Multipel regression 22. Maj, 2012
|
|
|
- Victor Skov
- 10 år siden
- Visninger:
Transkript
1 Data: Det færøske kviksølv-studie Simpel linær regression Confounding Multipel lineær regression Fortolkning af parametre Vekselvirkning Kollinearitet Modelkontrol Multipel regression 22. Maj, 2012 Esben Budtz-Jørgensen Biostatistisk Afdeling, Københavns Universitet

2 Grinde hvaler

3 Study Design EXPOSURE: 1. Cord Blood Mercury 2. Maternal Hair Mercury 3. Maternal Seafood Intake RESPONSE: Neuropsychological Tests Age: Calendar: Children: Birth Years

4 Neuropsykologisk Testing
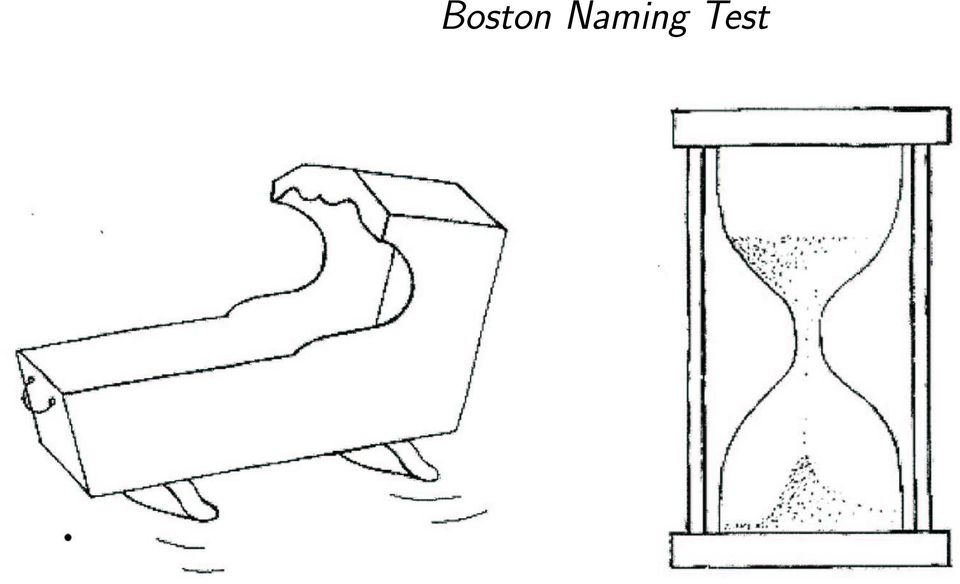
5 Boston Naming Test
6 Scatterplots: Boston Naming vs Hg-koncentration hg1$bostot hg1$bostot hg1$bhg hg1$bhg plot(hg1$bhg,hg1$bostot) plot(hg1$bhg,hg1$bostot,log="x") Svag sammenhæng mellem barnets score og Hg-eksponering Enkelte højt eksponerede bliver meget indflydelsesrige hvis jeg ikke bruger log-transformation.

7 Logaritme transformation eller ej? Jeg vil lave en regression af barnets score på eksponeringen. Men skal jeg logaritmetransformere Hg-koncentrationerne? To mulige modeller Model 1: bostot = α + βb-hg + ǫ Model 2: bostot = α + β log 10 (B-Hg) + ǫ

8 Hvilken model beskriver bedst sammenhængen i data? Modellerne beskriver data lige godt, men jeg vælger log-transformationen fordi jeg hermed undgår at enkelte højt eksponerede børn får meget stor indflydelse.

9 Fortolkning af regressionskoefficienten β Model: bostot = α + β log 10 (B-Hg) + ǫ where ǫ N(0, σ 2 ). β: ændring i respons når log 10 (B-Hg) vokser med 1. log 10 (B-Hg 1 ) log 10 (B-Hg 0 ) = log 10 ( B-Hg 1 B-Hg 0 ) = 1 B-Hg 1 B-Hg 0 = 10 1 = 10 β: ændring i respons når koncentrationen B-Hg 10-dobles
 log 10 (B-Hg 0 ) = log 10 ( B-Hg 1 B-Hg 0 ) = 1 B-Hg 1")
10 h <- lm(bostot ~ logbhg,hg1) summary(h) Regressionsanalyse i R Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) < 2e-16 *** logbhg e-07 *** Residual standard error: on 847 degrees of freedom (68 observations deleted due to missingness) Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 847 DF, p-value: 6.608e-07 Fortolkning af resultat: når logbhg vokser med 1 falder Boston Naming scoren med Eller mere relevant: Når B-Hg 10-dobles falder Boston Naming scoren med Effekten er stærkt signifikant (p<0.05).

11 Confounding Hg-eksponering Morens intelligens 1. intelligente mødre får intelligente børn Barnets score 2. børn med intelligente mødre har lavere Hg-eksponering I simpel lineær regression ignorerer vi confounderen maternel intelligens og over-estimerer Hg s skadelige effekt. Højt eksponerede børn klarer sig dårligt også fordi deres mødre er mindre intelligente. Ideelt, ville vi sammenligne børn med forskellig grad af eksponering, men med samme værdi af maternel intelligens.

12 Multipel regression analyse MEGET nyttig modelklasse som tillader at responsen kan afhænge af mere end en kovariat. Kovariaterne: kontinuerte eller gruppe-variable Responsen: skal være kontinuert. Næste gang: logistisk regression hvor responsen er 0/1.

13 Multipel regression analyse, II DATA: n individer, p forklarende variable + en respons: subject x 1...x p y 1 x 11...x 1p y 1 2 x 21...x 2p y 2 3 x 31...x 3p y n x n1...x np y n Den multiple lineære regressions model med p kovariater: y i = β 0 + β 1 x i1 + + β p x ip + ε i respons middelværdi funktion biologisk variation Parametre β 0 β 1,, β p intercept regressionskoefficienter

14 Multipel regression, 2 kontinuerte kovariater y i = β 0 + β 1 x i1 + β p x i2 + ε i, i = 1,, n Antagelse: ε i N(0, σ 2 ), uafhængige Estimation: Hvilket plan i rummet ligger tættest på data?

15 Fortolkning af regressionskoefficienterne β Model Y i = β 0 + β 1 X i1 + β 2 X i2 + ǫ hvor ǫ N(0, σ 2 ) Eks. Y: blodtryk X 1 : alder X 2 : vægt Betragt to individer: A har kovariatværdier (35,75); B har kovariatværdier (36,75) Forventet forskel i blodtryk (B A) β 0 + β β 2 75 [β 0 + β β 2 75] = β 1 β 1 : ændring i blodtryk når X 1 forøges med en enhed og de andre kovariater holdes uændret Bemærk, at effekten ikke afhænger af udgangspunktet for X 1 (her 35). Uanset hvor vi starter, er effekten af en forøgelse på en enhed den samme. Sammenhængen er lineær. Bemærk også, at effekten ikke afhænger af niveauet af X 2 (her 75). Effekten af en ændring i X 1 på en enhed er den samme for alle værdier af X 2. Dette kan ændres med et vekselvirkningsled.
![β 2 75] = β 1 β 1 : ændring i blodtryk når X 1 forøges med en enhed og de andre kovariater holdes uændret Bemærk, at effekten ikke afhænger af udgangspunktet for X 1 (her 35).](/docs-images/50/18390898/images/page_15.jpg "Uanset hvor vi starter, er effekten af en forøgelse på en enhed den samme. Sammenhængen er lineær. Bemærk også, at effekten ikke afhænger af niveauet af X 2 (her 75).")
