppighed af kejsersnit
Deskriptiv Statitik. Judith L. Jacobsen, PhD. http://staff.pubhealth.ku.dk/~lts/basal09_1/ [email protected]
 Deskriptiv Statitik Judith L. Jacobsen, PhD. http://staff.pubhealth.ku.dk/~lts/basal09_1/ [email protected] Kursus formål Planlægning af studier selve indsamlingen af data, opstilling af statistiske hypoteser
Deskriptiv Statitik Judith L. Jacobsen, PhD. http://staff.pubhealth.ku.dk/~lts/basal09_1/ [email protected] Kursus formål Planlægning af studier selve indsamlingen af data, opstilling af statistiske hypoteser
Deskriptiv Statitik. Kursus formål. Deskriptiv Statistik MPH F 2009. Judith L. Jacobsen 1
 MPH Deskriptiv Statitik Judith L. Jacobsen, PhD. http://staff.pubhealth.ku.dk/~lts/basal09_1/ [email protected] Kursus formål Planlægning af studier selve indsamlingen af data, opstilling af statistiske hypoteser
MPH Deskriptiv Statitik Judith L. Jacobsen, PhD. http://staff.pubhealth.ku.dk/~lts/basal09_1/ [email protected] Kursus formål Planlægning af studier selve indsamlingen af data, opstilling af statistiske hypoteser
Kommentarer til opg. 1 og 3 ved øvelser i basalkursus, 3. uge
 Kommentarer til opg. 1 og 3 ved øvelser i basalkursus, 3. uge Opgave 1. Data indlæses i 3 kolonner, som f.eks. kaldessalt,pre ogpost. Der er således i alt tale om 26 observationer, idet de to grupper lægges
Kommentarer til opg. 1 og 3 ved øvelser i basalkursus, 3. uge Opgave 1. Data indlæses i 3 kolonner, som f.eks. kaldessalt,pre ogpost. Der er således i alt tale om 26 observationer, idet de to grupper lægges
Statistik Lektion 1. Introduktion Grundlæggende statistiske begreber Deskriptiv statistik Sandsynlighedsregning
 Statistik Lektion 1 Introduktion Grundlæggende statistiske begreber Deskriptiv statistik Sandsynlighedsregning Introduktion Kasper K. Berthelsen, Inst f. Matematiske Fag Omfang: 8 Kursusgang I fremtiden
Statistik Lektion 1 Introduktion Grundlæggende statistiske begreber Deskriptiv statistik Sandsynlighedsregning Introduktion Kasper K. Berthelsen, Inst f. Matematiske Fag Omfang: 8 Kursusgang I fremtiden
En Introduktion til SAS. Kapitel 5.
 En Introduktion til SAS. Kapitel 5. Inge Henningsen Afdeling for Statistik og Operationsanalyse Københavns Universitet Marts 2005 6. udgave Kapitel 5 T-test og PROC UNIVARIATE 5.1 Indledning Dette kapitel
En Introduktion til SAS. Kapitel 5. Inge Henningsen Afdeling for Statistik og Operationsanalyse Københavns Universitet Marts 2005 6. udgave Kapitel 5 T-test og PROC UNIVARIATE 5.1 Indledning Dette kapitel
Program. Modelkontrol og prædiktion. Multiple sammenligninger. Opgave 5.2: fosforkoncentration
 Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: [email protected] Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: [email protected] Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
Statistik Lektion 1. Introduktion Grundlæggende statistiske begreber Deskriptiv statistik
 Statistik Lektion 1 Introduktion Grundlæggende statistiske begreber Deskriptiv statistik Introduktion Kursusholder: Kasper K. Berthelsen Opbygning: Kurset består af 5 blokke En blok består af: To normale
Statistik Lektion 1 Introduktion Grundlæggende statistiske begreber Deskriptiv statistik Introduktion Kursusholder: Kasper K. Berthelsen Opbygning: Kurset består af 5 blokke En blok består af: To normale
Susanne Ditlevsen Institut for Matematiske Fag Email: [email protected] http://math.ku.dk/ susanne
 Statistik og Sandsynlighedsregning 1 Indledning til statistik, kap 2 i STAT Susanne Ditlevsen Institut for Matematiske Fag Email: [email protected] http://math.ku.dk/ susanne 5. undervisningsuge, onsdag
Statistik og Sandsynlighedsregning 1 Indledning til statistik, kap 2 i STAT Susanne Ditlevsen Institut for Matematiske Fag Email: [email protected] http://math.ku.dk/ susanne 5. undervisningsuge, onsdag
Binomial fordeling. n f (x) = p x (1 p) n x. x = 0, 1, 2,...,n = x. x x!(n x)! Eksempler. Middelværdi np og varians np(1 p). 2/
 = p x (1 p) n x. x = 0, 1, 2,...,n = x. x x!(n x)! Eksempler. Middelværdi np og varians np(1 p). 2/") Program: 1. Repetition af vigtige sandsynlighedsfordelinger: binomial, (Poisson,) normal (og χ 2 ). 2. Populationer og stikprøver 3. Opsummering af data vha. deskriptive størrelser og grafer. 1/29 Binomial
Program: 1. Repetition af vigtige sandsynlighedsfordelinger: binomial, (Poisson,) normal (og χ 2 ). 2. Populationer og stikprøver 3. Opsummering af data vha. deskriptive størrelser og grafer. 1/29 Binomial
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab. Introduktion
 Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Introduktion 1 Formelt Lærere: Esben Budtz-Jørgensen Jørgen Holm Petersen Øvelseslærere: Berivan+Kathrine, Amalie+Annabell Databehandling: SPSS
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Introduktion 1 Formelt Lærere: Esben Budtz-Jørgensen Jørgen Holm Petersen Øvelseslærere: Berivan+Kathrine, Amalie+Annabell Databehandling: SPSS
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006
 PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006 I dag: To stikprøver fra en normalfordeling, ikke-parametriske metoder og beregning af stikprøvestørrelse Eksempel: Fiskeolie
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006 I dag: To stikprøver fra en normalfordeling, ikke-parametriske metoder og beregning af stikprøvestørrelse Eksempel: Fiskeolie
Kapitel 3 Centraltendens og spredning
 Kapitel 3 Centraltendens og spredning Peter Tibert Stoltze [email protected] Elementær statistik F2011 1 / 25 Indledning I kapitel 2 omsatte vi de rå data til en tabel, der bedre viste materialets fordeling
Kapitel 3 Centraltendens og spredning Peter Tibert Stoltze [email protected] Elementær statistik F2011 1 / 25 Indledning I kapitel 2 omsatte vi de rå data til en tabel, der bedre viste materialets fordeling
Normalfordelingen. Statistik og Sandsynlighedsregning 2
 Normalfordelingen Statistik og Sandsynlighedsregning 2 Repetition og eksamen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige fejl på
Normalfordelingen Statistik og Sandsynlighedsregning 2 Repetition og eksamen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige fejl på