16 Fortolkning af regression koefficienterne: Hg-effekten Simpel regression: Y = α + β log 10 (B-Hg) + ǫ β: forventet forskel i neuro-score mellem to børn med en forskel i log 10 (B-Hg) på en, dvs hvor det en barn har en Hg-koncentration der er 10 gange større Multipel regression: Y = α + β log 10 (B-Hg) + β 1 X β p X p + ǫ β: forventet forskel i neuro-score mellem to børn med en forskel i log 10 (B-Hg) på en, men som er ens på de øvrige kovariater (køn, maternel intelligens,...) Vi har justeret for effekten af de andre kovariater. Det er vigtigt at justere for variable der er associeret med både eksponering og respons.
 Vi har justeret for effekten af de andre kovariater. Det er vigtigt at justere for variable der er associeret med både eksponering og respons.")
17 Multipel regression i R > h <- lm(bostot ~ logbhg+ kon + age+ risk+ childcar+ mattrain+ pattrain+ + patempl +raven+town71,hg1) Det kunne ikke være lettere: kovariaterne skrives på højre-siden med plusser imellem.

18 R-output - Boston Naming Test > summary(h) Call: lm(formula = bostot ~ logbhg + kon + age + risk + childcar + mattrain + pattrain + patempl + raven + town71, data = hg1) Residuals: Min 1Q Median 3Q Max

19 Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) logbhg *** kon * age e-14 *** risk *** childcar e-05 *** mattrain * pattrain * patempl raven *** town * Residual standard error: on 780 degrees of freedom (126 observations deleted due to missingness) Multiple R-squared: , Adjusted R-squared: F-statistic: on 10 and 780 DF, p-value: < 2.2e-16
 Multiple R-squared: 0.2112, Adjusted R-squared: 0.")
20 Var Hg-effekten virkelig signifikant? Eksponeringer blev grupperet og gennemsnittet af bostot beregnet i hver gruppe

21 > h <- lm(digwf ~ logbhg,hg1) > summary(h) Samme analyse - Digit Spans (digwf) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) <2e-16 *** logbhg * Også her ses en signifikant skadelig Hg-effekt
22 > h <- lm(digwf ~ logbhg+ kon + age+ risk+ childcar+ mattrain+ pattrain+ + patempl +raven+town71,hg1) > summary(h) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) logbhg kon e-05 *** age * risk childcar mattrain pattrain patempl raven ** town Efter korrektion forsvinder effekten
23 Prædiktion Estimeret model: bostot = log 10 (B-Hg) i 0.70 SEX i TOWN7 i +ǫ, ǫ N(0,4.9 2 ) Forventet respons for det første barn i data: bostot = log 10 (92.2) = 27.8 Observert bostot=21, Residual ǫ 1 = = 6.8 Prædiktionsusikkerhed: 95% prædiktionsinterval: forventet værdi ± = (18.2; 37.4) (her har vi ignoreret estimationsusikkerheden i regressionskoefficienterne)
24 Håndtering af gruppe-variable - brug factor > h <- lm(bostot ~ factor(grind),hg1) > summary(h) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) < 2e-16 *** factor(grind) * factor(grind) ** factor(grind) factor(grind) e-05 *** factor(grind) factor(grind) factor(grind) * factor(grind) Residual standard error: on 859 degrees of freedom (49 observations deleted due to missingness) Multiple R-squared: , Adjusted R-squared: F-statistic: on 8 and 859 DF, p-value:
25 Illustration af model med factor
26 Uden factor > h <- lm(bostot ~ grind,hg1) > summary(h) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) < 2e-16 *** grind e-05 *** Residual standard error: on 866 degrees of freedom (49 observations deleted due to missingness) Multiple R-squared: , Adjusted R-squared: F-statistic: 15.6 on 1 and 866 DF, p-value: 8.461e-05
27 Illustration: factor eller ej
28 Forskel på lungekapacitet i mænd og kvinder 32 patienter skal have foretaget hjerte/lunge transplantation tlc (Total Lung Capacity) bestemmes ved hjælp af helkrops plethysmografi Er der forskel på mænd og kvinder? sex age height tlc
29 Box plots total lung capacity female male height female male
30 > h <- lm(tlc ~ factor(sex),bone) > summary(h) Ujusteret sammenligning (t-test) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) e-15 *** factor(sex) *** Residual standard error: on 30 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 30 DF, p-value:
31 > h <- lm(height ~ factor(sex),bone) > summary(h) Mænd og kvinder er ikke lige høje Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) < 2e-16 *** factor(sex) *** Residual standard error: on 30 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 30 DF, p-value:
32 Relation mellem tlc og height Højden er relateret til tlc og er derfor en confounder.
33 Model med både sex og height som kovariater MODEL: Y gi = α g + βx gi + ǫ gi g = 1,2; i = 1,..., n g Modellen tillader at responsen kan afhænge af både højde og køn. Modellen angiver altså to parallelle linjer (kovariansanalyse). Forskellen α 1 α 2 angiver forskellen i tlc mellem kvinder og mænd med samme højde (x).
34 Analyse i R > h <- lm(tlc ~ factor(sex)+height,bone) > summary(h) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) * factor(sex) height ** Efter korrektion for højde ligger mænd stadig over kvinder, men forskellen er ikke statistisk signifikant.
35 Hvem siger, at linjerne skal være parallelle? Vekselvirkning Mere generel model: y gi = α g + β g x gi + ǫ gi g = 1,2; i = 1,..., n g Når β 1 β 2, siger vi, at der er vekselvirkning, eller interaktion. Det betyder: Effekten af højde afhænger af kønnet Forskellen på kønnene afhænger af højden I tilfælde af vekselvirkning kan man altså ikke udtale sig om en generel effekt af højde eller om en generel kønsforskel. Ulla talte om vekselvirning i 2-sidet variansanalyse.
36 Vekselvirkning i R To mulighder >h <- lm(tlc ~ factor(sex)+height+factor(sex):height,bone) Vekselvirkningen modelleres altså ved at inddrage factor(sex):height > h <- lm(tlc ~ factor(sex)*height,bone) Vekselvirkningen modelleres altså ved at ersatte + med *
37 Vekselvirning - output > summary(h) Call: lm(formula = tlc ~ factor(sex) * height, data = bone) Residuals: Min 1Q Median 3Q Max Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) factor(sex) height * factor(sex)2:height Residual standard error: on 28 degrees of freedom Multiple R-squared: 0.524, Adjusted R-squared: F-statistic: on 3 and 28 DF, p-value: 9.896e-05
38 Hvor er de to linjer i outputtet? Som sædvanlig vælger R en reference gruppe (her sex=1, kvinder); for den gruppe kan linjen direkte aflæses tlc = height der ses altså en positiv effekt af højde. Intercept og hældning for den anden gruppe (mænd) er angivet som forskelle til referencegruppen tlc = ( ) + ( ) height så her er effekten af højde mindre, men forskellen (0.006) ikke er statistisk signifikant (p=0.895) - hvilket betyder at effekten af højde kan antages at være ens i de to grupper - vekselvirkningen er ikke statistisk signifikant.
39 Scatterplot i R bone$tlc female male bone$height
40 R-kode til scatterplotet plot(bone$height,bone$tlc,pch=bone$sex) legend(locator(n=1),legend=c("female","male"),pch=1:2) female<-bone[bone$sex==1,] male<-bone[bone$sex==2,] f<-lm(tlc ~ height,female) m<-lm(tlc ~ height,male) abline(f) abline(m)
41 Mulige modeller
42 Om vekselvirkninger Involverer mindst 3 variable: effekten af x 1 på y afhænger af x 2 Ofte medtages disse led kun som modelkontrol: de testes og fjernes igen hvis de er insignifikante Råd til den uerfarne: medtag ikke for mange vekselvirkningsled. Start evt. med at lave en analyse uden vekselvirkning. Angiv og fortolk resultat. Herefter udvides modellen med relevante vekselvirkninger.
43 Færøske data: Afhænger Hg-effekten af PCB-niveauet? Fra tekst: The p-value for no effect modification was between 0.21 and 0.75, thus suggesting that no interaction occured. EBJ et al., Environmental health perspectives, 1999.
44 Illustration
45 Begrænsninger i multipel regression - kollinearitet Eks. O Neill et.al. (1983): Lungefunktion i 25 patienter med systisk fribrose
46 Hvilke forklarende variable har en marginal effekt på PE max? Nogle af disse effekter kan være artefakter opstået ved confounding. De kausale variable findes i en multipel model med alle kovariater
47 Model med alle kovariater lm(pemax~age+sex+height+weight+bmp+fev1+rv+frc+tlc,pemax) Parameter Standard Variable Estimate Error t Value Pr > t Intercept age sex height weight bmp fev rv frc tlc
48 Korrelerede kovariater Univariate analyser viste stærke effekter En multipel analyse fandt ingen effekter Hvordan kan det ske i de samme data? Når vi inkludere mange korrelerede kovariater i samme model, så falder styrken til at detektere effekter. For eksempel, vil der være begrænset information i data om effekten af en ændring i højde for fastholdt værdi af vægt, fordi når højden ændres vil vægten også have en tendens til at ændres. Højt korrelerede kovariater bør undgås. Dette fænomen kaldes kollinearitet
49 Illustration
50 Kollinearitet To eller flere kovariater er stærkt associeret. Konsekvenser: Nogle koefficienter har store standard errors R 2 er høj, men ingen af kovariaterne er signifikante Resultatet er ikke som forventet Resultatet ændres meget når en kovariat udelades Dårligt studie design. Nogle gange uundgåeligt.
51 Automatisk model-selektion Backward elimination start med at inkludere alle kovariaters, fjern kovariaten med den højeste p-værdi fit modellen igen fortsæt indtil alle variable er signifikante I eksemplet vælges: weight, bmp og fev1. Advarsel: Outputtet fra den valgte model tager ikke højde for modelusikkerheden. Effekten af de valgte kovariater overvurderes. Sådanne metoder bruges for ofte. F.eks ikke optimale til identifikation af confoundere (EBJ, 2007). Kan bruges til bestemmelse af en simpel model til prædiktion. Budtz-Jørgensen, E., Keiding, N., Grandjean, P., Weihe, P. Confounder Selection in Environmental Epidemiology: Assessment of Health Effects of Prenatal Mercury Exposure. Annals of Epidemiology 17, 27-35, 2007.
52 PCB-korrektion PCB koncentration målt i navlestreng men kun i halvdelen af børnene. (Median koncentration 2 ng/g). Hg and PCB er korrelerede: corr[log 10 (B-Hg), log 10 (PCB)] = 0.40, p < Respons: bostot Cord Blood Hg PCB β s.e. p β s.e. p Baseret på de separate analyser har begge variable en effekt. Hvis begge variable er inkluderet i samme model har ingen af variablene en effekt. Konklusion: mindst en af disse variable har en effekt, men det er svært at afgøre hvilken af dem det er. Dog ser det ud til at være Hg. I en backward eliminations procedure ville PCB blive udeladt. Det endelige resultat ville være givet ved 1. række.
53 Modelkontrol Model Y i = β 0 + β 1 X i1 + β 2 X i β p X ip + ǫ where ǫ N(0, σ 2 ). Hvilke antagelser skal vi checke? linearitet varianshomogenitet i residualer normalfodelte residualer Bemærk: ingen krav om normalfordeling på kovariaterne
54 Residual plots Fittede værdier Ŷi = β 0 + β 1 X i1 + β 2 X i β p X ip Residual ǫ i = Y i Ŷi Standardiserede residualer: standardiseret så variansen er 1 Plots (som for simpel lineær regression) : residualer vs kovariater: tester linearitet residualer vs fittede værdier: for at teste varianshomogenitet. En trompet-form indikerer en log-transformation [var{log(y )} var(y )/Y 2 ] Skal ikke vise nogen struktur
55 Boston Naming Test: Standardiseret residual vs fittet værdi
56 Boston Naming Test: Standardiseret residual vs Hg-koncentration
57 Test af linearitet: Polynomial regression Y = β 0 + β 1 x + β 2 x 2 + β 3 x 3 + ǫ Bemærk: relationen mellem X og Y er ikke lineær, men modellen er en multipel lineær regressionsmodel (Y er lineær i β-erne) Modellen kan fittes med lm. Man skal bare lave kovariaterne x 2, x 3. Test of linearitet: H 0 : β 2 = β 3 = 0 The model is tested against a more general (flexible) model. Modellen der antager en lineær sammenhæng mellem X og Y testes mod en mere generel model.
58 Test af linearitet Sammenhæng: prænatal Hg-eksponering og blodtryk Systolisk blodtryk (mmhg) regressers på barnets vægt (kg) og prænatal Hg-eksponering T for H0: Pr > T Std Error of Parameter Estimate Parameter=0 Estimate INTERCEPT WEIGHT LOGBHG Hg-effekt er klart insignifikant
59 Inklusion af led af højere orden h1 <- lm(bp1 ~ weight+logbhg+i(logbhg^2)+i(logbhg^3),hgbp) summary(h1) Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) < 2e-16 *** weight e-15 *** logbhg e-05 *** I(logbhg^2) *** I(logbhg^3) ** 2. og 3. gradsleddet er signifikante. Sammenhæng mellem bp1 og logbhg kan ikke antages at være lineær. Resultatet af den foregående analyse er derfor ugyldigt. Undersøg om problemet skyldes et enelte outliers. Lav en tegning af den estimerede relation: Beregn y = 34.2 logbhg 23.7 logbhg logbhg 3 for hver person og plot y som en funktion of logbhg
60 Estimated dose-response function
61 Test for ingen Hg-effekt: anova h1 <- lm(bp1 ~ weight+logbhg+i(logbhg^2)+i(logbhg^3),hgbp) h2 <- lm(bp1 ~ weight,hgbp) anova(h2,h1) Model 1: bp1 ~ weight Model 2: bp1 ~ weight + logbhg + I(logbhg^2) + I(logbhg^3) Res.Df RSS Df Sum of Sq F Pr(>F) e-05 *** Bemærk: anova kan bruges til at teste flere kovariater væk på en gang. Her forkastets testet: Hg effekten er statistisk signifikant
62 Indflydelsesrige observationer Leverage i : måler hvor ekstremt kovariatværdierne for den i te observation er. (One covariate: h ii = 1/n + (x i x) 2 /Σ j (x j x) 2 ) Cooks D i : måler hvor meget all regresionskoefficenterne ændres hvis i te observation udelades dfbeta i : måler hvor meget en specifik regresionskoefficent ændres hvis i te observation udelades dfbeta i = [ β β (i) ]/s.e.( β) β (i) : coefficient without i th observation
63 Hvornår skal man transformere sine kovariater? Når relationen melle x and y ikke er lineær: transformer x (or y) Hvorfor blev B-Hg log-transformet når log-modellen ikke fitter meget bedre end den lineære model?
64 Leverage
65 dfbeta
66 Sammenfatning multipel regression: flere kovariater påvirker en kontinuert respons herved korrigeres for confounding specialtilfælde: t-test, ANOVA, simpel regression kollinearitet: kovariater er korrelerede styrken går ned vekselvirkning: en kovariats effekt på responsen afhænger at niveauet af en anden kovariat fint nok, men min respons er 0/1: så skal du bruge multipel logistisk regression. Susanne R næste gang.