1. Lav en passende arbejdstegning, der illustrerer samtlige enkeltobservationer.
 Vejledende besvarelse af hjemmeopgave Basal statistik, efterår 2008 En gruppe bestående af 45 patienter med reumatoid arthrit randomiseres til en af 6 mulige behandlinger, nemlig placebo, aspirin eller
Vejledende besvarelse af hjemmeopgave Basal statistik, efterår 2008 En gruppe bestående af 45 patienter med reumatoid arthrit randomiseres til en af 6 mulige behandlinger, nemlig placebo, aspirin eller
Kvantitative Metoder 1 - Forår 2007. Dagens program
 Dagens program Kapitel 7 Introduktion til statistik Organisering af data Diskrete variabler Kontinuerte variabler Beskrivende statistik Fraktiler Gennemsnit Empirisk varians og spredning Empirisk korrelationkoe
Dagens program Kapitel 7 Introduktion til statistik Organisering af data Diskrete variabler Kontinuerte variabler Beskrivende statistik Fraktiler Gennemsnit Empirisk varians og spredning Empirisk korrelationkoe
Kursus 02402 Introduktion til Statistik. Forelæsning 7: Kapitel 7 og 8: Statistik for to gennemsnit, (7.7-7.8,8.1-8.5) Per Bruun Brockhoff
 Per Bruun Brockhoff") Kursus 02402 Introduktion til Statistik Forelæsning 7: Kapitel 7 og 8: Statistik for to gennemsnit, (7.7-7.8,8.1-8.5) Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks
Kursus 02402 Introduktion til Statistik Forelæsning 7: Kapitel 7 og 8: Statistik for to gennemsnit, (7.7-7.8,8.1-8.5) Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks
Deskriptiv statistik. Version 2.1. Noterne er et supplement til Vejen til matematik AB1. Henrik S. Hansen, Sct. Knuds Gymnasium
 Deskriptiv (beskrivende) statistik er den disciplin, der trækker de væsentligste oplysninger ud af et ofte uoverskueligt materiale. Det sker f.eks. ved at konstruere forskellige deskriptorer, d.v.s. regnestørrelser,
Deskriptiv (beskrivende) statistik er den disciplin, der trækker de væsentligste oplysninger ud af et ofte uoverskueligt materiale. Det sker f.eks. ved at konstruere forskellige deskriptorer, d.v.s. regnestørrelser,
Oversigt. Course 02402/02323 Introducerende Statistik. Forelæsning 3: Kontinuerte fordelinger. Per Bruun Brockhoff
 Course 242/2323 Introducerende Statistik Forelæsning 3: Kontinuerte fordelinger Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 22 Danmarks Tekniske Universitet 28 Lyngby Danmark
Course 242/2323 Introducerende Statistik Forelæsning 3: Kontinuerte fordelinger Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 22 Danmarks Tekniske Universitet 28 Lyngby Danmark
3.600 kg og den gennemsnitlige fødselsvægt kg i stikprøven.
 PhD-kursus i Basal Biostatistik, efterår 2006 Dag 1, onsdag den 6. september 2006 Eksempel: Sammenhæng mellem moderens alder og fødselsvægt I dag: Introduktion til statistik gennem analyse af en stikprøve
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 1, onsdag den 6. september 2006 Eksempel: Sammenhæng mellem moderens alder og fødselsvægt I dag: Introduktion til statistik gennem analyse af en stikprøve
Modul 5: Test for én stikprøve
 Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen Modul 5: Test for én stikprøve 5.1 Test for middelværdi................................. 1 5.1.1 t-fordelingen.................................
Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen Modul 5: Test for én stikprøve 5.1 Test for middelværdi................................. 1 5.1.1 t-fordelingen.................................