Reminder: Hypotesetest for én parameter. Økonometri: Lektion 4. F -test Justeret R 2 Aymptotiske resultater. En god model
 Reminder: Hypotesetest for én parameter Antag vi har model Økonometri: Lektion 4 F -test Justeret R 2 Aymptotiske resultater y = β 0 + β 1 x 2 + β 2 x 2 + + β k x k + u. Vi ønsker at teste hypotesen H
Reminder: Hypotesetest for én parameter Antag vi har model Økonometri: Lektion 4 F -test Justeret R 2 Aymptotiske resultater y = β 0 + β 1 x 2 + β 2 x 2 + + β k x k + u. Vi ønsker at teste hypotesen H
Løsning til øvelsesopgaver dag 4 spg 5-9
 Løsning til øvelsesopgaver dag 4 spg 5-9 5: Den multiple model Vi tilføjer nu yderligere to variable til vores model : Køn og kolesterol SBP = a + b*age + c*chol + d*mand hvor mand er 1 for mænd, 0 for
Løsning til øvelsesopgaver dag 4 spg 5-9 5: Den multiple model Vi tilføjer nu yderligere to variable til vores model : Køn og kolesterol SBP = a + b*age + c*chol + d*mand hvor mand er 1 for mænd, 0 for
Program. Modelkontrol og prædiktion. Multiple sammenligninger. Opgave 5.2: fosforkoncentration
 Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: [email protected] Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
Faculty of Life Sciences Program Modelkontrol og prædiktion Claus Ekstrøm E-mail: [email protected] Test af hypotese i ensidet variansanalyse F -tests og F -fordelingen. Multiple sammenligninger. Bonferroni-korrektion
Statistik Lektion 17 Multipel Lineær Regression
 Statistik Lektion 7 Multipel Lineær Regression Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test Multipel lineær regression x,x,,x
Statistik Lektion 7 Multipel Lineær Regression Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test Multipel lineær regression x,x,,x
Økonometri: Lektion 5. Multipel Lineær Regression: Interaktion, log-transformerede data, kategoriske forklarende variable, modelkontrol
 Økonometri: Lektion 5 Multipel Lineær Regression: Interaktion, log-transformerede data, kategoriske forklarende variable, modelkontrol 1 / 35 Veksekvirkning: Motivation Vi har set på modeller som Price
Økonometri: Lektion 5 Multipel Lineær Regression: Interaktion, log-transformerede data, kategoriske forklarende variable, modelkontrol 1 / 35 Veksekvirkning: Motivation Vi har set på modeller som Price
Normalfordelingen. Statistik og Sandsynlighedsregning 2
 Normalfordelingen Statistik og Sandsynlighedsregning 2 Repetition og eksamen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige fejl på
Normalfordelingen Statistik og Sandsynlighedsregning 2 Repetition og eksamen Erfaringsmæssigt er normalfordelingen velegnet til at beskrive variationen i mange variable, blandt andet tilfældige fejl på
Generelle lineære modeller
 Generelle lineære modeller Regressionsmodeller med én uafhængig intervalskala variabel: Y en eller flere uafhængige variable: X 1,..,X k Den betingede fordeling af Y givet X 1,..,X k antages at være normal
Generelle lineære modeller Regressionsmodeller med én uafhængig intervalskala variabel: Y en eller flere uafhængige variable: X 1,..,X k Den betingede fordeling af Y givet X 1,..,X k antages at være normal
Statistik og Sandsynlighedsregning 2. IH kapitel 12. Overheads til forelæsninger, mandag 6. uge
 Statistik og Sandsynlighedsregning 2 IH kapitel 12 Overheads til forelæsninger, mandag 6. uge 1 Fordelingen af én (1): Regressionsanalyse udfaldsvariabel responsvariabel afhængig variabel Y variabel 2
Statistik og Sandsynlighedsregning 2 IH kapitel 12 Overheads til forelæsninger, mandag 6. uge 1 Fordelingen af én (1): Regressionsanalyse udfaldsvariabel responsvariabel afhængig variabel Y variabel 2
Besvarelse af juul2 -opgaven
 Besvarelse af juul2 -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Lav regressionsanalyser for hvert køn af igf1 vs. alder for præpubertale (Tanner stadium
Besvarelse af juul2 -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Lav regressionsanalyser for hvert køn af igf1 vs. alder for præpubertale (Tanner stadium
Multipel regression. M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model
 M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model") Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
Multipel regression M variable En afhængig (Y) M-1 m uafhængige / forklarende / prædikterende (X 1 til X m ) Model Y j 1 X 1j 2 X 2j... m X mj j eller m Y j 0 i 1 i X ij j BEMÆRK! j svarer til individ
Lineær regression. Simpel regression. Model. ofte bruges følgende notation:
 Lineær regression Simpel regression Model Y i X i i ofte bruges følgende notation: Y i 0 1 X 1i i n i 1 i 0 Findes der en linie, der passer bedst? Metode - Generel! least squares (mindste kvadrater) til
Lineær regression Simpel regression Model Y i X i i ofte bruges følgende notation: Y i 0 1 X 1i i n i 1 i 0 Findes der en linie, der passer bedst? Metode - Generel! least squares (mindste kvadrater) til
Multipel Lineær Regression. Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test
 Multipel Lineær Regression Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test Multipel lineær regression x,x,,x k uafhængige variable
Multipel Lineær Regression Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test Multipel lineær regression x,x,,x k uafhængige variable
Appendiks Økonometrisk teori... II
 Appendiks Økonometrisk teori... II De klassiske SLR-antagelser... II Hypotesetest... VII Regressioner... VIII Inflation:... VIII Test for SLR antagelser... IX Reset-test... IX Plots... X Breusch-Pagan
Appendiks Økonometrisk teori... II De klassiske SLR-antagelser... II Hypotesetest... VII Regressioner... VIII Inflation:... VIII Test for SLR antagelser... IX Reset-test... IX Plots... X Breusch-Pagan
Basal statistik. Logaritmer og kovariansanalyse. Nyt eksempel vedr. sammenligning af målemetoder. Scatter plot af de to metoder
 Faculty of Health Sciences Logaritmer og kovariansanalyse Basal statistik Logaritmer. Kovariansanalyse Lene Theil Skovgaard 29. september 2015 Parret sammenligning, målemetoder med logaritmer Tosidet variansanalyse
Faculty of Health Sciences Logaritmer og kovariansanalyse Basal statistik Logaritmer. Kovariansanalyse Lene Theil Skovgaard 29. september 2015 Parret sammenligning, målemetoder med logaritmer Tosidet variansanalyse
Faculty of Health Sciences. Basal statistik. Logaritmer. Kovariansanalyse. Lene Theil Skovgaard. 29. september 2015
 Faculty of Health Sciences Basal statistik Logaritmer. Kovariansanalyse Lene Theil Skovgaard 29. september 2015 1 / 84 Logaritmer og kovariansanalyse Parret sammenligning, målemetoder med logaritmer Tosidet
Faculty of Health Sciences Basal statistik Logaritmer. Kovariansanalyse Lene Theil Skovgaard 29. september 2015 1 / 84 Logaritmer og kovariansanalyse Parret sammenligning, målemetoder med logaritmer Tosidet
Besvarelse af vitcap -opgaven
 Besvarelse af -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Beskriv fordelingen af vital capacity og i de 3 grupper ved hjælp af summary statistics.
Besvarelse af -opgaven Spørgsmål 1 Indlæs data Dette gøres fra Analyst med File/Open, som sædvanlig. Spørgsmål 2 Beskriv fordelingen af vital capacity og i de 3 grupper ved hjælp af summary statistics.
Lineær og logistisk regression
 Faculty of Health Sciences Lineær og logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Dagens program Lineær regression
Faculty of Health Sciences Lineær og logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Dagens program Lineær regression
Epidemiologi og biostatistik. Uge 3, torsdag. Erik Parner, Institut for Biostatistik. Regressionsanalyse
 Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Institut for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression Regressionsanalyse Regressionsanalyser
Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Institut for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression Regressionsanalyse Regressionsanalyser
12. september Epidemiologi og biostatistik. Forelæsning 4 Uge 3, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Regressionsanalyse
 . september 5 Epidemiologi og biostatistik. Forelæsning Uge, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression
. september 5 Epidemiologi og biostatistik. Forelæsning Uge, torsdag. Niels Trolle Andersen, Afdelingen for Biostatistik. Lineær regressionsanalyse - Simpel lineær regression - Multipel lineær regression
Opgavebesvarelse, brain weight
 Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) For 20 nyfødte mus er der i tabellen nedenfor anført oplysning om kuldstørrelsen (fra 3 til 12
Opgavebesvarelse, brain weight (Matthews & Farewell: Using and Understanding Medical Statistics, 2nd. ed.) For 20 nyfødte mus er der i tabellen nedenfor anført oplysning om kuldstørrelsen (fra 3 til 12
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006
 PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006 I dag: To stikprøver fra en normalfordeling, ikke-parametriske metoder og beregning af stikprøvestørrelse Eksempel: Fiskeolie
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 2, onsdag den 13. september 2006 I dag: To stikprøver fra en normalfordeling, ikke-parametriske metoder og beregning af stikprøvestørrelse Eksempel: Fiskeolie
Anvendt Statistik Lektion 9. Variansanalyse (ANOVA)
") Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
To-sidet variansanalyse
 Program 1. To-sidet variansanalyse 2. Hierarkisk princip 3. Tre (og flere) sidet variansanalyse 4. Variansanalyse med blocking 5. Flersidet variansanalyse med tilfældige faktorer 6. En oversigtsslide til
Program 1. To-sidet variansanalyse 2. Hierarkisk princip 3. Tre (og flere) sidet variansanalyse 4. Variansanalyse med blocking 5. Flersidet variansanalyse med tilfældige faktorer 6. En oversigtsslide til
Epidemiologi og biostatistik. Uge 3, torsdag. Erik Parner, Afdeling for Biostatistik. Eksempel: Systolisk blodtryk
 Eksempel: Systolisk blodtryk Udgangspunkt: Vi ønsker at prædiktere det systoliske blodtryk hos en gruppe af personer. Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Afdeling for Biostatistik.
Eksempel: Systolisk blodtryk Udgangspunkt: Vi ønsker at prædiktere det systoliske blodtryk hos en gruppe af personer. Epidemiologi og biostatistik. Uge, torsdag. Erik Parner, Afdeling for Biostatistik.
Anvendt Statistik Lektion 9. Variansanalyse (ANOVA)
") Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Anvendt Statistik Lektion 9 Variansanalyse (ANOVA) 1 Undersøge sammenhæng Undersøge sammenhænge mellem kategoriske variable: χ 2 -test i kontingenstabeller Undersøge sammenhæng mellem kontinuerte variable:
Eksamen Bacheloruddannelsen i Medicin med industriel specialisering
 Eksamen 2016 Titel på kursus: Uddannelse: Semester: Forsøgsdesign og metoder Bacheloruddannelsen i Medicin med industriel specialisering 6. semester Eksamensdato: 17-02-2015 Tid: kl. 09.00-11.00 Bedømmelsesform
Eksamen 2016 Titel på kursus: Uddannelse: Semester: Forsøgsdesign og metoder Bacheloruddannelsen i Medicin med industriel specialisering 6. semester Eksamensdato: 17-02-2015 Tid: kl. 09.00-11.00 Bedømmelsesform
Module 12: Mere om variansanalyse
 Mathematical Statistics ST06: Linear Models Bent Jørgensen og Pia Larsen Module 2: Mere om variansanalyse 2. Parreded observationer................................ 2.2 Faktor med 2 niveauer (0- variabel)........................
Mathematical Statistics ST06: Linear Models Bent Jørgensen og Pia Larsen Module 2: Mere om variansanalyse 2. Parreded observationer................................ 2.2 Faktor med 2 niveauer (0- variabel)........................
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab. Eksamensopgave E05. Socialklasse og kronisk sygdom
 Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Eksamensopgave E05 Socialklasse og kronisk sygdom Data: Tværsnitsundersøgelse fra 1986 Datamaterialet indeholder: Køn, alder, Højest opnåede
Statistik ved Bachelor-uddannelsen i folkesundhedsvidenskab Eksamensopgave E05 Socialklasse og kronisk sygdom Data: Tværsnitsundersøgelse fra 1986 Datamaterialet indeholder: Køn, alder, Højest opnåede
Modul 11: Simpel lineær regression
 Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen Modul 11: Simpel lineær regression 11.1 Regression uden gentagelser............................. 1 11.1.1 Oversigt....................................
Forskningsenheden for Statistik ST01: Elementær Statistik Bent Jørgensen Modul 11: Simpel lineær regression 11.1 Regression uden gentagelser............................. 1 11.1.1 Oversigt....................................
Logistisk regression. Basal Statistik for medicinske PhD-studerende November 2008
 Logistisk regression Basal Statistik for medicinske PhD-studerende November 2008 Bendix Carstensen Steno Diabetes Center, Gentofte & Biostatististisk afdeling, Københavns Universitet [email protected] www.biostat.ku.dk/~bxc
Logistisk regression Basal Statistik for medicinske PhD-studerende November 2008 Bendix Carstensen Steno Diabetes Center, Gentofte & Biostatististisk afdeling, Københavns Universitet [email protected] www.biostat.ku.dk/~bxc
Faculty of Health Sciences. Basal Statistik. Logistisk regression mm. Lene Theil Skovgaard. 5. marts 2018
 Faculty of Health Sciences Basal Statistik Logistisk regression mm. Lene Theil Skovgaard 5. marts 2018 1 / 22 APPENDIX vedr. SPSS svarende til diverse slides: To-gange-to tabeller, s. 3 Plot af binære
Faculty of Health Sciences Basal Statistik Logistisk regression mm. Lene Theil Skovgaard 5. marts 2018 1 / 22 APPENDIX vedr. SPSS svarende til diverse slides: To-gange-to tabeller, s. 3 Plot af binære
Multipel Linear Regression. Repetition Partiel F-test Modelsøgning Logistisk Regression
 Multipel Linear Regression Repetition Partiel F-test Modelsøgning Logistisk Regression Test for en eller alle parametre I jagten på en god statistisk model har vi set på følgende to hypoteser og tilhørende
Multipel Linear Regression Repetition Partiel F-test Modelsøgning Logistisk Regression Test for en eller alle parametre I jagten på en god statistisk model har vi set på følgende to hypoteser og tilhørende
Logistisk regression
 Logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Kursushjemmeside: www.biostat.ku.dk/~sr/forskningsaar/regression2012/
Logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Kursushjemmeside: www.biostat.ku.dk/~sr/forskningsaar/regression2012/