Forelæsning 6: Kapitel 7: Hypotesetest for gennemsnit (one-sample setup). 7.4-7.6
. 7.4-7.6") Kursus 02402 Introduktion til Statistik Forelæsning 6: Kapitel 7: Hypotesetest for gennemsnit (one-sample setup). 7.4-7.6 Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220
Kursus 02402 Introduktion til Statistik Forelæsning 6: Kapitel 7: Hypotesetest for gennemsnit (one-sample setup). 7.4-7.6 Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220
Værktøjshjælp for TI-Nspire CAS Struktur for appendiks:
 Værktøjshjælp for TI-Nspire CAS Struktur for appendiks: Til hvert af de gennemgåede værktøjer findes der 5 afsnit. De enkelte afsnit kan læses uafhængigt af hinanden. Der forudsættes et elementært kendskab
Værktøjshjælp for TI-Nspire CAS Struktur for appendiks: Til hvert af de gennemgåede værktøjer findes der 5 afsnit. De enkelte afsnit kan læses uafhængigt af hinanden. Der forudsættes et elementært kendskab
Anvendt Statistik Lektion 6. Kontingenstabeller χ 2 -test [ki-i-anden-test]
![Anvendt Statistik Lektion 6. Kontingenstabeller χ 2 -test [ki-i-anden-test]](/thumbs/30/14715329.jpg "Anvendt Statistik Lektion 6. Kontingenstabeller χ 2 -test [ki-i-anden-test]") Anvendt Statistik Lektion 6 Kontingenstabeller χ 2 -test [ki-i-anden-test] 1 Kontingenstabel Formål: Illustrere/finde sammenhænge mellem to kategoriske variable Opbygning: En celle for hver kombination
Anvendt Statistik Lektion 6 Kontingenstabeller χ 2 -test [ki-i-anden-test] 1 Kontingenstabel Formål: Illustrere/finde sammenhænge mellem to kategoriske variable Opbygning: En celle for hver kombination
Det kunne godt se ud til at ikke-rygere er ældre. Spredningen ser ud til at være nogenlunde ens i de to grupper.
 1. Indlæs data. * HUSK at angive din egen placering af filen; data framing; infile '/home/sro00/mph2016/framing.txt' firstobs=2; input id sex age frw sbp sbp10 dbp chol cig chd yrschd death yrsdth cause;
1. Indlæs data. * HUSK at angive din egen placering af filen; data framing; infile '/home/sro00/mph2016/framing.txt' firstobs=2; input id sex age frw sbp sbp10 dbp chol cig chd yrschd death yrsdth cause;
Dagens Temaer. Test for lineær regression. Test for lineær regression - via proc glm. k normalfordelte obs. rækker i proc glm. p. 1/??
 Dagens Temaer k normalfordelte obs. rækker i proc glm. Test for lineær regression Test for lineær regression - via proc glm p. 1/?? Proc glm Vi indlæser data i datasættet stress, der har to variable: areal,
Dagens Temaer k normalfordelte obs. rækker i proc glm. Test for lineær regression Test for lineær regression - via proc glm p. 1/?? Proc glm Vi indlæser data i datasættet stress, der har to variable: areal,
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab. Introduktion
 Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Introduktion 1 Formelt Lærer: Jørgen Holm Petersen Øvelseslærere: Signe, Helene, Marie, Amalie Databehandling: SPSS Eksamen: Ugeopgave efterfulgt
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Introduktion 1 Formelt Lærer: Jørgen Holm Petersen Øvelseslærere: Signe, Helene, Marie, Amalie Databehandling: SPSS Eksamen: Ugeopgave efterfulgt
Kursus Introduktion til Statistik. Forelæsning 13: Summary. Per Bruun Brockhoff
 Kursus 02402 Introduktion til Statistik Forelæsning 13: Summary Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks Tekniske Universitet 2800 Lyngby Danmark e-mail:
Kursus 02402 Introduktion til Statistik Forelæsning 13: Summary Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks Tekniske Universitet 2800 Lyngby Danmark e-mail:
Note til styrkefunktionen
 Teoretisk Statistik. årsprøve Note til styrkefunktionen Først er det vigtigt at gøre sig klart, at når man laver statistiske test, så kan man begå to forskellige typer af fejl: Type fejl: At forkaste H
Teoretisk Statistik. årsprøve Note til styrkefunktionen Først er det vigtigt at gøre sig klart, at når man laver statistiske test, så kan man begå to forskellige typer af fejl: Type fejl: At forkaste H
Statistik Lektion 20 Ikke-parametriske metoder. Repetition Kruskal-Wallis Test Friedman Test Chi-i-anden Test
 Statistik Lektion 0 Ikkeparametriske metoder Repetition KruskalWallis Test Friedman Test Chiianden Test Run Test Er sekvensen opstået tilfældigt? PPPKKKPPPKKKPPKKKPPP Et run er en sekvens af ens elementer,
Statistik Lektion 0 Ikkeparametriske metoder Repetition KruskalWallis Test Friedman Test Chiianden Test Run Test Er sekvensen opstået tilfældigt? PPPKKKPPPKKKPPKKKPPP Et run er en sekvens af ens elementer,
MPH specialmodul Epidemiologi og Biostatistik
 MPH specialmodul Epidemiologi og Biostatistik Kvantitative udfaldsvariable 23. maj 2011 www.biostat.ku.dk/~sr/mphspec11 Susanne Rosthøj (Per Kragh Andersen) 1 Kapitelhenvisninger Andersen & Skovgaard:
MPH specialmodul Epidemiologi og Biostatistik Kvantitative udfaldsvariable 23. maj 2011 www.biostat.ku.dk/~sr/mphspec11 Susanne Rosthøj (Per Kragh Andersen) 1 Kapitelhenvisninger Andersen & Skovgaard:
Eksamen ved. Københavns Universitet i. Kvantitative forskningsmetoder. Det Samfundsvidenskabelige Fakultet
 Eksamen ved Københavns Universitet i Kvantitative forskningsmetoder Det Samfundsvidenskabelige Fakultet 14. december 2011 Eksamensnummer: 5 14. december 2011 Side 1 af 6 1) Af boxplottet kan man aflæse,
Eksamen ved Københavns Universitet i Kvantitative forskningsmetoder Det Samfundsvidenskabelige Fakultet 14. december 2011 Eksamensnummer: 5 14. december 2011 Side 1 af 6 1) Af boxplottet kan man aflæse,
Kursusindhold: Produkt og marked - matematiske og statistiske metoder. Monte Carlo
 Kursusindhold: Produkt og marked - matematiske og statistiske metoder Rasmus Waagepetersen Institut for Matematiske Fag Aalborg Universitet Sandsynlighedsregning og lagerstyring Normalfordelingen og Monte
Kursusindhold: Produkt og marked - matematiske og statistiske metoder Rasmus Waagepetersen Institut for Matematiske Fag Aalborg Universitet Sandsynlighedsregning og lagerstyring Normalfordelingen og Monte
Produkt og marked - matematiske og statistiske metoder
 Produkt og marked - matematiske og statistiske metoder Rasmus Waagepetersen Institut for Matematiske Fag Aalborg Universitet February 19, 2016 1/26 Kursusindhold: Sandsynlighedsregning og lagerstyring
Produkt og marked - matematiske og statistiske metoder Rasmus Waagepetersen Institut for Matematiske Fag Aalborg Universitet February 19, 2016 1/26 Kursusindhold: Sandsynlighedsregning og lagerstyring
Opsamling Modeltyper: Tabelanalyse Logistisk regression Generaliserede lineære modeller Log-lineære modeller
 Opsamling Modeltyper: Tabelanalyse Logistisk regression Binær respons og kategorisk eller kontinuerte forklarende variable. Generaliserede lineære modeller Normalfordelt respons og kategoriske forklarende
Opsamling Modeltyper: Tabelanalyse Logistisk regression Binær respons og kategorisk eller kontinuerte forklarende variable. Generaliserede lineære modeller Normalfordelt respons og kategoriske forklarende
Kursus i varians- og regressionsanalyse Data med detektionsgrænse. Birthe Lykke Thomsen H. Lundbeck A/S
 Kursus i varians- og regressionsanalyse Data med detektionsgrænse Birthe Lykke Thomsen H. Lundbeck A/S 1 Data med detektionsgrænse Venstrecensurering: Baggrundsstøj eller begrænsning i måleudstyrets følsomhed
Kursus i varians- og regressionsanalyse Data med detektionsgrænse Birthe Lykke Thomsen H. Lundbeck A/S 1 Data med detektionsgrænse Venstrecensurering: Baggrundsstøj eller begrænsning i måleudstyrets følsomhed
6. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag)
") Institut for Epidemiologi og Socialmedicin Institut for Biostatistik. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag) Opgave 1 Læs afsnit.1 i An Introduction to Medical Statistics, specielt
Institut for Epidemiologi og Socialmedicin Institut for Biostatistik. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag) Opgave 1 Læs afsnit.1 i An Introduction to Medical Statistics, specielt
Statistik. Introduktion Deskriptiv statistik Sandsynslighedregning
 Statistik Introduktion Deskriptiv statistik Sandsynslighedregning Introduktion Kasper K. Berthelsen, Institut f. Mat. Fag 8 Kursusgange Individuel mundtlig eksamen (7-skala) Udgangspunkt i opgaver Software:
Statistik Introduktion Deskriptiv statistik Sandsynslighedregning Introduktion Kasper K. Berthelsen, Institut f. Mat. Fag 8 Kursusgange Individuel mundtlig eksamen (7-skala) Udgangspunkt i opgaver Software:
OR stiger eksponentielt med forskellen i BMI. kompliceret model svær at forstå og analysere
 Epidemiologi og biostatistik. Uge 5, torsdag 5. september 003 Morten Frydenberg, Institut for Biostatistik. 1 Analyse af overlevelsesdata (ventetidsdata) Censurering (højre + andet) Kaplan-Meyer kurver
Epidemiologi og biostatistik. Uge 5, torsdag 5. september 003 Morten Frydenberg, Institut for Biostatistik. 1 Analyse af overlevelsesdata (ventetidsdata) Censurering (højre + andet) Kaplan-Meyer kurver
Multipel regression. M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model
 M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model") Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
Introduktion til overlevelsesanalyse
 Faculty of Health Sciences Introduktion til overlevelsesanalyse Kaplan-Meier estimatoren Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected]
Faculty of Health Sciences Introduktion til overlevelsesanalyse Kaplan-Meier estimatoren Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected]
OR stiger eksponentielt med forskellen i BMI komplicet model svær at forstå og analysere simpel model