9. Chi-i-anden test, case-control data, logistisk regression.
 Biostatistik - Cand.Scient.San. 2. semester Karl Bang Christensen Biostatististisk afdeling, KU [email protected], 35327491 9. Chi-i-anden test, case-control data, logistisk regression. http://biostat.ku.dk/~kach/css2014/
Biostatistik - Cand.Scient.San. 2. semester Karl Bang Christensen Biostatististisk afdeling, KU [email protected], 35327491 9. Chi-i-anden test, case-control data, logistisk regression. http://biostat.ku.dk/~kach/css2014/
Program. Simpel og multipel lineær regression. I tirsdags: model og estimation. I tirsdags: Prædikterede værdier og residualer
 Program Simpel og multipel lineær regression Helle Sørensen E-mail: [email protected] Simpel LR: repetition, konfidensintervaller, test, prædiktionsintervaller, mm. Multipel LR: estimation, valg af model,
Program Simpel og multipel lineær regression Helle Sørensen E-mail: [email protected] Simpel LR: repetition, konfidensintervaller, test, prædiktionsintervaller, mm. Multipel LR: estimation, valg af model,
Oversigt. 1 Gennemgående eksempel: Højde og vægt. 2 Korrelation. 3 Regressionsanalyse (kap 11) 4 Mindste kvadraters metode
 4 Mindste kvadraters metode") Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Oversigt 1 Gennemgående eksempel: Højde og vægt 2 Korrelation 3 Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse
Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Oversigt 1 Gennemgående eksempel: Højde og vægt 2 Korrelation 3 Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse
Faculty of Health Sciences. Basal Statistik. Multipel regressionsanalyse i R. Lene Theil Skovgaard. 11. marts 2019
 Faculty of Health Sciences Basal Statistik Multipel regressionsanalyse i R. Lene Theil Skovgaard 11. marts 2019 1 / 86 Multipel lineær regression Regression med to kvantitative kovariater: Eksempel om
Faculty of Health Sciences Basal Statistik Multipel regressionsanalyse i R. Lene Theil Skovgaard 11. marts 2019 1 / 86 Multipel lineær regression Regression med to kvantitative kovariater: Eksempel om
Lineær regression i SAS. Lineær regression i SAS p.1/20
 Lineær regression i SAS Lineær regression i SAS p.1/20 Lineær regression i SAS Simpel lineær regression Grafisk modelkontrol Multipel lineær regression SAS-procedurer: PROC REG PROC GPLOT Lineær regression
Lineær regression i SAS Lineær regression i SAS p.1/20 Lineær regression i SAS Simpel lineær regression Grafisk modelkontrol Multipel lineær regression SAS-procedurer: PROC REG PROC GPLOT Lineær regression
Økonometri: Lektion 6 Emne: Heteroskedasticitet
 Økonometri: Lektion 6 Emne: Heteroskedasticitet 1 / 32 Konsekvenser af Heteroskedasticitet Antag her (og i resten) at MLR.1 til MLR.4 er opfyldt. Antag MLR.5 ikke er opfyldt, dvs. vi har heteroskedastiske
Økonometri: Lektion 6 Emne: Heteroskedasticitet 1 / 32 Konsekvenser af Heteroskedasticitet Antag her (og i resten) at MLR.1 til MLR.4 er opfyldt. Antag MLR.5 ikke er opfyldt, dvs. vi har heteroskedastiske
Multipel Lineær Regression
 Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk model Specificer
Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk model Specificer
Forelæsning 11: Kapitel 11: Regressionsanalyse
 Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks Tekniske Universitet 2800
Kursus 02402 Introduktion til Statistik Forelæsning 11: Kapitel 11: Regressionsanalyse Per Bruun Brockhoff DTU Compute, Statistik og Dataanalyse Bygning 324, Rum 220 Danmarks Tekniske Universitet 2800
Basal statistik. 30. januar 2007
 Basal statistik 30. januar 2007 Deskriptiv statistik Typer af data Tabeller Grafik Summary statistics Lene Theil Skovgaard, Biostatistisk Afdeling Institut for Folkesundhedsvidenskab, Københavns Universitet
Basal statistik 30. januar 2007 Deskriptiv statistik Typer af data Tabeller Grafik Summary statistics Lene Theil Skovgaard, Biostatistisk Afdeling Institut for Folkesundhedsvidenskab, Københavns Universitet
men nu er Z N((µ 1 µ 0 ) n/σ, 1)!! Forkaster hvis X 191 eller X 209 eller
 n/σ, 1)!! Forkaster hvis X 191 eller X 209 eller") Type I og type II fejl Type I fejl: forkast når hypotese sand. α = signifikansniveau= P(type I fejl) Program (8.15-10): Hvis vi forkaster når Z < 2.58 eller Z > 2.58 er α = P(Z < 2.58) + P(Z > 2.58) =
Type I og type II fejl Type I fejl: forkast når hypotese sand. α = signifikansniveau= P(type I fejl) Program (8.15-10): Hvis vi forkaster når Z < 2.58 eller Z > 2.58 er α = P(Z < 2.58) + P(Z > 2.58) =
Økonometri: Lektion 4. Multipel Lineær Regression: F -test, justeret R 2 og aymptotiske resultater
 Økonometri: Lektion 4 Multipel Lineær Regression: F -test, justeret R 2 og aymptotiske resultater 1 / 35 Hypotesetest for én parameter Antag vi har model y = β 0 + β 1 x 2 + β 2 x 2 + + β k x k + u. Vi
Økonometri: Lektion 4 Multipel Lineær Regression: F -test, justeret R 2 og aymptotiske resultater 1 / 35 Hypotesetest for én parameter Antag vi har model y = β 0 + β 1 x 2 + β 2 x 2 + + β k x k + u. Vi
Økonometri Lektion 1 Simpel Lineær Regression 1/31
 Økonometri Lektion 1 Simpel Lineær Regression 1/31 Simpel Lineær Regression Mål: Forklare variablen y vha. variablen x. Fx forklare Salg (y) vha. Reklamebudget (x). Statistisk model: Vi antager at sammenhængen
Økonometri Lektion 1 Simpel Lineær Regression 1/31 Simpel Lineær Regression Mål: Forklare variablen y vha. variablen x. Fx forklare Salg (y) vha. Reklamebudget (x). Statistisk model: Vi antager at sammenhængen
Test og sammenligning af udvalgte regressionsmodeller Berit Christina Olsen forår 2008
 Indholdsfortegnelse 1 INDLEDNING OG PROBLEMSTILLING... 2 1.1 OVERVÆGT SOM CASE... 2 2 ANALYSEFORBEREDELSER... 4 2.1 HEPRO-UNDERSØGELSEN... 4 2.2 DEN AFHÆNGIGE VARIABEL VIGTIGHED AF ÆNDRINGEN AF VÆGT...
Indholdsfortegnelse 1 INDLEDNING OG PROBLEMSTILLING... 2 1.1 OVERVÆGT SOM CASE... 2 2 ANALYSEFORBEREDELSER... 4 2.1 HEPRO-UNDERSØGELSEN... 4 2.2 DEN AFHÆNGIGE VARIABEL VIGTIGHED AF ÆNDRINGEN AF VÆGT...
To samhørende variable
 To samhørende variable Statistik er tal brugt som argumenter. - Leonard Louis Levinsen Antagatviharn observationspar x 1, y 1,, x n,y n. Betragt de to tilsvarende variable x og y. Hvordan måles sammenhængen
To samhørende variable Statistik er tal brugt som argumenter. - Leonard Louis Levinsen Antagatviharn observationspar x 1, y 1,, x n,y n. Betragt de to tilsvarende variable x og y. Hvordan måles sammenhængen
Simpel og multipel logistisk regression
 Faculty of Health Sciences Logistisk regression Simpel og multipel logistisk regression 16. Maj 2012 Analyse af en binær responsvariabel. syg/rask, død/levende, ja/nej... Ud fra en eller flere forklarende
Faculty of Health Sciences Logistisk regression Simpel og multipel logistisk regression 16. Maj 2012 Analyse af en binær responsvariabel. syg/rask, død/levende, ja/nej... Ud fra en eller flere forklarende
Overlevelse efter AMI. Hvilken betydning har følgende faktorer for risikoen for ikke at overleve: Køn og alder betragtes som confoundere.