 Epidemiologi og biostatistik. Uge 5, torsdag. marts 1 Morten Frydenberg, Institut for Biostatistik. 1 Analyse af overlevelsesdata (ventetidsdata) Censurering (højre + andet) Kaplan-Meyer kurver Det statistiske
Epidemiologi og biostatistik. Uge 5, torsdag. marts 1 Morten Frydenberg, Institut for Biostatistik. 1 Analyse af overlevelsesdata (ventetidsdata) Censurering (højre + andet) Kaplan-Meyer kurver Det statistiske
6. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag)
") Institut for Folkesundhed Afdeling for Biostatistik Afdeling for Epidemiologi. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag) Opgave 1 Udgangspunktet for de følgende spørgsmål er artiklen:
Institut for Folkesundhed Afdeling for Biostatistik Afdeling for Epidemiologi. SEMESTER Epidemiologi og Biostatistik Opgaver til Uge 1 (fredag) Opgave 1 Udgangspunktet for de følgende spørgsmål er artiklen:
Forelæsning 3: Kapitel 5: Kontinuerte fordelinger
 Kursus 02402 Introduktion til Statistik Forelæsning 3: Kapitel 5: Kontinuerte fordelinger Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks Tekniske Universitet 2800
Kursus 02402 Introduktion til Statistik Forelæsning 3: Kapitel 5: Kontinuerte fordelinger Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks Tekniske Universitet 2800
Normalfordelingen og Stikprøvefordelinger
 Normalfordelingen og Stikprøvefordelinger Normalfordelingen Standard Normal Fordelingen Sandsynligheder for Normalfordelingen Transformation af Normalfordelte Stok.Var. Stikprøver og Stikprøvefordelinger
Normalfordelingen og Stikprøvefordelinger Normalfordelingen Standard Normal Fordelingen Sandsynligheder for Normalfordelingen Transformation af Normalfordelte Stok.Var. Stikprøver og Stikprøvefordelinger
Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06)
") Afdeling for Biostatistik Bo Martin Bibby 23. november 2006 Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06) Vi betragter 4699 personer fra Framingham-studiet. Der er oplysninger om follow-up
Afdeling for Biostatistik Bo Martin Bibby 23. november 2006 Løsning til eksamensopgaven i Basal Biostatistik (J.nr.: 1050/06) Vi betragter 4699 personer fra Framingham-studiet. Der er oplysninger om follow-up
Mikro-kursus i statistik 1. del. 24-11-2002 Mikrokursus i biostatistik 1
 Mikro-kursus i statistik 1. del 24-11-2002 Mikrokursus i biostatistik 1 Hvad er statistik? Det systematiske studium af tilfældighedernes spil!dyrkes af biostatistikere Anvendes som redskab til vurdering
Mikro-kursus i statistik 1. del 24-11-2002 Mikrokursus i biostatistik 1 Hvad er statistik? Det systematiske studium af tilfældighedernes spil!dyrkes af biostatistikere Anvendes som redskab til vurdering
Logistisk regression. Basal Statistik for medicinske PhD-studerende November 2008
 Logistisk regression Basal Statistik for medicinske PhD-studerende November 2008 Bendix Carstensen Steno Diabetes Center, Gentofte & Biostatististisk afdeling, Københavns Universitet [email protected] www.biostat.ku.dk/~bxc
Logistisk regression Basal Statistik for medicinske PhD-studerende November 2008 Bendix Carstensen Steno Diabetes Center, Gentofte & Biostatististisk afdeling, Københavns Universitet [email protected] www.biostat.ku.dk/~bxc
Ikke-parametriske metoder. Repetition Wilcoxon Signed-Rank Test Kruskal-Wallis Test Friedman Test Chi-i-anden Test
 Ikkeparametriske metoder Repetition Wilcoxon SignedRank Test KruskalWallis Test Friedman Test Chiianden Test Run Test Er sekvensen opstået tilfældigt? PPPKKKPPPKKKPPKKKPPP Et run er en sekvens af ens elementer,
Ikkeparametriske metoder Repetition Wilcoxon SignedRank Test KruskalWallis Test Friedman Test Chiianden Test Run Test Er sekvensen opstået tilfældigt? PPPKKKPPPKKKPPKKKPPP Et run er en sekvens af ens elementer,
Kapitel 3 Centraltendens og spredning
 Kapitel 3 Centraltendens og spredning Peter Tibert Stoltze [email protected] Elementær statistik F2011 1 Indledning 2 Centraltendens 3 Spredning 4 Praktisk beregning 5 Fraktiler 6 Opsamling 1 Indledning
Kapitel 3 Centraltendens og spredning Peter Tibert Stoltze [email protected] Elementær statistik F2011 1 Indledning 2 Centraltendens 3 Spredning 4 Praktisk beregning 5 Fraktiler 6 Opsamling 1 Indledning
Program: 1. Repetition: fordeling af observatorer X, S 2 og t. 2. Konfidens-intervaller, hypotese test, type I og type II fejl, styrke.
 Program: 1. Repetition: fordeling af observatorer X, S 2 og t. 2. Konfidens-intervaller, hypotese test, type I og type II fejl, styrke. 1/23 Opsummering af fordelinger X 1. Kendt σ: Z = X µ σ/ n N(0,1)
Program: 1. Repetition: fordeling af observatorer X, S 2 og t. 2. Konfidens-intervaller, hypotese test, type I og type II fejl, styrke. 1/23 Opsummering af fordelinger X 1. Kendt σ: Z = X µ σ/ n N(0,1)
9. Chi-i-anden test, case-control data, logistisk regression.
 Biostatistik - Cand.Scient.San. 2. semester Karl Bang Christensen Biostatististisk afdeling, KU [email protected], 35327491 9. Chi-i-anden test, case-control data, logistisk regression. http://biostat.ku.dk/~kach/css2014/
Biostatistik - Cand.Scient.San. 2. semester Karl Bang Christensen Biostatististisk afdeling, KU [email protected], 35327491 9. Chi-i-anden test, case-control data, logistisk regression. http://biostat.ku.dk/~kach/css2014/
Program. Logistisk regression. Eksempel: pesticider og møl. Odds og odds-ratios (igen)
") Faculty of Life Sciences Program Logistisk regression Claus Ekstrøm E-mail: [email protected] Odds og odds-ratios igen Logistisk regression Estimation og inferens Modelkontrol Slide 2 Statistisk Dataanalyse
Faculty of Life Sciences Program Logistisk regression Claus Ekstrøm E-mail: [email protected] Odds og odds-ratios igen Logistisk regression Estimation og inferens Modelkontrol Slide 2 Statistisk Dataanalyse
Løsning til øvelsesopgaver dag 4 spg 5-9
 Løsning til øvelsesopgaver dag 4 spg 5-9 5: Den multiple model Vi tilføjer nu yderligere to variable til vores model : Køn og kolesterol SBP = a + b*age + c*chol + d*mand hvor mand er 1 for mænd, 0 for
Løsning til øvelsesopgaver dag 4 spg 5-9 5: Den multiple model Vi tilføjer nu yderligere to variable til vores model : Køn og kolesterol SBP = a + b*age + c*chol + d*mand hvor mand er 1 for mænd, 0 for
Løsning eksamen d. 15. december 2008
 Informatik - DTU 02402 Introduktion til Statistik 2010-2-01 LFF/lff Løsning eksamen d. 15. december 2008 Referencer til Probability and Statistics for Engineers er angivet i rækkefølgen [8th edition, 7th
Informatik - DTU 02402 Introduktion til Statistik 2010-2-01 LFF/lff Løsning eksamen d. 15. december 2008 Referencer til Probability and Statistics for Engineers er angivet i rækkefølgen [8th edition, 7th
24. februar Analyse af overlevelsesdata (ventetidsdata) Ikke parametrisk statistiske test : Det statistiske modelbegreb Modelselektion
 Ikke parametrisk statistiske test : Det statistiske modelbegreb Modelselektion") . februar 00 Ikke parametrisk statistiske test : Ideen bag Epidemiologi og biostatistik. Uge, mandag. februar 00 Morten Frydenberg, Institut for Biostatistik. To grupper: Mann-Whitney / Wilcoxon testet
. februar 00 Ikke parametrisk statistiske test : Ideen bag Epidemiologi og biostatistik. Uge, mandag. februar 00 Morten Frydenberg, Institut for Biostatistik. To grupper: Mann-Whitney / Wilcoxon testet
Sandsynlighedsregning: endeligt udfaldsrum (repetition)
") Program: 1. Repetition: sandsynlighedsregning 2. Sandsynlighedsregning fortsat: stokastisk variabel, sandsynlighedsfunktion/tæthed, fordelingsfunktion. 1/16 Sandsynlighedsregning: endeligt udfaldsrum (repetition)
Program: 1. Repetition: sandsynlighedsregning 2. Sandsynlighedsregning fortsat: stokastisk variabel, sandsynlighedsfunktion/tæthed, fordelingsfunktion. 1/16 Sandsynlighedsregning: endeligt udfaldsrum (repetition)
Konfidensinterval for µ (σ kendt)
") Program 1. Repetition: konfidens-intervaller. 2. Hypotese test 3. Type I og type II fejl, p-værdi 4. En og to-sidede tests 5. Test for middelværdi (kendt varians) 6. Test for middelværdi (ukendt varians)
Program 1. Repetition: konfidens-intervaller. 2. Hypotese test 3. Type I og type II fejl, p-værdi 4. En og to-sidede tests 5. Test for middelværdi (kendt varians) 6. Test for middelværdi (ukendt varians)
Statistik II 4. Lektion. Logistisk regression
 Statistik II 4. Lektion Logistisk regression Logistisk regression: Motivation Generelt setup: Dikotom(binær) afhængig variabel Kontinuerte og kategoriske forklarende variable (som i lineær reg.) Eksempel:
Statistik II 4. Lektion Logistisk regression Logistisk regression: Motivation Generelt setup: Dikotom(binær) afhængig variabel Kontinuerte og kategoriske forklarende variable (som i lineær reg.) Eksempel:
Epidemiologi og Biostatistik
 Kapitel 1, Kliniske målinger Epidemiologi og Biostatistik Introduktion til skilder (varianskomponenter) måleusikkerhed sammenligning af målemetoder Mogens Erlandsen, Institut for Biostatistik Uge, torsdag
Kapitel 1, Kliniske målinger Epidemiologi og Biostatistik Introduktion til skilder (varianskomponenter) måleusikkerhed sammenligning af målemetoder Mogens Erlandsen, Institut for Biostatistik Uge, torsdag
Besvarelse af vitcap -opgaven
 Besvarelse af -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Beskriv fordelingen af vital capacity og i de 3 grupper ved hjælp af summary statistics.
Besvarelse af -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Beskriv fordelingen af vital capacity og i de 3 grupper ved hjælp af summary statistics.