 Overlevelse efter AMI Hvilken betydning har følgende faktorer for risikoen for ikke at overleve: Diabetes VF (Venticular fibrillation) WMI (Wall motion index) CHF (Cardiac Heart Failure) Køn og alder betragtes
Overlevelse efter AMI Hvilken betydning har følgende faktorer for risikoen for ikke at overleve: Diabetes VF (Venticular fibrillation) WMI (Wall motion index) CHF (Cardiac Heart Failure) Køn og alder betragtes
Oversigt. 1 Motiverende eksempel: Højde-vægt. 2 Lineær regressionsmodel. 3 Mindste kvadraters metode (least squares)
") Kursus 02402/02323 Introducerende Statistik Forelæsning 8: Simpel lineær regression Oversigt Motiverende eksempel: Højde-vægt 2 Lineær regressionsmodel 3 Mindste kvadraters metode (least squares) Klaus
Kursus 02402/02323 Introducerende Statistik Forelæsning 8: Simpel lineær regression Oversigt Motiverende eksempel: Højde-vægt 2 Lineær regressionsmodel 3 Mindste kvadraters metode (least squares) Klaus
1. Lav en passende arbejdstegning, der illustrerer samtlige enkeltobservationer.
 Vejledende besvarelse af hjemmeopgave Basal statistik, efterår 2008 En gruppe bestående af 45 patienter med reumatoid arthrit randomiseres til en af 6 mulige behandlinger, nemlig placebo, aspirin eller
Vejledende besvarelse af hjemmeopgave Basal statistik, efterår 2008 En gruppe bestående af 45 patienter med reumatoid arthrit randomiseres til en af 6 mulige behandlinger, nemlig placebo, aspirin eller
Anvendt Statistik Lektion 8. Multipel Lineær Regression
 Anvendt Statistik Lektion 8 Multipel Lineær Regression 1 Simpel Lineær Regression (SLR) y Sammenhængen mellem den afhængige variabel (y) og den forklarende variabel (x) beskrives vha. en SLR: ligger ikke
Anvendt Statistik Lektion 8 Multipel Lineær Regression 1 Simpel Lineær Regression (SLR) y Sammenhængen mellem den afhængige variabel (y) og den forklarende variabel (x) beskrives vha. en SLR: ligger ikke
1 Hb SS Hb Sβ Hb SC = , (s = )
") PhD-kursus i Basal Biostatistik, efterår 2006 Dag 6, onsdag den 11. oktober 2006 Eksempel 9.1: Hæmoglobin-niveau og seglcellesygdom Data: Hæmoglobin-niveau (g/dl) for 41 patienter med en af tre typer seglcellesygdom.
PhD-kursus i Basal Biostatistik, efterår 2006 Dag 6, onsdag den 11. oktober 2006 Eksempel 9.1: Hæmoglobin-niveau og seglcellesygdom Data: Hæmoglobin-niveau (g/dl) for 41 patienter med en af tre typer seglcellesygdom.
Program. Logistisk regression. Eksempel: pesticider og møl. Odds og odds-ratios (igen)
") Faculty of Life Sciences Program Logistisk regression Claus Ekstrøm E-mail: [email protected] Odds og odds-ratios igen Logistisk regression Estimation og inferens Modelkontrol Slide 2 Statistisk Dataanalyse
Faculty of Life Sciences Program Logistisk regression Claus Ekstrøm E-mail: [email protected] Odds og odds-ratios igen Logistisk regression Estimation og inferens Modelkontrol Slide 2 Statistisk Dataanalyse
Basal Statistik - SPSS
 Faculty of Health Sciences Basal Statistik - SPSS Kovariansanalyse. Lene Theil Skovgaard 1. oktober 2018 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Bland-Altman plot,
Faculty of Health Sciences Basal Statistik - SPSS Kovariansanalyse. Lene Theil Skovgaard 1. oktober 2018 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Bland-Altman plot,
Logistisk Regression - fortsat
 Logistisk Regression - fortsat Likelihood Ratio test Generel hypotese test Modelanalyse Indtil nu har vi set på to slags modeller: 1) Generelle Lineære Modeller Kvantitav afhængig variabel. Kvantitative
Logistisk Regression - fortsat Likelihood Ratio test Generel hypotese test Modelanalyse Indtil nu har vi set på to slags modeller: 1) Generelle Lineære Modeller Kvantitav afhængig variabel. Kvantitative
Program. 1. Varianskomponent-modeller (Random Effects) 2. Transformation af data. 1/12
 2. Transformation af data. 1/12") Program 1. Varianskomponent-modeller (Random Effects) 2. Transformation af data. 1/12 Dæktyper og brændstofforbrug Data fra opgave 10.43, side 360: cars 1 2 3 4 5... radial 4.2 4.7 6.6 7.0 6.7... belt
Program 1. Varianskomponent-modeller (Random Effects) 2. Transformation af data. 1/12 Dæktyper og brændstofforbrug Data fra opgave 10.43, side 360: cars 1 2 3 4 5... radial 4.2 4.7 6.6 7.0 6.7... belt
Løsning til opgave i logistisk regression
 Løsning til øvelser i logistisk regression, november 2008 1 Løsning til opgave i logistisk regression 1. Først indlæses data, og vi kan lige sørge for at danne en dummy-variable for cml, som indikator
Løsning til øvelser i logistisk regression, november 2008 1 Løsning til opgave i logistisk regression 1. Først indlæses data, og vi kan lige sørge for at danne en dummy-variable for cml, som indikator
Statistik Lektion 16 Multipel Lineær Regression
 Statistik Lektion 6 Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk
Statistik Lektion 6 Multipel Lineær Regression Trin i opbygningen af en statistisk model Repetition af MLR fra sidst Modelkontrol Prædiktion Kategoriske forklarende variable og MLR Opbygning af statistisk
Logistisk regression
 Logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] 21. marts 2013 Dagens program Chi-i-anden (χ 2 )-testet Sandsynligheder,
Logistisk regression Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] 21. marts 2013 Dagens program Chi-i-anden (χ 2 )-testet Sandsynligheder,
Besvarelse af opgave om Vital Capacity
 Besvarelse af opgave om Vital Capacity I filen cadmium.txt ligger observationer fra et eksempel omhandlende lungefunktionen hos arbejdere i cadmium industrien (hentet fra P. Armitage & G. Berry: Statistical
Besvarelse af opgave om Vital Capacity I filen cadmium.txt ligger observationer fra et eksempel omhandlende lungefunktionen hos arbejdere i cadmium industrien (hentet fra P. Armitage & G. Berry: Statistical
Faculty of Health Sciences. Logistisk regression: Kvantitative forklarende variable
 Faculty of Health Sciences Logistisk regression: Kvantitative forklarende variable Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Sammenhæng
Faculty of Health Sciences Logistisk regression: Kvantitative forklarende variable Susanne Rosthøj Biostatistisk Afdeling Institut for Folkesundhedsvidenskab Københavns Universitet [email protected] Sammenhæng
Dagens Temaer. Test for lineær regression. Test for lineær regression - via proc glm. k normalfordelte obs. rækker i proc glm. p. 1/??