Program. Konfidensinterval og hypotesetest, del 2 en enkelt normalfordelt stikprøve I SAS. Øvelse: effekt af diæter
 Program Konfidensinterval og hypotesetest, del 2 en enkelt normalfordelt stikprøve Helle Sørensen E-mail: [email protected] I formiddag: Øvelse: effekt af diæter. Repetition fra sidst... Parrede og ikke-parrede
Program Konfidensinterval og hypotesetest, del 2 en enkelt normalfordelt stikprøve Helle Sørensen E-mail: [email protected] I formiddag: Øvelse: effekt af diæter. Repetition fra sidst... Parrede og ikke-parrede
Konfidensintervaller og Hypotesetest
 Konfidensintervaller og Hypotesetest Konfidensinterval for andele χ -fordelingen og konfidensinterval for variansen Hypoteseteori Hypotesetest af middelværdi, varians og andele Repetition fra sidst: Konfidensintervaller
Konfidensintervaller og Hypotesetest Konfidensinterval for andele χ -fordelingen og konfidensinterval for variansen Hypoteseteori Hypotesetest af middelværdi, varians og andele Repetition fra sidst: Konfidensintervaller
Program. 1. Repetition 2. Fordeling af empirisk middelværdi og varians, t-fordeling, begreber vedr. estimation. 1/18
 Program 1. Repetition 2. Fordeling af empirisk middelværdi og varians, t-fordeling, begreber vedr. estimation. 1/18 Fordeling af X Stikprøve X 1,X 2,...,X n stokastisk X stokastisk. Ex (normalfordelt stikprøve)
Program 1. Repetition 2. Fordeling af empirisk middelværdi og varians, t-fordeling, begreber vedr. estimation. 1/18 Fordeling af X Stikprøve X 1,X 2,...,X n stokastisk X stokastisk. Ex (normalfordelt stikprøve)
Reeksamen i Statistik for Biokemikere 6. april 2009
 Københavns Universitet Det Naturvidenskabelige Fakultet Reeksamen i Statistik for Biokemikere 6. april 2009 Alle hjælpemidler er tilladt, og besvarelsen må gerne skrives med blyant. Opgavesættet er på
Københavns Universitet Det Naturvidenskabelige Fakultet Reeksamen i Statistik for Biokemikere 6. april 2009 Alle hjælpemidler er tilladt, og besvarelsen må gerne skrives med blyant. Opgavesættet er på
Module 2: Beskrivende Statistik
 Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen og Hans Chr. Petersen Module 2: Beskrivende Statistik 2.1 Histogrammer og søjlediagrammer......................... 1 2.2 Sammenfatning
Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen og Hans Chr. Petersen Module 2: Beskrivende Statistik 2.1 Histogrammer og søjlediagrammer......................... 1 2.2 Sammenfatning
Basal Statistik Kategoriske Data
 Basal Statistik Kategoriske Data 8 oktober 2013 E 2013 Basal Statistik - Kategoriske data Michael Gamborg Institut for sygdomsforebyggelse Københavns Universitetshospital [email protected]
Basal Statistik Kategoriske Data 8 oktober 2013 E 2013 Basal Statistik - Kategoriske data Michael Gamborg Institut for sygdomsforebyggelse Københavns Universitetshospital [email protected]
Uge 10 Teoretisk Statistik 1. marts 2004
 1 Uge 10 Teoretisk Statistik 1. marts 004 1. u-fordelingen. Normalfordelingen 3. Middelværdi og varians 4. Mere normalfordelingsteori 5. Grafisk kontrol af normalfordelingsantagelse 6. Eksempler 7. Oversigt
1 Uge 10 Teoretisk Statistik 1. marts 004 1. u-fordelingen. Normalfordelingen 3. Middelværdi og varians 4. Mere normalfordelingsteori 5. Grafisk kontrol af normalfordelingsantagelse 6. Eksempler 7. Oversigt
Lineær regression. Simpel regression. Model. ofte bruges følgende notation:
 Lineær regression Simpel regression Model Y i X i i ofte bruges følgende notation: Y i 0 1 X 1i i n i 1 i 0 Findes der en linie, der passer bedst? Metode - Generel! least squares (mindste kvadrater) til
Lineær regression Simpel regression Model Y i X i i ofte bruges følgende notation: Y i 0 1 X 1i i n i 1 i 0 Findes der en linie, der passer bedst? Metode - Generel! least squares (mindste kvadrater) til
Logistisk Regression. Repetition Fortolkning af odds Test i logistisk regression
 Logistisk Regression Repetition Fortolkning af odds Test i logistisk regression Logisitks Regression: Repetition Y {0,} binær afhængig variabel X skala forklarende variabel π P( Y X x) Odds(Y X x) π /(-π
Logistisk Regression Repetition Fortolkning af odds Test i logistisk regression Logisitks Regression: Repetition Y {0,} binær afhængig variabel X skala forklarende variabel π P( Y X x) Odds(Y X x) π /(-π
Modelkontrol i Faktor Modeller
 Modelkontrol i Faktor Modeller Julie Lyng Forman Københavns Universitet Afdeling for Anvendt Matematik og Statistik Statistik for Biokemikere 2003 For at konklusionerne på en ensidet, flersidet eller hierarkisk
Modelkontrol i Faktor Modeller Julie Lyng Forman Københavns Universitet Afdeling for Anvendt Matematik og Statistik Statistik for Biokemikere 2003 For at konklusionerne på en ensidet, flersidet eller hierarkisk
Hypoteser om mere end to stikprøver ANOVA. k stikprøver: (ikke ordinale eller højere) gælder også for k 2! : i j
 gælder også for k 2! : i j") Hypoteser om mere end to stikprøver ANOVA k stikprøver: (ikke ordinale eller højere) H 0 : 1 2... k gælder også for k 2! H 0ij : i j H 0ij : i j simpelt forslag: k k 1 2 t-tests: i j DUER IKKE! Bonferroni!!
Hypoteser om mere end to stikprøver ANOVA k stikprøver: (ikke ordinale eller højere) H 0 : 1 2... k gælder også for k 2! H 0ij : i j H 0ij : i j simpelt forslag: k k 1 2 t-tests: i j DUER IKKE! Bonferroni!!
Statistiske modeller
 Statistiske modeller Statistisk model Datamatrice Variabelmatrice Hændelse Sandsynligheder Data Statistiske modeller indeholder: Variable Hændelser defineret ved mulige variabel værdier Sandsynligheder
Statistiske modeller Statistisk model Datamatrice Variabelmatrice Hændelse Sandsynligheder Data Statistiske modeller indeholder: Variable Hændelser defineret ved mulige variabel værdier Sandsynligheder
Statistik II Lektion 3. Logistisk Regression Kategoriske og Kontinuerte Forklarende Variable
 Statistik II Lektion 3 Logistisk Regression Kategoriske og Kontinuerte Forklarende Variable Setup: To binære variable X og Y. Statistisk model: Konsekvens: Logistisk regression: 2 binære var. e e X Y P
Statistik II Lektion 3 Logistisk Regression Kategoriske og Kontinuerte Forklarende Variable Setup: To binære variable X og Y. Statistisk model: Konsekvens: Logistisk regression: 2 binære var. e e X Y P
Statistik Lektion 1. Introduktion Grundlæggende statistiske begreber Deskriptiv statistik Sandsynlighedsregning
 Statistik Lektion 1 Introduktion Grundlæggende statistiske begreber Deskriptiv statistik Sandsynlighedsregning Introduktion Kasper K. Berthelsen, Inst f. Matematiske Fag Omfang: 8 Kursusgang I fremtiden
Statistik Lektion 1 Introduktion Grundlæggende statistiske begreber Deskriptiv statistik Sandsynlighedsregning Introduktion Kasper K. Berthelsen, Inst f. Matematiske Fag Omfang: 8 Kursusgang I fremtiden
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab. Estimation
 Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Estimation Eksempel: Bissau data Data kommer fra Guinea-Bissau i Vestafrika: 5273 børn blev undersøgt da de var yngre end 7 mdr og blev herefter
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Estimation Eksempel: Bissau data Data kommer fra Guinea-Bissau i Vestafrika: 5273 børn blev undersøgt da de var yngre end 7 mdr og blev herefter
Statikstik II 2. Lektion. Lidt sandsynlighedsregning Lidt mere om signifikanstest Logistisk regression
 Statikstik II 2. Lektion Lidt sandsynlighedsregning Lidt mere om signifikanstest Logistisk regression Sandsynlighedsregningsrepetition Antag at Svar kan være Ja og Nej. Sandsynligheden for at Svar Ja skrives
Statikstik II 2. Lektion Lidt sandsynlighedsregning Lidt mere om signifikanstest Logistisk regression Sandsynlighedsregningsrepetition Antag at Svar kan være Ja og Nej. Sandsynligheden for at Svar Ja skrives
Morten Frydenberg 26. april 2004
 Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik RESUME: 2 2. gang: 2002 Institut for Biostatistik, Århus Universitet MPH. studieår Specialmodul 4 Cand. San. uddannelsen.
Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik RESUME: 2 2. gang: 2002 Institut for Biostatistik, Århus Universitet MPH. studieår Specialmodul 4 Cand. San. uddannelsen.
Program. 1. Repetition: konfidens-intervaller. 2. Hypotese test, type I og type II fejl, signifikansniveau, styrke, en- og to-sidede test.
 Program 1. Repetition: konfidens-intervaller. 2. Hypotese test, type I og type II fejl, signifikansniveau, styrke, en- og to-sidede test. 1/19 Konfidensinterval for µ (σ kendt) Estimat ˆµ = X bedste bud
Program 1. Repetition: konfidens-intervaller. 2. Hypotese test, type I og type II fejl, signifikansniveau, styrke, en- og to-sidede test. 1/19 Konfidensinterval for µ (σ kendt) Estimat ˆµ = X bedste bud
Vejledende besvarelse af hjemmeopgave i Basal statistik for lægevidenskabelige forskere, forår 2013
 Vejledende besvarelse af hjemmeopgave i Basal statistik for lægevidenskabelige forskere, forår 2013 I forbindelse med reagensglasbehandling blev 100 par randomiseret til to forskellige former for hormonstimulation.
Vejledende besvarelse af hjemmeopgave i Basal statistik for lægevidenskabelige forskere, forår 2013 I forbindelse med reagensglasbehandling blev 100 par randomiseret til to forskellige former for hormonstimulation.
Skriftlig eksamen Science statistik- ST501
 SYDDANSK UNIVERSITET INSTITUT FOR MATEMATIK OG DATALOGI Skriftlig eksamen Science statistik- ST501 Torsdag den 21. januar Opgavesættet består af 5 opgaver, med i alt 13 delspørgsmål, som vægtes ligeligt.
SYDDANSK UNIVERSITET INSTITUT FOR MATEMATIK OG DATALOGI Skriftlig eksamen Science statistik- ST501 Torsdag den 21. januar Opgavesættet består af 5 opgaver, med i alt 13 delspørgsmål, som vægtes ligeligt.
Opgaver til kapitel 3
 Opgaver til kapitel 3 3.1 En løber er interesseret i at undersøge om hendes løbeur er kalibreret korrekt. Hun udmåler derfor en strækning på præcis 1000 m og løber den 16 gange. For hver løbetur noterer
Opgaver til kapitel 3 3.1 En løber er interesseret i at undersøge om hendes løbeur er kalibreret korrekt. Hun udmåler derfor en strækning på præcis 1000 m og løber den 16 gange. For hver løbetur noterer
1 Hb SS Hb Sβ Hb SC = , (s = )
") PhD-kursus i Basal Biostatistik, efterår 2006 Dag 6, onsdag den 11. oktober 2006 Eksempel 9.1: Hæmoglobin-niveau og seglcellesygdom Data: Hæmoglobin-niveau (g/dl) for 41 patienter med en af tre typer seglcellesygdom.
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 6, onsdag den 11. oktober 2006 Eksempel 9.1: Hæmoglobin-niveau og seglcellesygdom Data: Hæmoglobin-niveau (g/dl) for 41 patienter med en af tre typer seglcellesygdom.