 Dagens Temaer k normalfordelte obs. rækker i proc glm. Test for lineær regression Test for lineær regression - via proc glm p. 1/?? Proc glm Vi indlæser data i datasættet stress, der har to variable: areal,
Dagens Temaer k normalfordelte obs. rækker i proc glm. Test for lineær regression Test for lineær regression - via proc glm p. 1/?? Proc glm Vi indlæser data i datasættet stress, der har to variable: areal,
Besvarelse af opgavesættet ved Reeksamen forår 2008
 Besvarelse af opgavesættet ved Reeksamen forår 2008 10. marts 2008 1. Angiv formål med undersøgelsen. Beskriv kort hvordan cases og kontroller er udvalgt. Vurder om kontrolgruppen i det aktuelle studie
Besvarelse af opgavesættet ved Reeksamen forår 2008 10. marts 2008 1. Angiv formål med undersøgelsen. Beskriv kort hvordan cases og kontroller er udvalgt. Vurder om kontrolgruppen i det aktuelle studie
Module 4: Ensidig variansanalyse
 Module 4: Ensidig variansanalyse 4.1 Analyse af én stikprøve................. 1 4.1.1 Estimation.................... 3 4.1.2 Modelkontrol................... 4 4.1.3 Hypotesetest................... 6 4.2
Module 4: Ensidig variansanalyse 4.1 Analyse af én stikprøve................. 1 4.1.1 Estimation.................... 3 4.1.2 Modelkontrol................... 4 4.1.3 Hypotesetest................... 6 4.2
Program. Sammenligning af grupper Ensidet ANOVA. Case 3, del II: Fiskesmag i lammekød. Case 3, del I: A-vitamin i leveren
 Faculty of Life Sciences Program Sammenligning af grupper Ensidet ANOVA Claus Ekstrøm E-mail: [email protected] Sammenligning af to grupper: tre eksempler Sammenligning af mere end to grupper: ensidet
Faculty of Life Sciences Program Sammenligning af grupper Ensidet ANOVA Claus Ekstrøm E-mail: [email protected] Sammenligning af to grupper: tre eksempler Sammenligning af mere end to grupper: ensidet
Morten Frydenberg 14. marts 2006
 Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik 1 RESUME: 2 2. gang: 2006 Institut for Biostatistik, Århus Universitet MPH 1. studieår Specialmodul 4 Cand. San. uddannelsen
Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik 1 RESUME: 2 2. gang: 2006 Institut for Biostatistik, Århus Universitet MPH 1. studieår Specialmodul 4 Cand. San. uddannelsen
Eksempel Multipel regressions model Den generelle model Estimation Multipel R-i-anden F-test for effekt af prædiktorer Test for vekselvirkning
 1 Multipel regressions model Eksempel Multipel regressions model Den generelle model Estimation Multipel R-i-anden F-test for effekt af prædiktorer Test for vekselvirkning PSE (I17) ASTA - 11. lektion
1 Multipel regressions model Eksempel Multipel regressions model Den generelle model Estimation Multipel R-i-anden F-test for effekt af prædiktorer Test for vekselvirkning PSE (I17) ASTA - 11. lektion
Det kunne godt se ud til at ikke-rygere er ældre. Spredningen ser ud til at være nogenlunde ens i de to grupper.
 1. Indlæs data. * HUSK at angive din egen placering af filen; data framing; infile '/home/sro00/mph2016/framing.txt' firstobs=2; input id sex age frw sbp sbp10 dbp chol cig chd yrschd death yrsdth cause;
1. Indlæs data. * HUSK at angive din egen placering af filen; data framing; infile '/home/sro00/mph2016/framing.txt' firstobs=2; input id sex age frw sbp sbp10 dbp chol cig chd yrschd death yrsdth cause;
Basal Statistik - SPSS
 Faculty of Health Sciences Basal Statistik - SPSS Kovariansanalyse. Lene Theil Skovgaard 3. oktober 2017 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Bland-Altman plot,
Faculty of Health Sciences Basal Statistik - SPSS Kovariansanalyse. Lene Theil Skovgaard 3. oktober 2017 1 / 12 APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Bland-Altman plot,
Vi vil analysere effekten af rygning og alkohol på chancen for at blive gravid ved at benytte forskellige Cox regressions modeller.
 Løsning til øvelse i TTP dag 3 Denne øvelse omhandler tid til graviditet. Et studie vedrørende tid til graviditet (Time To Pregnancy = TTP) inkluderede 423 par i alderen 20-35 år. Parrene blev fulgt i
Løsning til øvelse i TTP dag 3 Denne øvelse omhandler tid til graviditet. Et studie vedrørende tid til graviditet (Time To Pregnancy = TTP) inkluderede 423 par i alderen 20-35 år. Parrene blev fulgt i
1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ
 - sammenligning af flere grupper(kvalitativ") Indhold 1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) 2 1.1 Variation indenfor og mellem grupper.......................... 2 1.2 F-test for ingen
Indhold 1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) 2 1.1 Variation indenfor og mellem grupper.......................... 2 1.2 F-test for ingen
Faculty of Health Sciences. Regressionsanalyse. Simpel lineær regression, Lene Theil Skovgaard. Biostatistisk Afdeling
 Faculty of Health Sciences Regressionsanalyse Simpel lineær regression, 28-2-2013 Lene Theil Skovgaard Biostatistisk Afdeling 1 / 67 Simpel lineær regression Regression og korrelation Simpel lineær regression
Faculty of Health Sciences Regressionsanalyse Simpel lineær regression, 28-2-2013 Lene Theil Skovgaard Biostatistisk Afdeling 1 / 67 Simpel lineær regression Regression og korrelation Simpel lineær regression
Morten Frydenberg 26. april 2004
 Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik RESUME: 2 2. gang: 2002 Institut for Biostatistik, Århus Universitet MPH. studieår Specialmodul 4 Cand. San. uddannelsen.
Introduktion til Logistisk Regression Morten Frydenberg, Inst. f. Biostatistik RESUME: 2 2. gang: 2002 Institut for Biostatistik, Århus Universitet MPH. studieår Specialmodul 4 Cand. San. uddannelsen.
Basal Statistik. Simpel lineær regression. Problemstillinger ved multipel regression. Multipel regression. Faculty of Health Sciences
 Faculty of Health Sciences Simpel lineær regression Basal Statistik Multipel regressionsanalyse. Lene Theil Skovgaard 10. oktober 2017 Multipel regression Regression med to kvantitative kovariater: Eksempel
Faculty of Health Sciences Simpel lineær regression Basal Statistik Multipel regressionsanalyse. Lene Theil Skovgaard 10. oktober 2017 Multipel regression Regression med to kvantitative kovariater: Eksempel
grupper(kvalitativ exposure) Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen
 Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen") 1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen
1 Ensidet variansanalyse(kvantitativt outcome) - sammenligning af flere grupper(kvalitativ exposure) Variation indenfor og mellem grupper F-test for ingen effekt AnovaTabel Beregning af p-værdi i F-fordelingen
Kursus i varians- og regressionsanalyse Data med detektionsgrænse. Birthe Lykke Thomsen H. Lundbeck A/S
 Kursus i varians- og regressionsanalyse Data med detektionsgrænse Birthe Lykke Thomsen H. Lundbeck A/S 1 Data med detektionsgrænse Venstrecensurering: Baggrundsstøj eller begrænsning i måleudstyrets følsomhed
Kursus i varians- og regressionsanalyse Data med detektionsgrænse Birthe Lykke Thomsen H. Lundbeck A/S 1 Data med detektionsgrænse Venstrecensurering: Baggrundsstøj eller begrænsning i måleudstyrets følsomhed
Opgavebesvarelse, logistisk regression
 Opgavebesvarelse, logistisk regression Data ligger i rop.xls på kursushjemmesiden: http://staff.pubhealth.ku.dk/ jufo/courses/logistic/ Når du har gemt data på din computer, kan det indlæses i SAS med
Opgavebesvarelse, logistisk regression Data ligger i rop.xls på kursushjemmesiden: http://staff.pubhealth.ku.dk/ jufo/courses/logistic/ Når du har gemt data på din computer, kan det indlæses i SAS med
Basal Statistik - SPSS
 Faculty of Health Sciences APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Basal Statistik - SPSS Den generelle lineære model. Lene Theil Skovgaard 24. oktober 2017 Biokemisk iltforbrug,
Faculty of Health Sciences APPENDIX med instruktioner til SPSS-analyse svarende til nogle af slides Basal Statistik - SPSS Den generelle lineære model. Lene Theil Skovgaard 24. oktober 2017 Biokemisk iltforbrug,